
本次介绍关于帧间快速算法的两篇论文,主要针对VVC标准,缓解VVC中复杂划分和编码带来的巨大复杂度提升,一篇是使用CNN实现,另一篇使用随机森林实现。


首先介绍一篇发表于2021 SPL的论文,其标题是《A CNN-Based Fast Inter Coding Method for VVC》。为了降低VVC中帧间编码的复杂度,本文提出了一种多信息融合网络用以判决划分,然后根据网络输出结果和预测信息实现Merge模式的提前确定,在编码时间复杂度和编码性能上取得了较好的trade-off。

首先简单介绍一下背景。编码标准从HEVC发展到VVC,编码性能大大提升,但是复杂度变得非常高,复杂度的最大来源是块划分,具体来说是更复杂度的划分类型(即QTMT)以及更大的允许划分尺寸范围(128~4)。这对帧内和帧间编码都有很大的影响,因此如果能够快速判决块划分会非常有效地降低帧内复杂度。另外VVC标准在帧间提出很多新的工具,除了常规的Merge模式,还有AMVP、几乎划分预测、仿射等等,性能上升的同时也大大增加了复杂度,如果能跳过部分模式会节约大量时间。
近些年提出的快速算法大致上可以分成两类,一类是基于统计分析的方法,这类方法还可以继续细分,例如传统的拟合、机器学习等,也取得了不错的结果,但是实际的效果还是依赖于研究者手动挑选的特征,一部分是依赖于经验的,并非最优。第二类是基于CNN的方法,这类方法利用CNN自动提取像素特征的优点,但是目前基本还是集中在帧内预测的快速算法中,因为CNN难以提取到时域上的信息。

本文的贡献一共有以下几点:一是提出了一种基于CNN的帧间快速编码方法,首次在VVC帧间使用深度学习来降低复杂度。二是提出了多信息融合CNN网络(MF-CNN),提取来自于亮度值、残差值、运动场的特征以判决划分概率。三是设计了一种提前确定Merge模式,减少帧间预测模式的遍历。最后的性能是30.63%的复杂度降低,带来了3%的BD-rate上升。
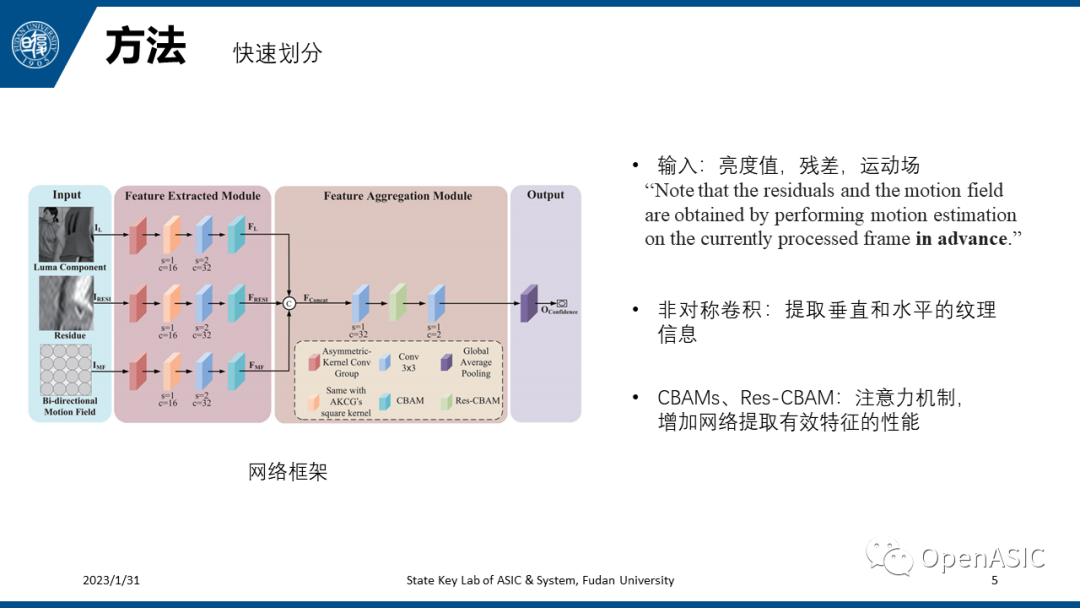
论文分为两部分,首先介绍第一部分快速划分算法。如左图所示为本文提出的主干网络,网络的输入是亮度值,残差值以及运动场,输出的是划分的概率。需要注意的是,这里的残差值和运动场都是提前计算好的。虽然论文中没有明确说明计算方法,但是大概率应该是提前计算固定尺寸的块的运动矢量和预测残差。另外这个网络还使用了一些已经在其它相关论文中证明有效的结构,例如非对称卷积,使用长宽比不为1的卷积核进行卷积并将特征图进行融合,用以有针对性地提取垂直和水平地纹理信息。例如CBAMs以及Res-CBAM,这两个都是注意力模块,用以增加网络提取有效特征的性能。
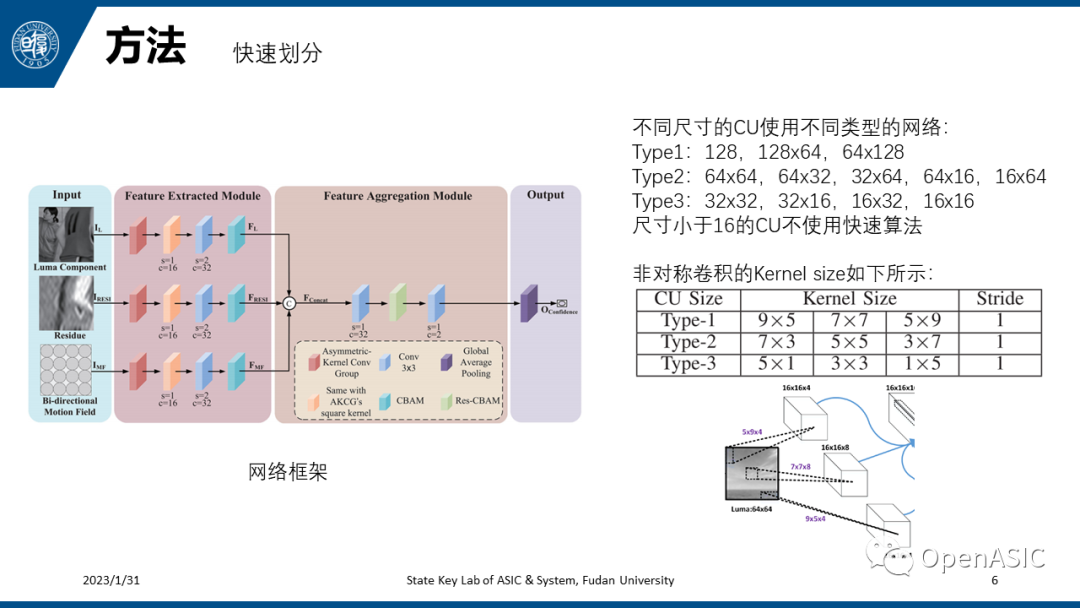
为了降低网络训练的难度,这里给不同尺寸的CU使用了不同类型的网络,如下所示,其中尺寸小于16的CU不使用快速算法,编码质量容易大打折扣。对于不同类型的网络,使用的非对称卷积的kernel size也不一样,如下表所示。原始论文中的非对称卷积如由下图所示,对应本文中的Type-1网络。

损失函数考虑了两个方面,一是常规的预测准确度,使用基本的交叉熵函数就可以;二是错误预测带来的RD-cost偏差,假设两次的划分都预测错误了,但是对BD-rate的影响可能大不一样,因此需要对RD-cost影响大的错误划分施加更大的惩罚。
具体的损失函数如下式所示。其中yi_hat是预测值,yi是ground_truth。r1是不划分的最小RD-cost,r2是划分的最小RD-cost,rmin是r1和r2的较小值。由于输出的概率只有一个,所以本文只需要考虑一个阈值即可,从0.8到1,以step为0.05进行遍历测试。最终选择当Cu size为128×128是阈值设为1,其它size阈值设为0.95。
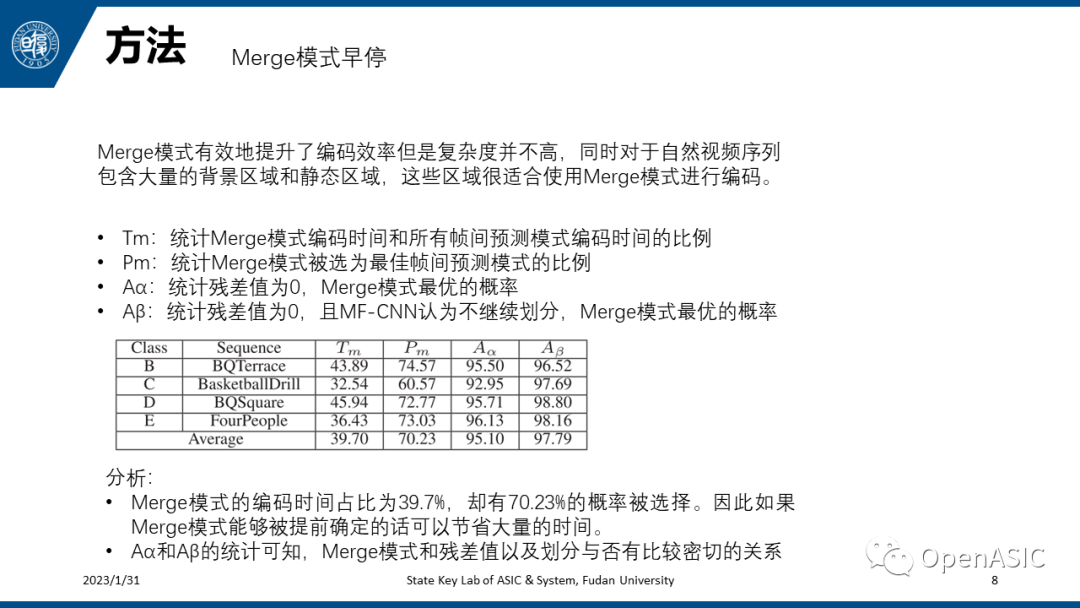
接下来介绍本文的第二部分,Merge模式的早停。无论是HEVC还是VVC标准,都引入Merge模式,Merge模式有效地提升了编码效率但是其复杂度并不高,同时对于自然视频序列来说其中包含大量的背景区域和静态区域,这些区域很适合使用Merge模式进行编码。作者对一部分序列进行统计分析,如下表所示。通过分析可以,Merge模式的编码时间占比为39.7%,却有70.23%的概率被选择。因此如果Merge模式能够被提前确定的话可以节省大量的时间。另外从Aα和Aβ的统计可知,Merge模式和残差值以及划分与否有比较密切的关系。
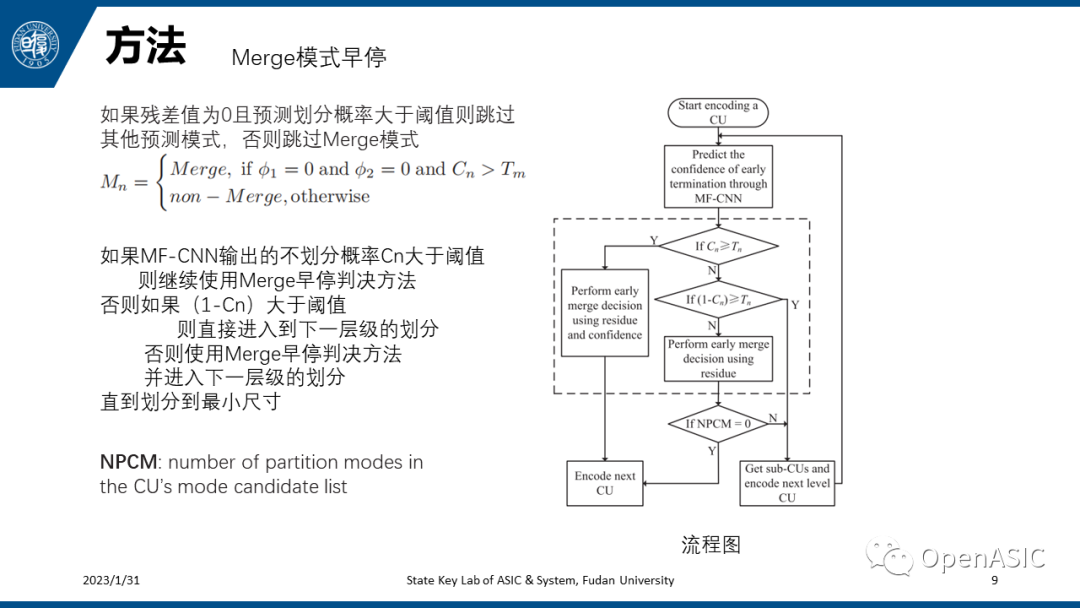
Merge模式早停的方法比较简单:如果残差值为0且预测划分概率大于阈值则跳过其他预测模式,否则跳过Merge模式,如下式所示。右图给出整个帧间编码的流程图。
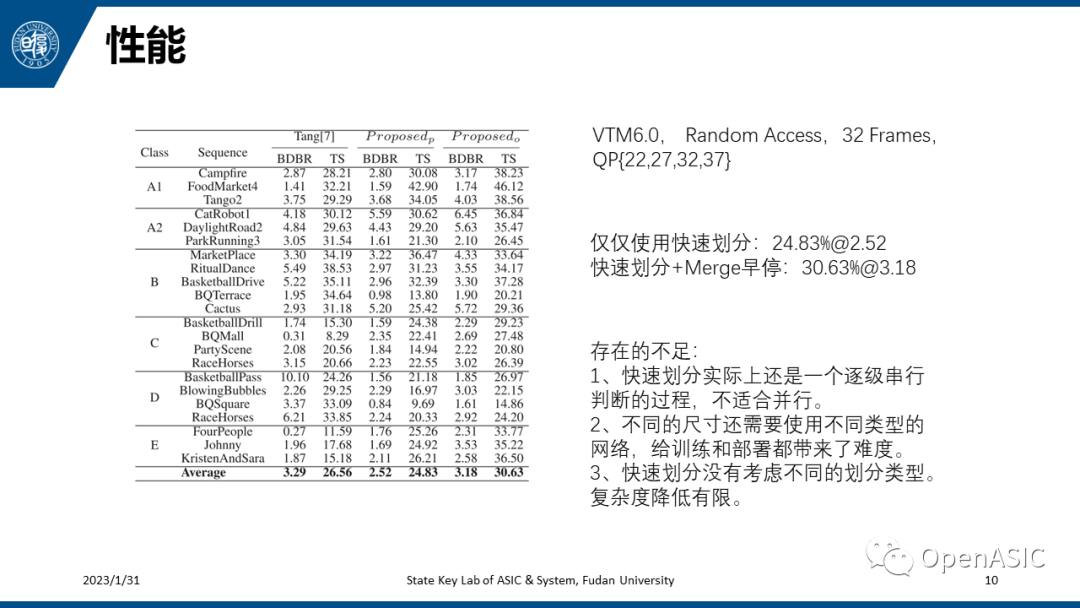
性能如下表所示。测试在VTM6.0上进行,使用Random Access编码,一共编码32帧,采用four QP编码并计算编码时间和BDBR。如果仅仅使用快速划分,性能为24.83%@2.52,如果同时使用快速划分+Merge早停,性能为30.63%@3.18。本文还存在一些不足,如下所示。
下面介绍一篇发表于2020年TIP的论文,该文使用机器学习的方法来加速帧间编码块划分过程。

本文分别在JEM-7.0和VTM-5.0上都进行了测试,性能相近。两种参考软件的块划分类型略有区别,前者使用QTBT,后者增加了三叉树划分TTH和TTV,也就是我们常说的QTMT,两种实现在特征选取时没有区别,仅仅是在分类器的设计上有区别,后面会详细介绍。本文使用随机森林进行训练,需要手动挑选特征,在挑选的过程中需要关注互信息这一概念,这是挑选特征时的关键指标。最后,需要了解编码参数配置中的BTdepth和MTdepth,本文中会调节这两个超参数进一步灵活地调节编码复杂度。
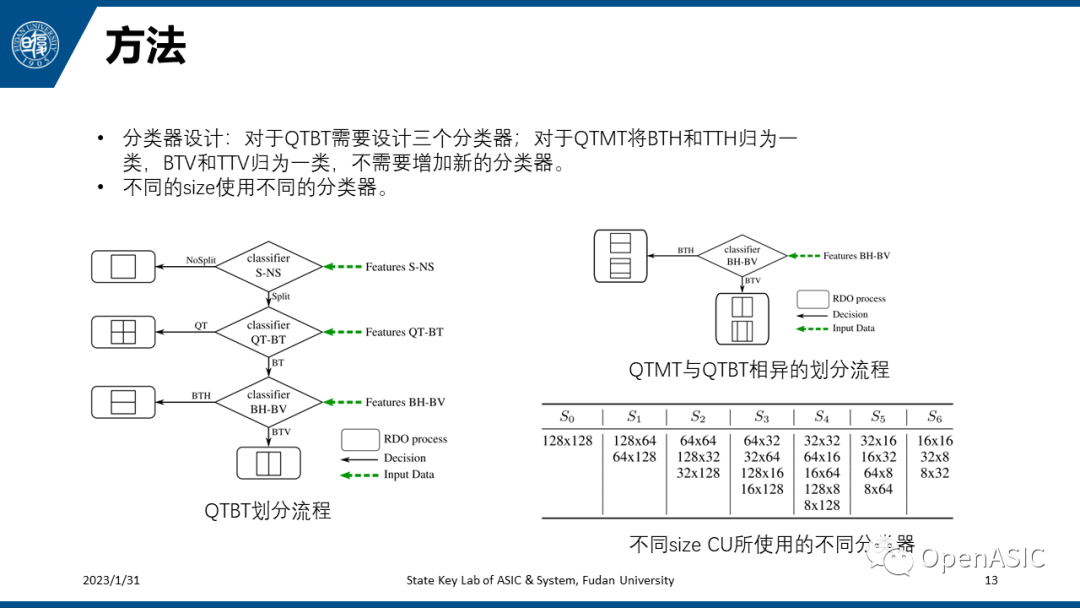
在JEM中的QTBT划分测试下,本文将一个多分类问题转变为三个二分类问题,设计了一套包含了三个分类器的判决流程,如左图所示。对于VTM中的QTMT,本文并没有设计新的分类器,BH-BV分类器的每一类输出都是水平或者都是垂直划分,兼容了TTH和TTV两种新的划分。另外,本文为不同的Cu size都设计了不同的分类器,一共有7类,如右表所示。
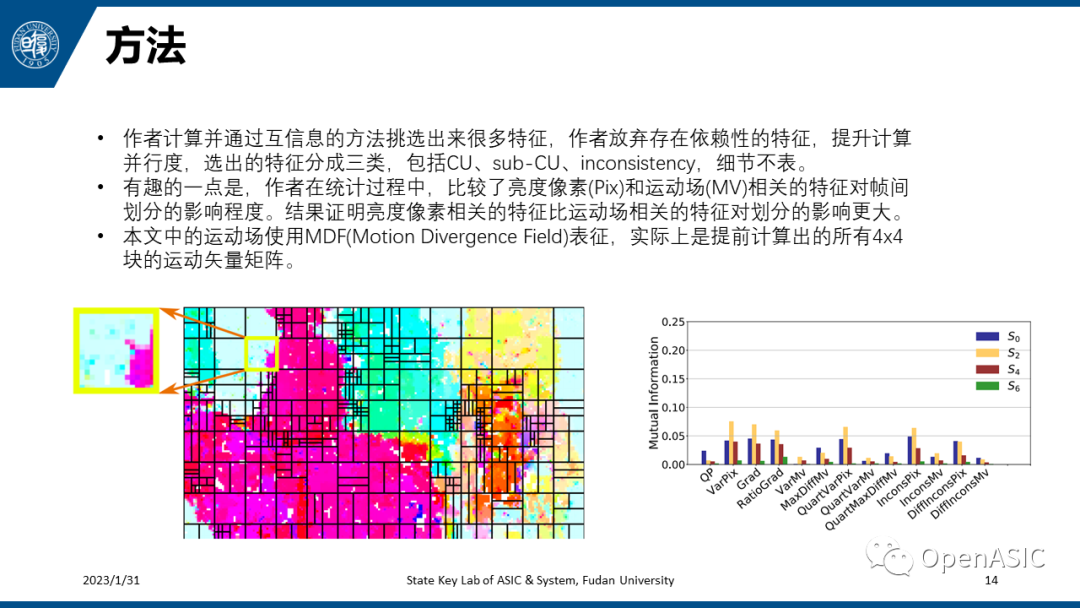
重点在于如何为分类器挑选出合适的特征,作者主要参考互信息的指标进行挑选,总共挑选出三类特征,每种分类器有不同的特征,约20种左右。经过实验比较,亮度像素相关的特征比运动场相关的特征对帧间划分的影响更大。这里的运动场使用MDF表征,是提前计算出的所有4×4块的运动矢量矩阵。MDF这一部分计算可大约占0.8%的复杂度,但是目前很多编码器如X265等支持look-ahead技术,这一部分计算可以放在look-ahead中,因此不需要进行额外的代价。
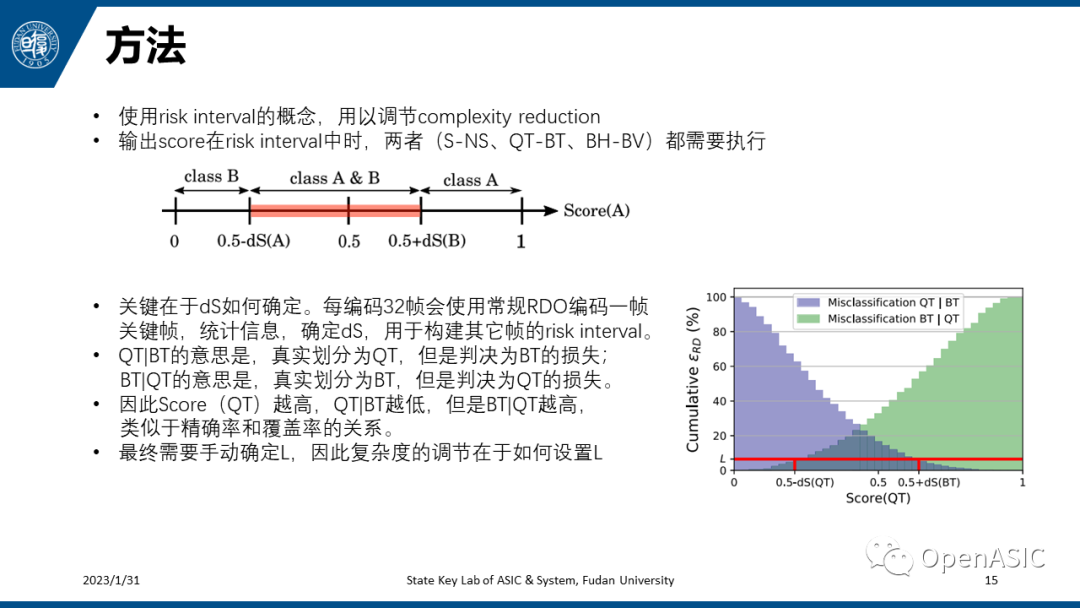
本文的亮点除了特征选取外,就是如何灵活地进行复杂度调节。作者引入了risk interval的概念。这里的Score是随机森林综合计算出的一个分数,对于一个输出结果为A和B的分类器来说,Score(A)+Score(B)=1,两者的范围都是0-1,这一点和二分类神经网络是相似的。如果输出score在risk interval中,则A和B都需要执行,否则执行A或者执行B,这样避免了编码质量的损失,但是复杂度降低也会更少。总之,risk interval和dS有关,而dS的值由关键帧的统计信息和手动设置的L决定,所以复杂度的调节最终在于如何设置L。
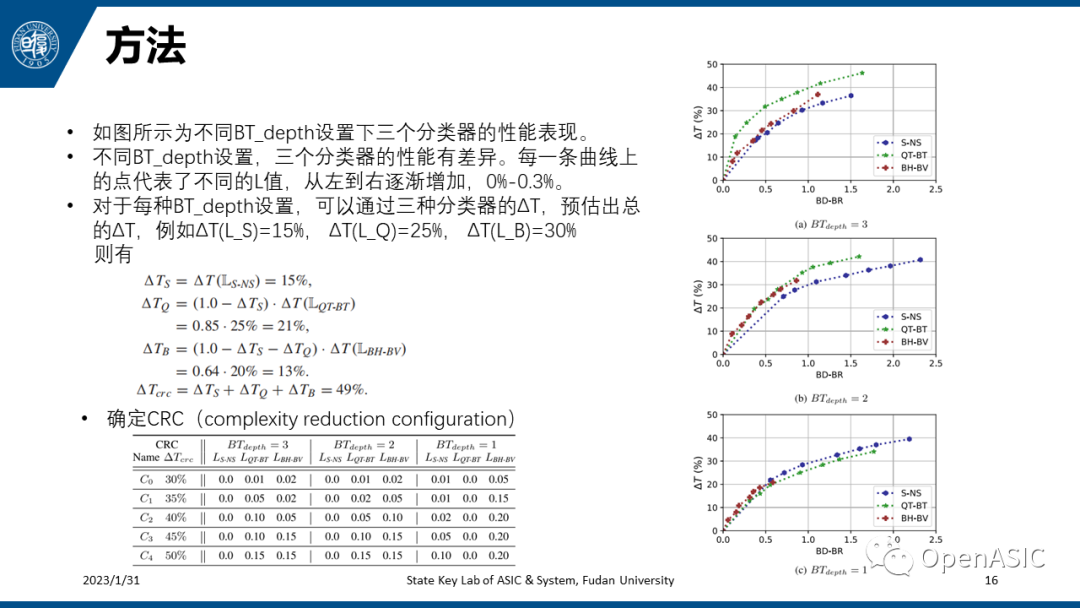
作者首先在三种不同的BTdepth下对每种分类器在不同的L值设置下的BD-BR和ΔT性能进行了统计,如右图所示。L值越大,则dS越小,则risk interval越小,因此时间复杂度降低得就越多。另外,从流程图的划分判决逻辑中,我们可以根据三种分类器的ΔT估计出总的ΔT,如下式给出的例子。因此,要想得到预估的ΔT,可以先分别确定每种分类器的ΔT,然后又可以通过ΔT从右图中估计出L值,最终形成下表,用于粗略预估计算复杂度减小。
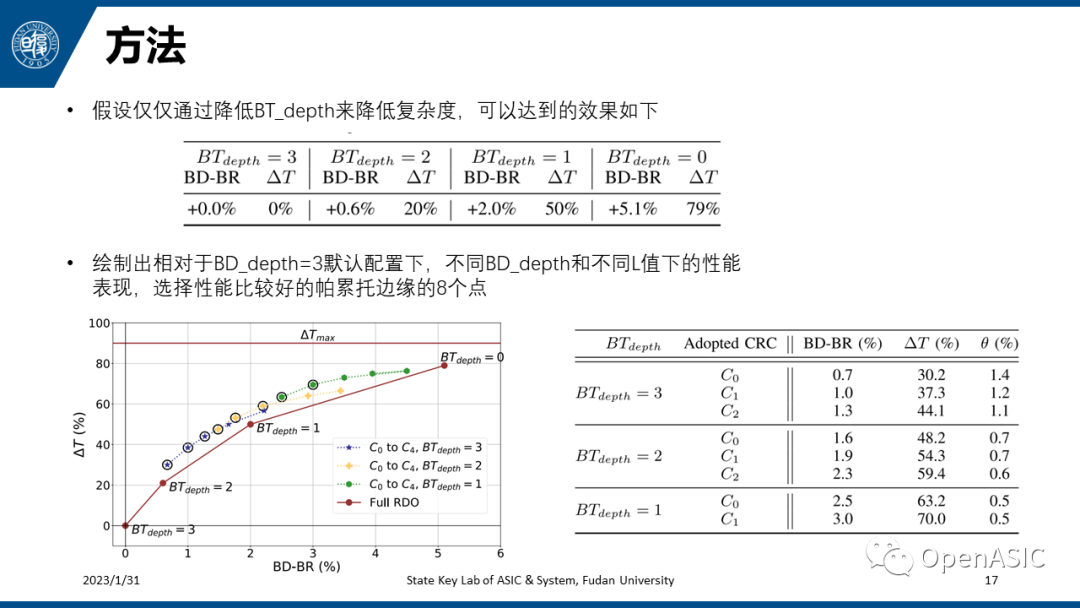
通过降低BTdepth来降低复杂度的性能可以作为一个baseline,某种方法如果它的性能都比不过,可以说这种方法基本是无效的。可以看到当BTdepth设置为2时,ΔT已经有20%,BD-BR增加0.6%;BTdepth设置为1时,ΔT为50%,BD-rate增加2.0%。然后绘制出一张总图,其中包含了三类BTdepth下的所有的C0-C4。
需要注意的是,这里所有的点都是和BD-depth为3的默认配置进行比较,所以前面的表中不同BTdepth下C0-C4的ΔT相近,而这张图里BTdepth越小相同的Cn的ΔT越高,高出来的这部分就是降低BTdepth带来的增益。最终选择了8种配置,如右表所示,这里的θ指的是本文中方法额外带来的时间增量,包括了特征计算和推理所用的时间。
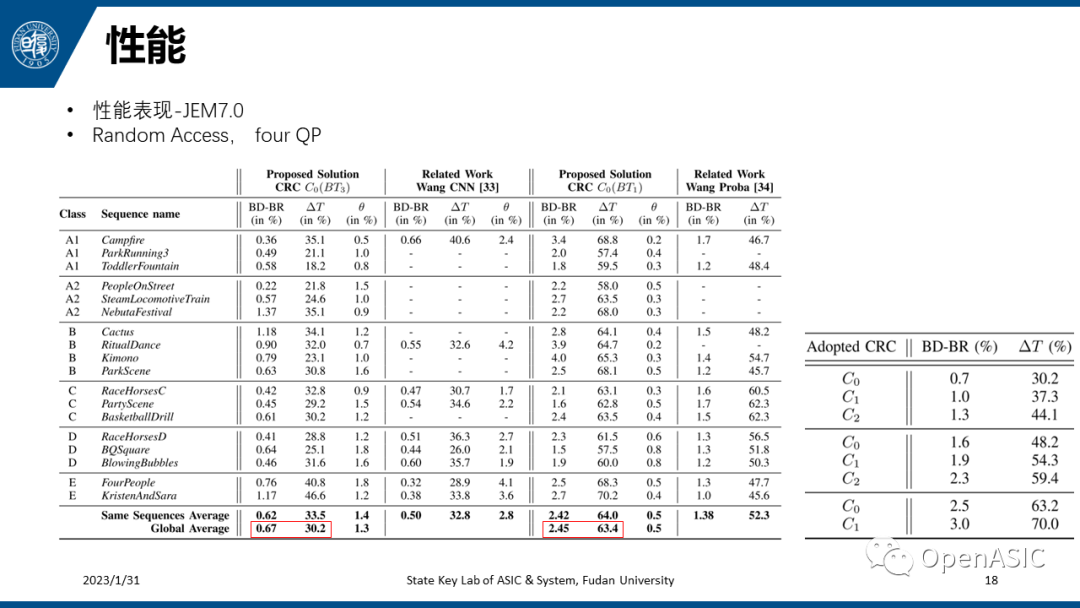
在JEM-7.0上的性能测试如下,C0(BT3)性能为30.2%@0.67,C0(BT1)性能为63.4%@2.45。和文献[33]性能相近,但是推理时间更短,[33]没有优化CNN实现。相比文献[34],单独在一个点上比较本文似乎更没有什么优势,只是本文更具有灵活性,复杂度可调节的范围很大。

和JEM一样的测试条件在VTM5.0上测试,因为分类器不一样,所以还需要根据左上图重新挑选配置,一共挑选了7种配置,性能如图所示。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。