
昨日合并到 FFmpeg Git 的一些提交为 AVX-512 和英特尔与 AMD 处理器提供了额外的手工调整汇编代码。
开源多媒体开发人员 Niklas Haas 昨日向 FFmpeg 上游提交了一些额外的 AVX2 和 AVX-512 调整代码,在此基础上,该多媒体库已经有了大量的手工调整代码,以利用高级矢量扩展。
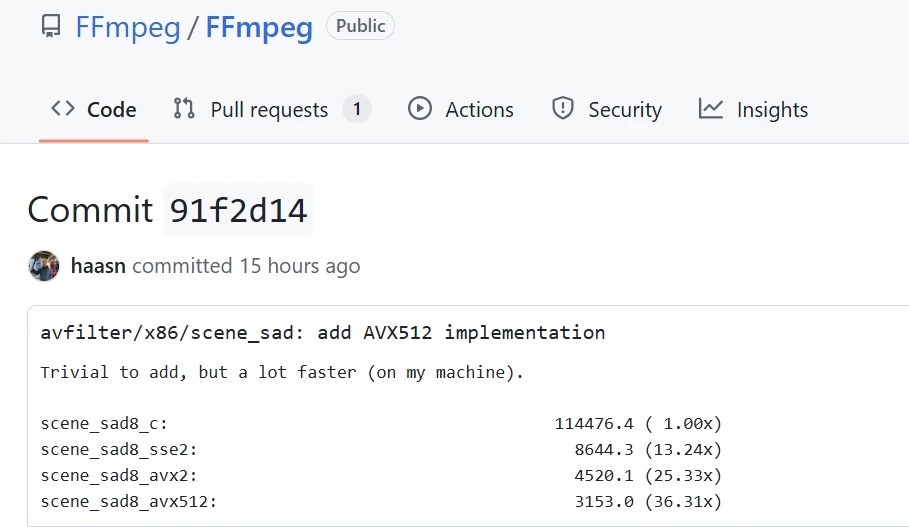
根据 Niklas Haas 的基准测试,FFmpeg 的 avfilter scene_sad 代码现在增加了 AVX-512 实现,速度是普通 C 代码的 36.31 倍。AVX2 路径的性能已经是普通 C 代码的 25 倍,而 AVX-512 的性能则超过了 36 倍。

另一次提交添加了高位深度 AVX2 和 AVX-512 版本的 scene_sad avfilter 代码。与普通 C 代码相比,性能提升了约 11 倍,使用 AVX-512 时则提升了约 22 倍。
AVX-512 持续带来收益,尤其是在最新的 AMD Zen 4/Zen 5 和近期推出的 Intel Xeon 处理器上。
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/zixun/59859.html