
编者按:视频转码是视频相关领域中最重要的业务,需要消耗大量的算力。转码有解码和编码两个阶段,在编码中,运动矢量计算是消耗CPU算力最多的部分,因此要考虑如何减少大量的计算并提高图像质量。LiveVideoStack邀请到了英特尔的谢义老师,为我们介绍基于运动矢量重用的转码优化。
文/谢义
整理/LiveVideoStack
链接:https://mp.weixin.qq.com/s/509kJDHCtf0k9qPypwFrNA
大家好!我是谢义,来自英特尔亚太研发有限公司。我们团队主要负责基于至强服务器的软件优化工作,而服务器端的视频转码服务是我们重点关注的领域。英特尔奉行的原则是“水利万物而不争”,我们的初衷是协助合作厂商在英特尔服务器上获取最佳的视频转码性能。
依据客户真实需求,定制下一代CPU是我们的工作之一,我们选择做视频转码的另一个原因,是为了设计更好满足音视频领域需求的下一代硬件。所以今天还会给大家介绍下一代CPU中关于编解码的特殊指令,这些特殊指令可以加速编码效率。


今天,我分享的内容分为三个章节。首先,使用英特尔丰富的工具链对视频转码进行分析。我们作为硬件厂商,本身不做音视频转码业务,但俗话说“弄斧要到班门”,所以我们首先对视频转码的一些典型场景进行了微架构层面的分析,为后面的优化做好铺垫。然后,介绍方案的核心思想,即如何重用一次编码的信息来提高二次编码的效率。之前提到,计算复杂度在转码里占了很大的成本,所以要从源头上降低计算复杂度。最后,介绍SIMD指令集。SIMD的全称是Single Instruction Multiple Data,意思是单指令多数据,表明一条指令可以同时操作多个数据。
01 视频转码分析
首先,我们对视频转码进行分析。
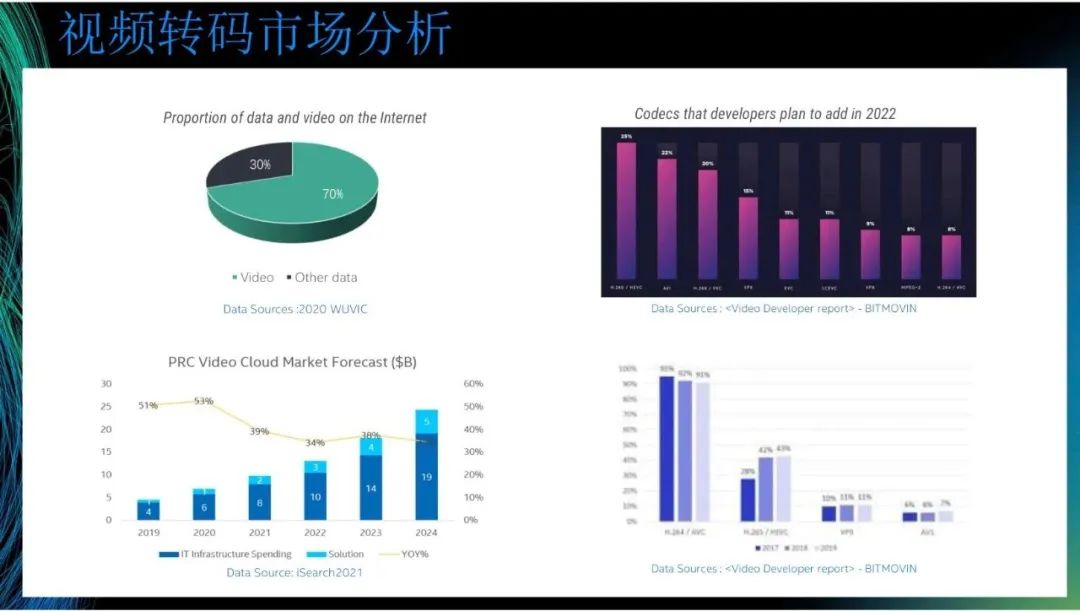
我们从相关市场获取了图中的数据。第一张图表示在2020年,视频数据在互联网数据占比70%。到现在,视频数据在互联网数据占比已超过80%。第二张图是PRC Video Cloud Market Forecast,图中呈增长趋势。虽然目前共有云市场的增速减缓,但是视频云的增长仍有很大潜力。回到转码本身,第三张图和第四张图来自Video Developer report。从第四张图可以看到,在2019年,H.264仍是主流视频编码技术,90%以上仍使用H.264。其次,较多使用的是H.265,然后是VP9和AV1,H.265也在逐渐成为一种趋势。第三张图表示视频编码器开发人员计划在2022年投入的情况。其中,投入最多的是H.265,然后是AV1,再然后是H.266,这三个协议正在成为主流编码器协议,我们后续将基于这些主流编码器进行开发。
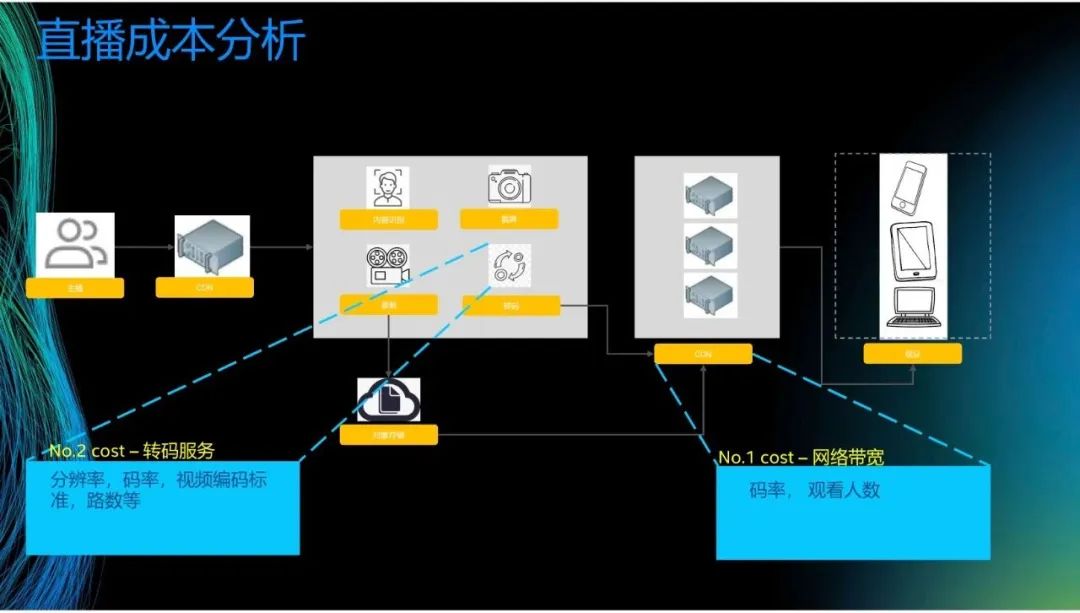
接下来进行直播成本分析。这是一张直播的结构图,主播上传内容到上行CDN,然后再发送到转码中心进行内容识别、截屏、录制和转码,接着再分发到下行CDN。这个过程中,成本最大的是网络带宽和转码服务器。之前提到,网络带宽取决于观看人数和码率。举个例子,观看2M的视频和观看500K的视频所需的网络带宽不同,1000个人同时观看视频和10个人同时观看视频所需的网络带宽也不同。转码服务取决于分辨率、码率和视频编码标准等。

我们对头部的互联网厂商进行了分析。如第一张图所示,主要有两个成本,一个是Traffic price,即带宽成本,另一个是转码成本。第二张图表示直播一小时内,转码和带宽的比例,图的横轴是观看人数,纵轴是转码和带宽费用的比例。可以看到,当观众数大于等于50时,带宽成为主要的成本。举个例子,顶级流量主播的一场直播的带宽成本要几百万,此时转码成本只有几千块,相对带宽成本几乎可以忽略。但对于数量众多的小主播来讲,观众数可能只有十几个,此时的带宽较低,所以转码成本成为主要的成本。针对这两种情况,在带宽成本较大时,我们以优化带宽为主,在转码成本较大时,我们以优化转码速度/转码性能为主。
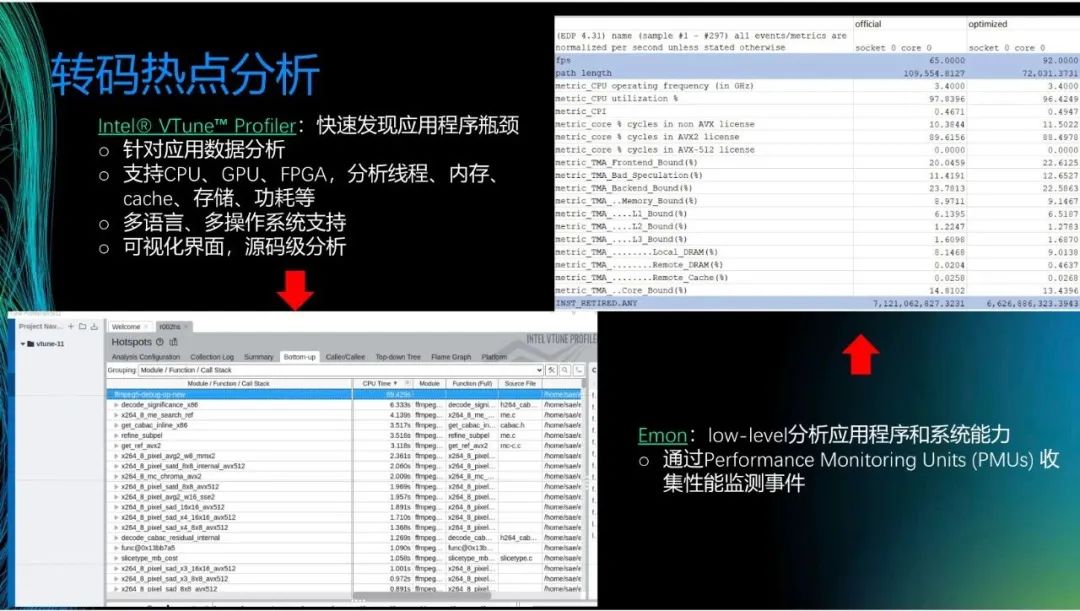
接下来,介绍几款好用的英特尔的工具。首先是V-Tune,是一个可以快速发现应用程序瓶颈的可视化的工具。左下图展示了一个例子,可以看到,我们可以知道转码里每个函数占用的CPU时间,双击就可进入code,精确定位哪行code的占比较高,所以可以清楚地知道热点函数在哪里。我们支持CPU、GPU和FPGA,也支持多语言和多操作系统。V-Tune的优点是直观,缺点是会为系统带来一定的负担。
另一个工具是Emon,其用于low-level层面的数据抓取。Emon的优点是可以直接抓取Performance Monitoring Units(PMUs),即寄存器的值,因此功率消耗较少。观察右上图,可以知道CPU的利用率、AVX指令集的使用比例,也可以知道该函数是Backend_Bound还是Frontend_Bound。因此,可以清楚知道系统的问题在哪里。
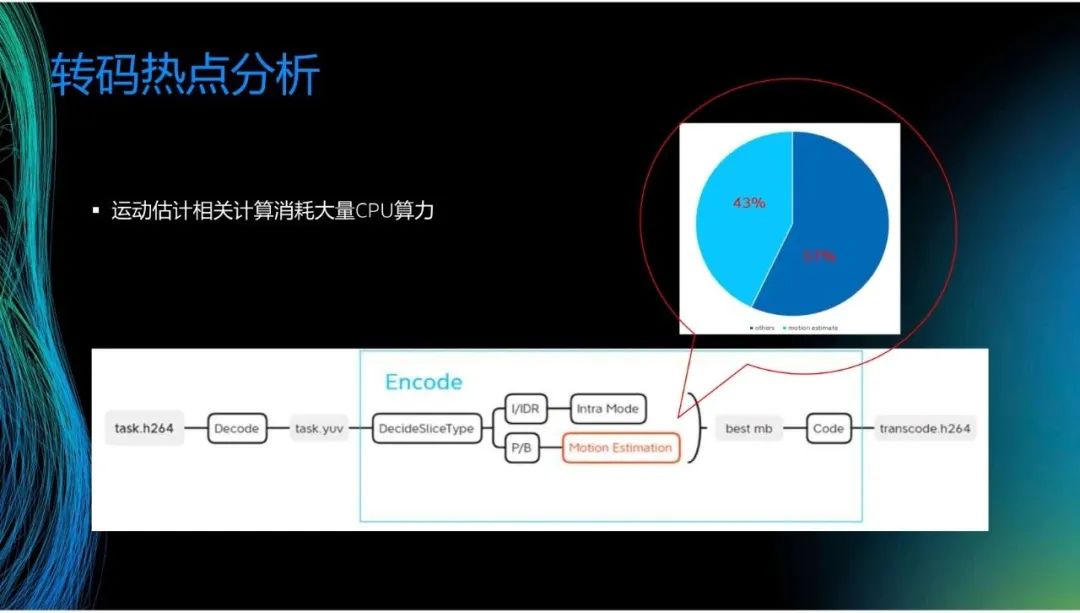
利用刚才介绍的工具,可以估计转码消耗的算力。可以看到,在某一个转码场景里,编码过程中的运动估计(Motion Estimation)占比超过40%,但不同的场景情况有所不同,举个例子,将8K的数据转换成360P的数据时,解码消耗的算力大于转码消耗的算力。在大部分情况下,若考虑帧决策等,运动估计的占比将超过50%,因此这成为了我们关注的热点。
02 重用运动矢量等信息提高转码效率和质量
接下来,介绍方案的核心思想。
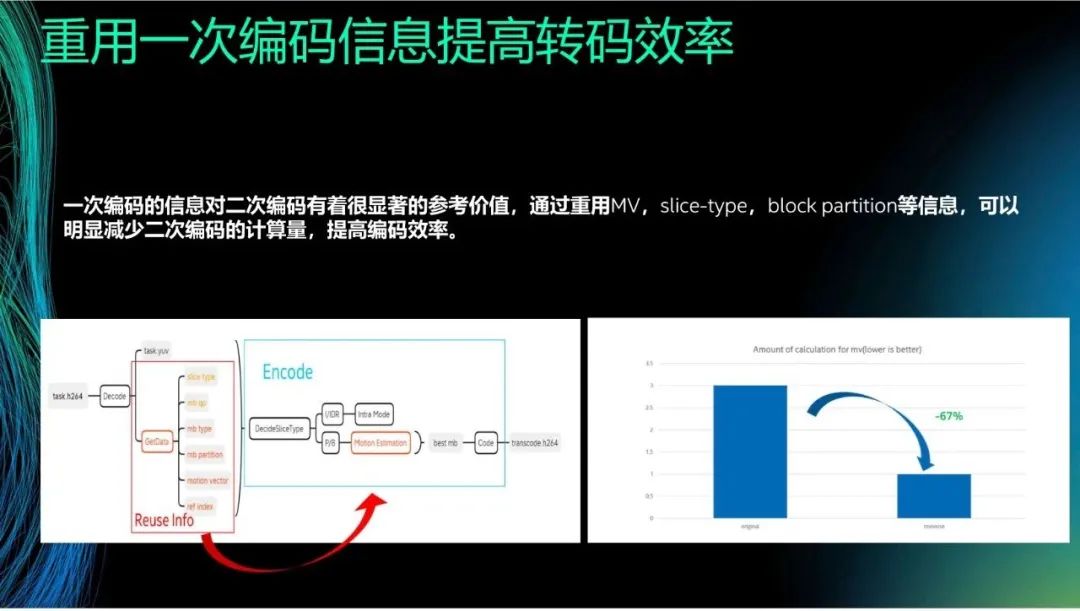
我们现在考虑转码,比如将H.264或H.265转换成H.266或AV1。在一次编码时,我们可以获得slice type、mb qp和mb partition等信息。在现在的编解码方式中,解码之后这些信息就会被舍弃。而我们的核心思想是,在二次编码中重用一次编码的信息。通过粗略计算,在大部分场景下,重用一次编码信息可以减少大约67%的运算量。
对于这种思路,大家可能有很多问题。比如,当帧率或分辨率在转码前后发生变化时,会不会出现一些新的问题。因此,虽然方案的原理比较直接,但实际应用时需要解决很多“并发症”。特别是,我们要考虑如何一方面提升转码速度,另一方面保证转码质量,否则转码质量不好,即使转码速度很快,也不能投入实用。
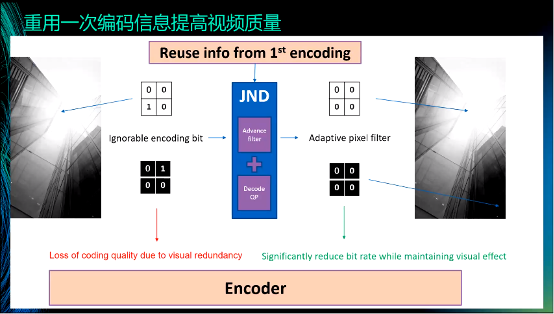
举个例子说明如何重用一次编码的信息来提高视频质量。JND是一种感知编码技术,在左上的图中,四个block中只有左下的block的值为1,其余block的值为0。但对于人眼来说,可以忽略数值1,即四个block的值可以都为0。这是JND的核心思想:过滤人眼感触不到的信息。对此,经典的方法是使用双边滤波器等进行过滤,但这些方法都是无差别的滤波,容易造成“误伤”。而现在由于掌握一次编码信息,我们知道哪些信息可以被平滑,哪些信息必须保留,通过设置权重的方式来进行“区别对待”。这样做可以带来两个好处,一是可以提高主观视觉的质量,二是在限定码率的情况下,可以将码率用在刀刃上,大幅度地提高客观质量。比如,将一个原码率是50Mbps的视频转码为2Mbps的视频,采用我们的方式就可以较大地提高质量。
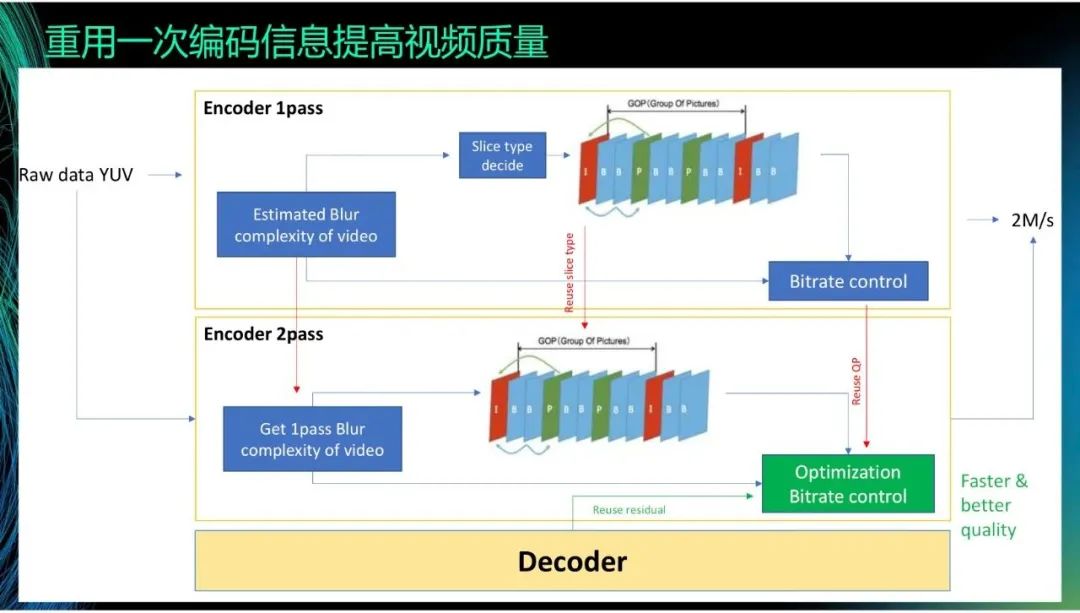
另一种方式是使用一次编码的残差。在H.264和H.265里,有two-path的算法,但这个算法通常不被使用。这是因为,虽然经过一次编码可以掌握大概的信息,并且在此基础上二次编码的结果更精准,编码质量更高且码率更低,但是这会大幅度地增加计算量,推高转码成本和延迟。为了解决这个问题,我们直接重用一次编码的信息来实现类似二次编码的效果。
03 SIMD指令集加速转码热点函数
最后,介绍如何用SIMD指令集加速转码热点函数。
至强服务器平台SIMD指令集经迭代了很多代,大家比较熟知的比如AVX2,AVX512等。第二代至强可扩展平台在AVX512的基础上支持了INT8数据精度,第三代支持BF16指令集,2023年初量产的第四代平台的AI性能在BF16和INT8上较上一代提升了8倍,其中加入了AMX 指令集,也可以理解为在CPU内部有一块硬件加速器。比如INT8的算力,一颗CPU的性能接近200T,很多以前在CPU上无法完成的运算现在都成为可能。
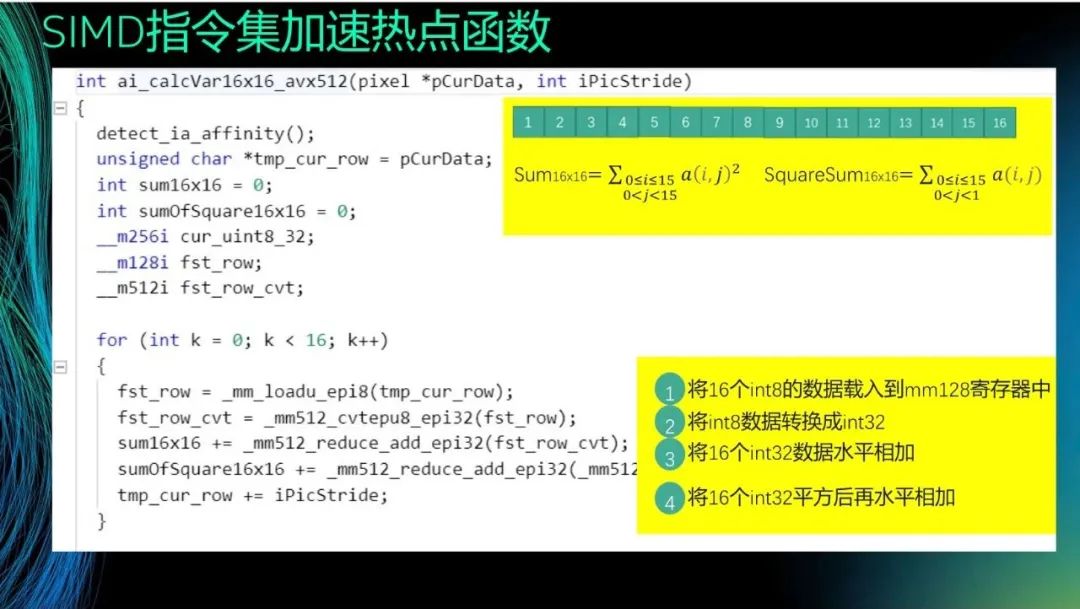
最后介绍一个例子,说明如何使用SIMD指令集优化视频编码。在H.264中有一个大小为16×16的宏块,需要对其求和或平方和,那么如何用avx512对其进行加速呢?需要执行以下几步。首先,将16个int8的数据载入到mm128寄存器中。然后,将int8数据转换成int32,这是因为有时候运算结果为负数,而int8无法表示负数。接着,将16个int32数据水平相加,这需要消耗0.5个指令周期,而手动计算则需要8次计算,因此极大地提高了效率。最后,将16个int32平方后再水平相加。经过这样的处理,性能可提高16倍或8倍(若为一条指令则提高16倍,若为两条指令则提高8倍)。
我今天的分享到此结束,谢谢大家!
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。