
对于短视频应用,上传到云端的视频已经被严重压缩,对于一般质量的视频需要进一步增强后转码。提出的 CAE 方案通过对视频内容分类,针对性的预处理增强,以及自适应编码,相比原始的 x264 编码,取得了较高的 VMAF 指标码率节省和较低的复杂度。
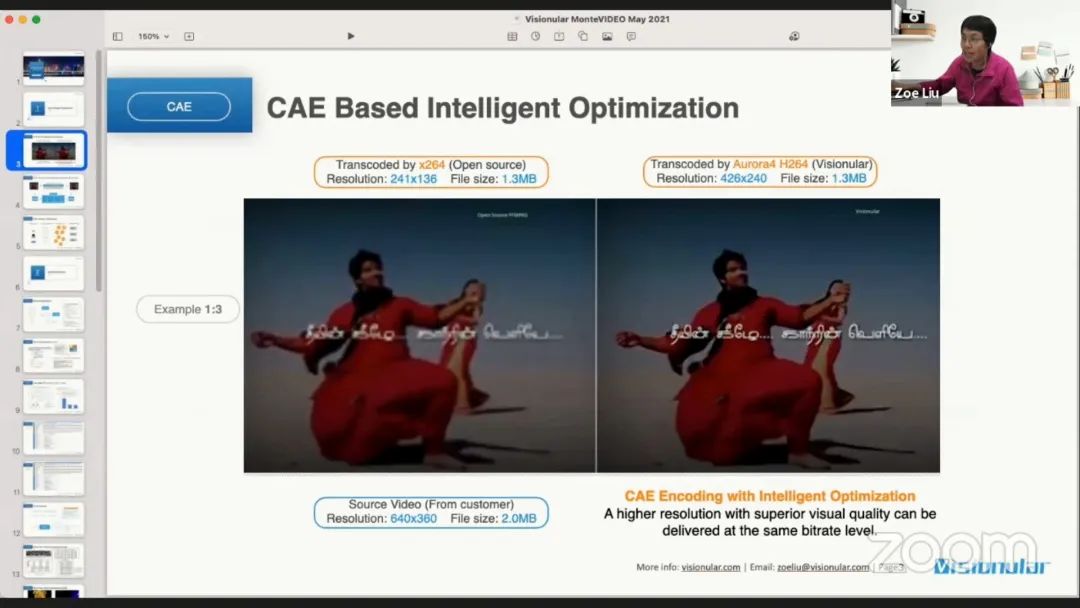
来自 Visionular 的 Zoe Liu 将讨论由视频分析和增强促进的视频编解码。如下图所示,左侧的原始视频是 360P,文件大小约为 2MB。这个视频的比特率在 900kbps 左右,按客户要求必须将视频编码为 300kbps 左右的较低码率。采用了 x264 来做编码的视频结果如左图所示,而使用该公司的 Aurora4 H264 编码器,可以实现相同的码率但是更大的分辨率,如右图所示。

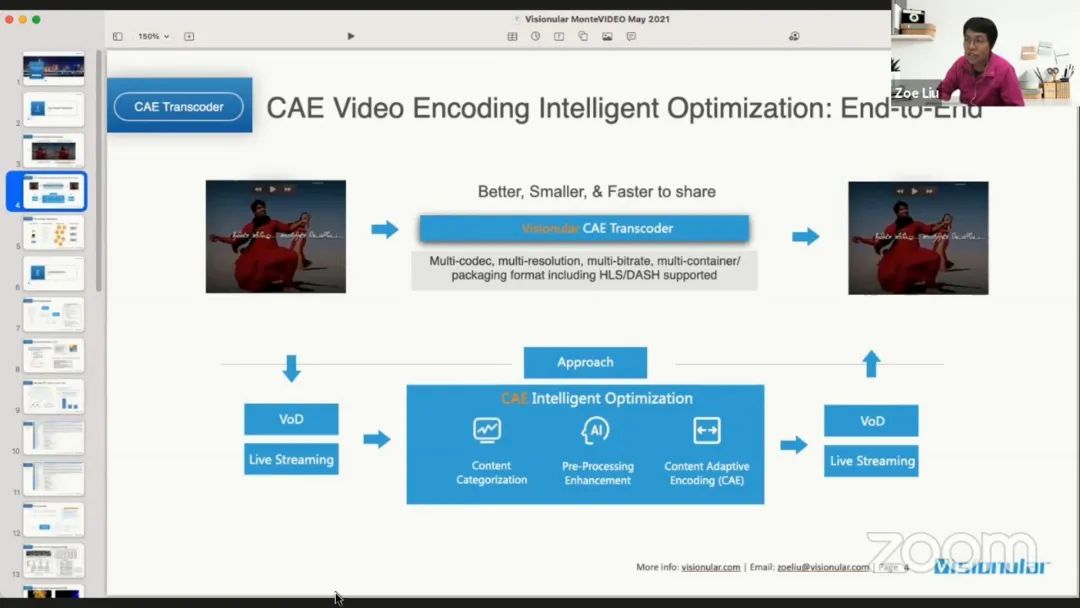
下图是 CAE 视频编码智能优化的端到端框架,通过分析视频来进一步优化视频编码或转码,其业务场景包含 VoD 视频点播和直播流。由于涵盖直播流媒体,必须考虑在处理阶段的计算复杂度。对于直播来说,即使有时会有延迟,也可以允许有几秒或少于半秒的延迟,它必须能够在实时意义上处理每一帧。因此可以使用的方案在计算复杂度方面确实是有限的。该方案基本上是性能和效率的折衷。
这里主要针对的视频内容是用户生成内容 UGC。考虑短视频应用场景,用户的视频被上传到服务器端,很难保证每一个视频都有良好的质量。特别是来自网络连接不太好的地方,视频在进入云端之前已经被高度压缩,在云端的视频会表现出大量的压缩伪影。
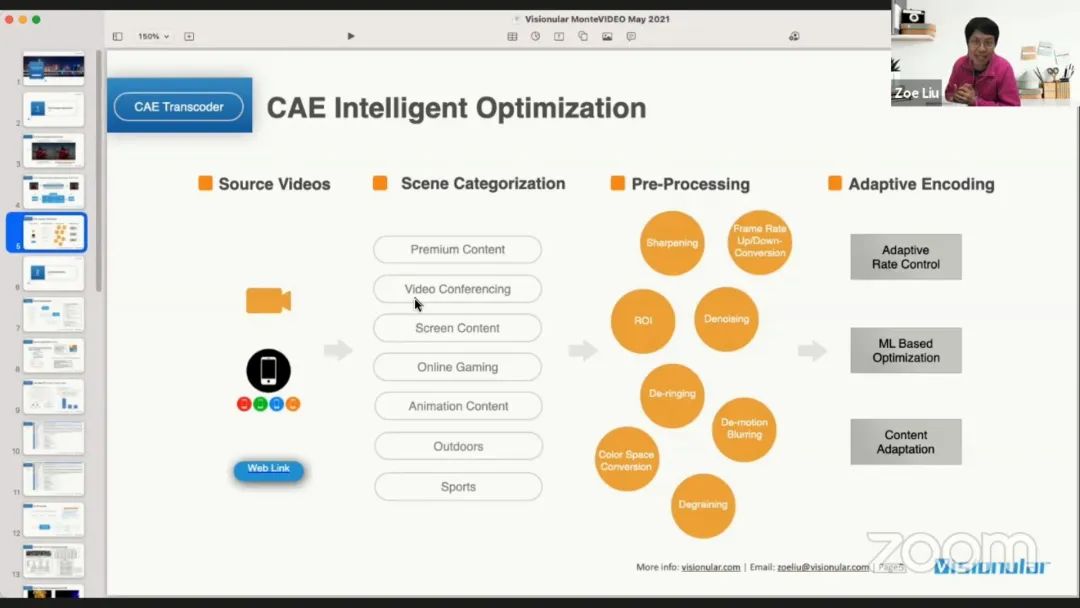
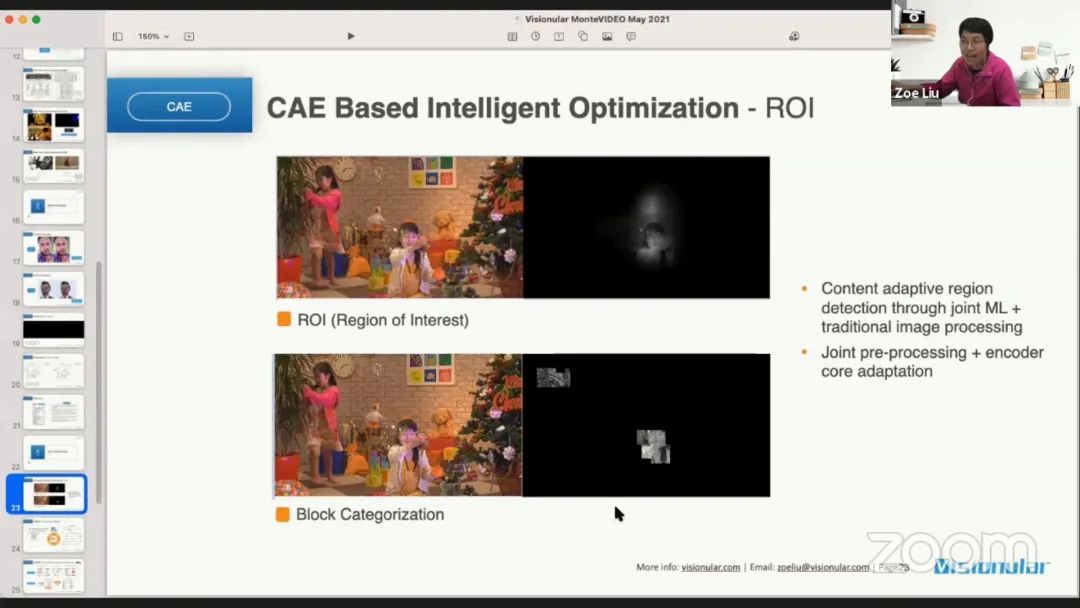
CAE 的处理流程包括场景分类,预处理和自适应编码。首先需要区分视频的内容类别,以应用不同的分析、处理,并相应地自适应地选择最合适的编码工具。场景分类阶段,将视频内容分为优质内容、视频会议、屏幕内容、在线游戏、动画内容、户外场景以及体育运动。预处理阶段的主要工具包括锐化、ROI、帧率上下变换、颜色空间转换、去噪、去振铃、去运动模糊和去胶片噪声等。自适应编码工具包含自适应码率控制,基于机器学习的优化、以及内容自适应编码。
视频内容分类
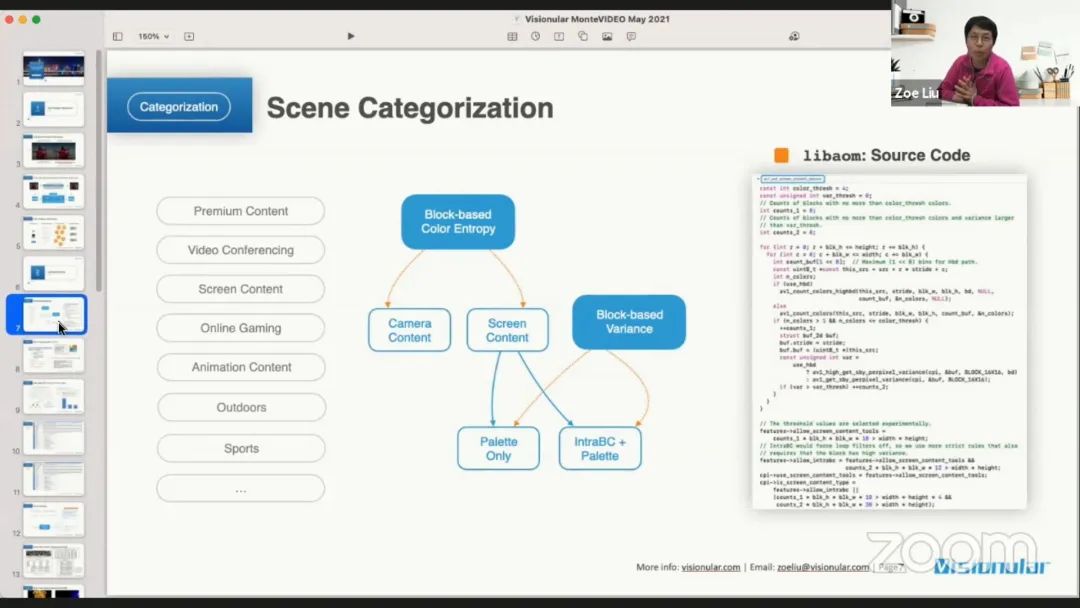
屏幕内容可以包括计算机生成内容、游戏或是动画,而户外场景则有不同的光照条件或体育运动。这里主要讨论的是区分屏幕内容和非屏幕内容的技术。下面的例子来自 libaom,它是相对新的开源编解码标准 AV1 的软件实现。右图截取了 libaom 中区分屏幕内容和非屏幕内容的主要代码。
这里在图像块的基础上统计颜色熵,即简单地计算该块内有多少种颜色,并设定一个经验阈值,例如 4。如果该块仅有非常有限的颜色,则可以把这个区块看成是一个单调图像块。之后统计图片中这种图像块的数量,就可以进行分类。较少的颜色种类将被分类为屏幕内容,否则就是非屏幕内容。
不同场景也总是与不同的编码工具结合起来。对于 AV1 来说,它为屏幕内容的编码提供了专门的编码工具,主要是 IntraBC 和 Palette。编码时可以只应用 Palette 或 IntraBC+Palette。在 libaom 中,还有进一步的优化。比如可以统计每个图像块的方差并设置阈值,计算这样的区块的数量来进行分类。
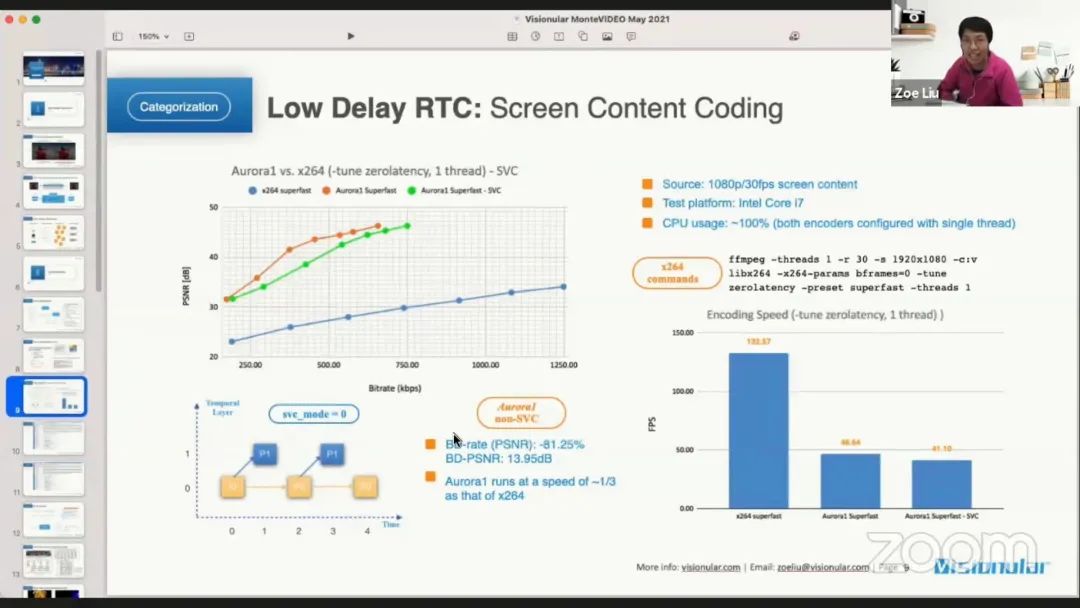
在低延迟 RTC 的屏幕内容编码场景下,Aurora1 super-fast 相比 x264 super-fast 可以节省 81.25% 的码率。在速度方面,前者 FPS 约为后者的 1/3 但是对于 1080p 的屏幕内容也可以做到 46.64 FPS。讲者也给出了编码的主观效果对比。
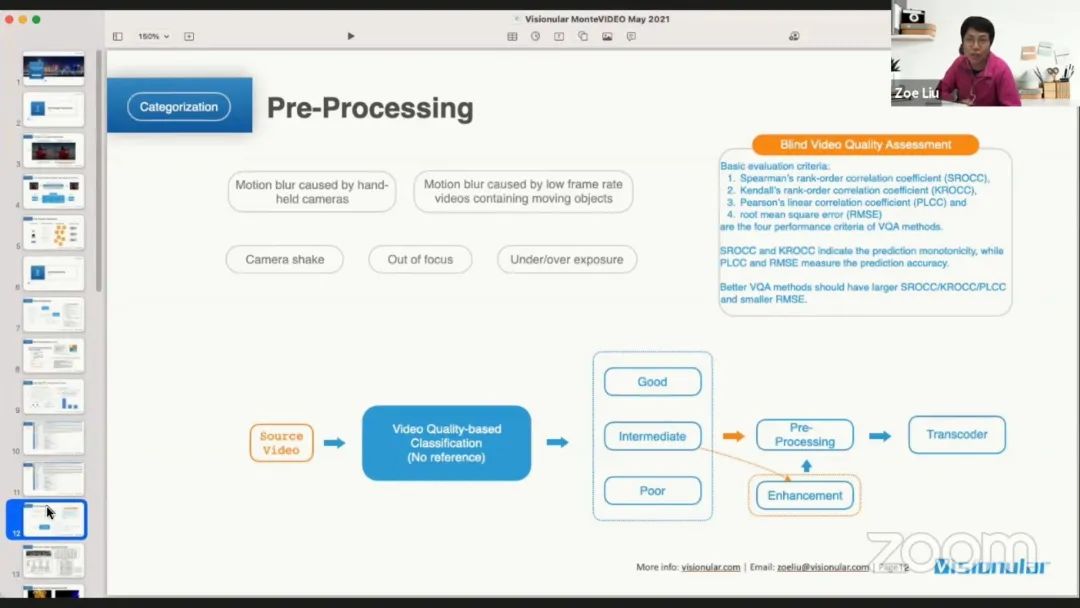
对于上传到云端的视频,可以根据视频的主观质量对其进行分类,例如分为好的,中间的或差的视频质量,然后应用不同的处理策略。这里的质量评估无法参考原始视频,在学术界称之为盲视频质量评估(Blind VQA)。对于短视频应用程序,如果视频质量非常差,则尽量不要流向终端用户;如果视频质量良好,则可能吸引到大量的终端用户观看。对于中等质量的视频,则可以应用增强机制,以吸引更多的用户观看。BVQA 领域有很多的研究,这里会提到几个。其中 SROCC 和 KROCC 可以指示预测的单调性,PLCC 和 RMSE 指示预测的准确性。更好的 VQA 方法应该有更大的 SROCC、KROCC、PLCC,以及更小的 RMSE。
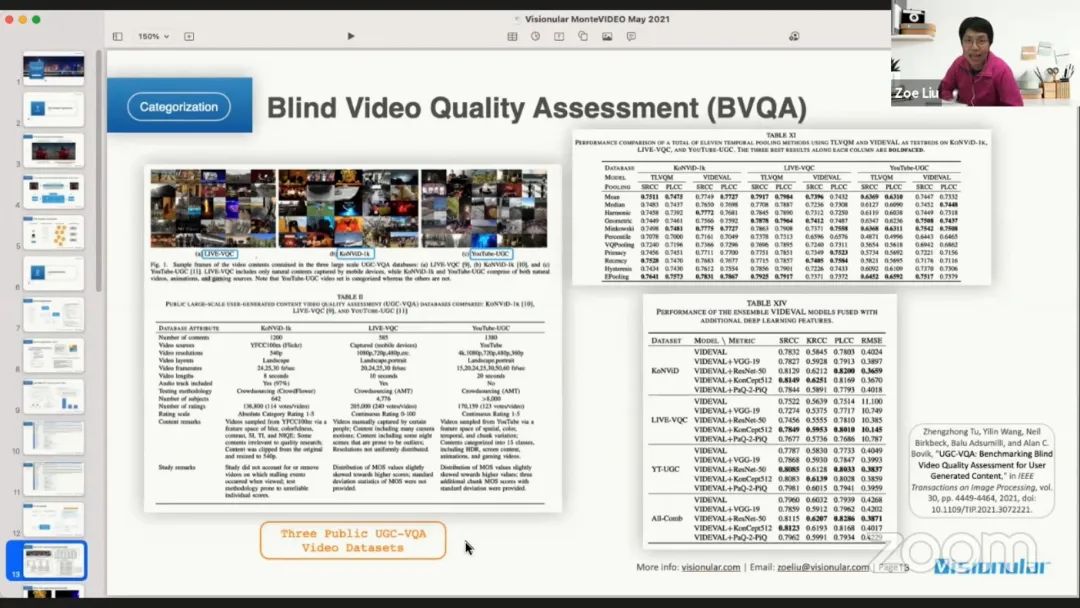
这里推荐一篇论文《UGC-VQA》,它刚刚发表在 IEEE TIP 上。为了使用深度学习工具来做质量评估,需要一些视频标注,有很多视频数据库已经标注了它们的质量。这篇文章提到了 3 个公共的 UGC 视频质量评估数据集,讲者在其产品中使用了其中的 2 个。论文使用从视频中提取不同的特征,给出了 SROCC、KROCC、PLCC,和 RMSE 分数。
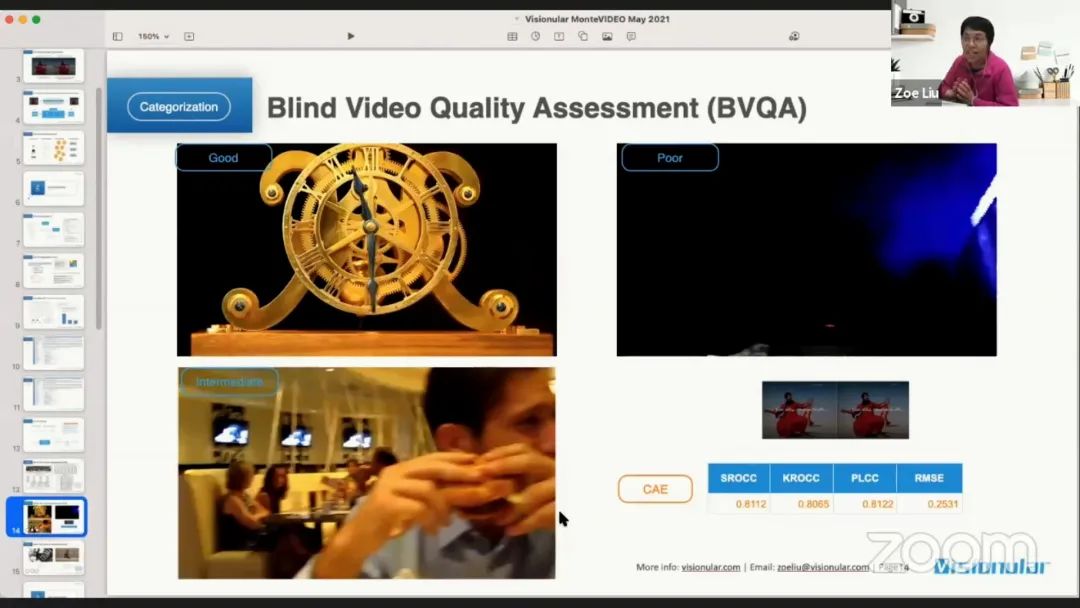
之后,讲者展示了在用户体验上好的、差的和中等质量的视频。在应用中,必须确保应用于每一个视频的分类必须足够快,以实现直播处理。最终,与视频的帧率相比,可以使用单线程达到 3X-5X 的分类速度。与客户提供的标签相比,达到了 90% 以上的准确度。
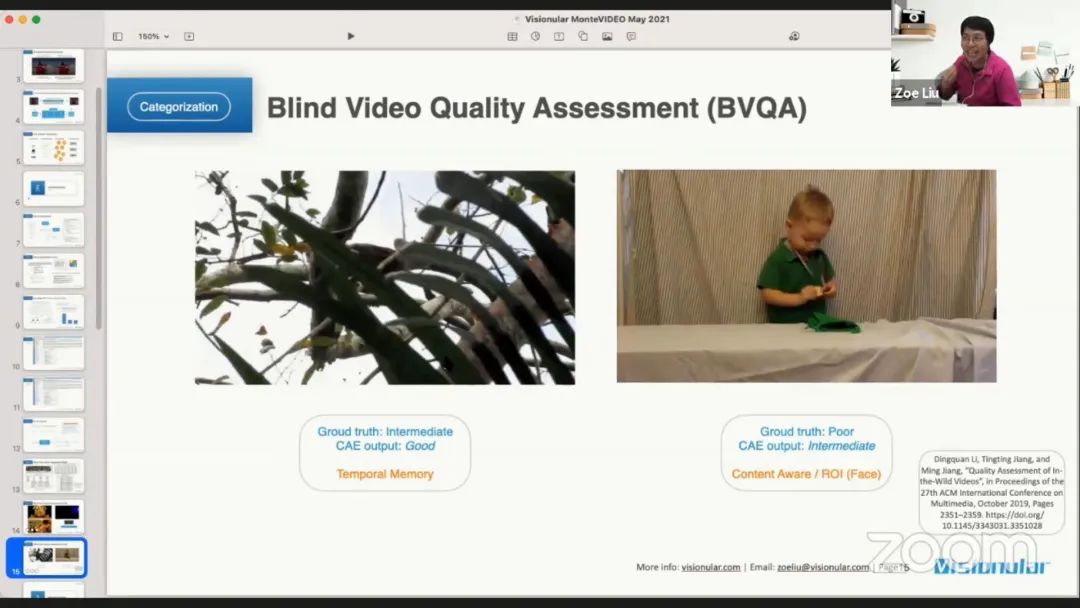
这里给出了一些分类错误的例子。左侧的视频是中间质量,但分类为良好质量。其中一些帧的质量相对较差,有相当多的压缩伪影,但总体上是好的。这与时间记忆有关,我们的人类视频系统记住了或特别注意了一些少量的质量较差的帧。因此,需要研究如何将差的分数加权到最后的分数中,以及如何加权不同帧的主观质量的波动。右侧的视频是差的质量,但分类为中间质量。观察发现这个孩子的脸真的很有吸引力,如果视频中有一个主要的脸部区域,人眼视觉系统会对脸部内容给予很大的关注。这里也给出了一篇论文,专门提到了这两个方面,即如何将人眼视觉系统和视频主观质量分类联系起来。
预处理
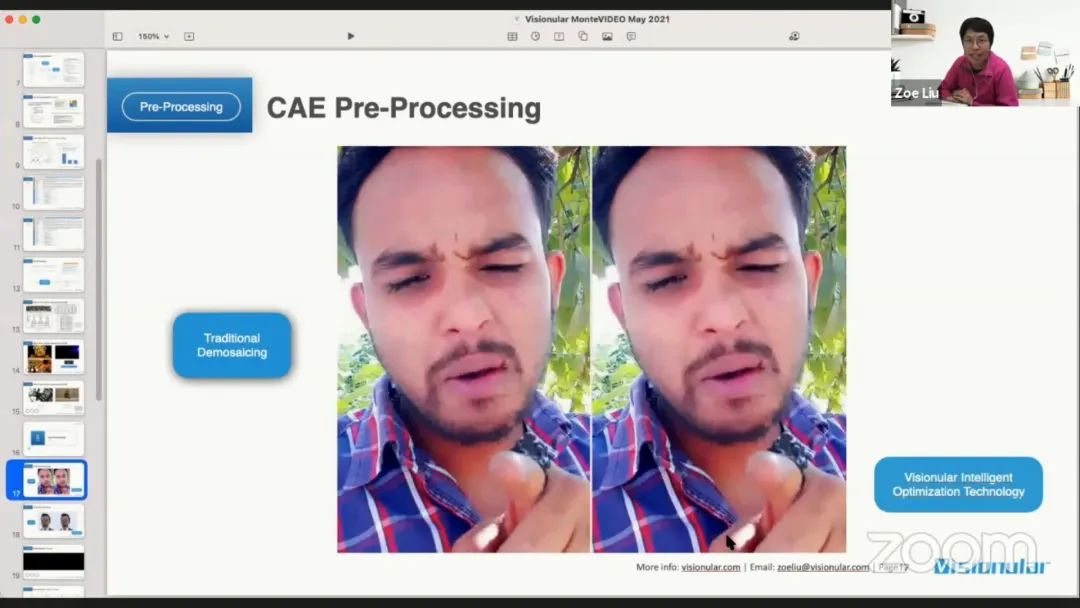
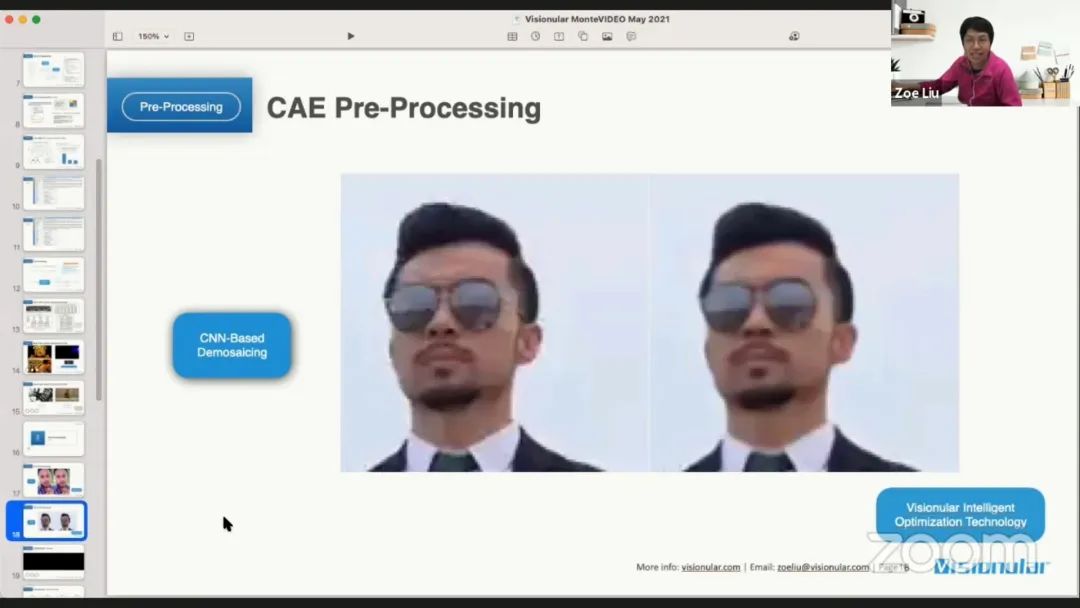
上传到云端的视频已经有大量的压缩伪影,可以应用大量的增强手段,如锐化或基于区域的处理。这里给出了一些消除压缩伪影的例子,分别使用传统的图像处理方法和深度学习方法。
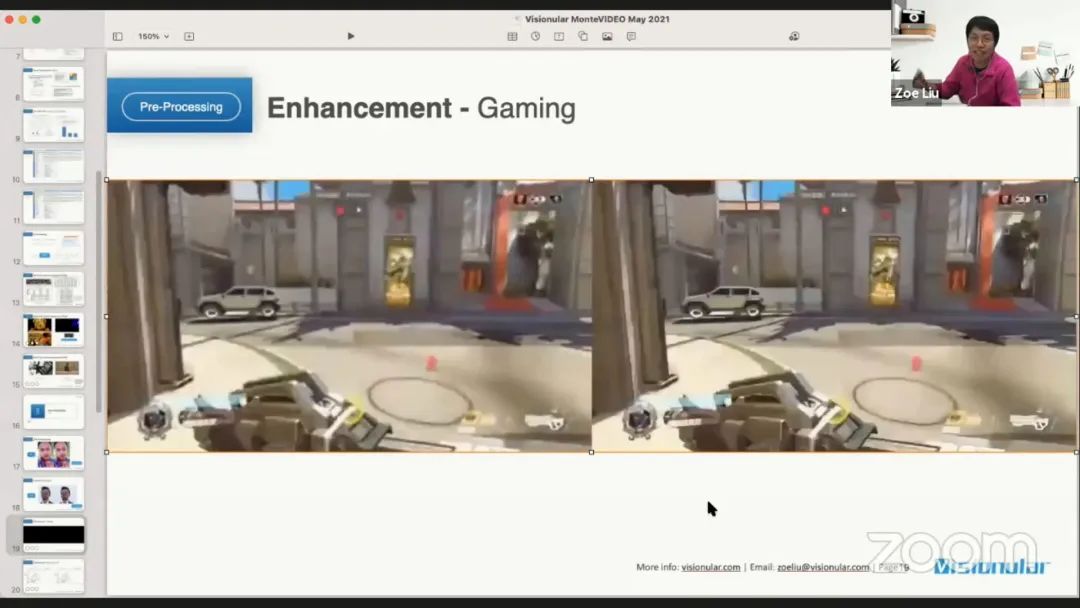
如果已经有一些视频被归类为中间质量,也被标示为潜在的最多观看的视频。例如,在 YouTube 上,部分视频贡献了 95% 以上的浏览量。对于这些视频来说,值得花更多的计算资源来增强视频。下图是一些增强的结果。
这里列出了工作参考的主要论文。LIVE 实验室网站上也有很多质量评估的资源,包括相当多的结果,论文和开源代码。
转码
我们可以应用基于区域和基于块的转码策略,如果一些区域是比较重要的,可以分配更多的比特。讲者将CAE方案应用在 AV1 上,并给出一些结果。对 AV1 的介绍暂且跳过。
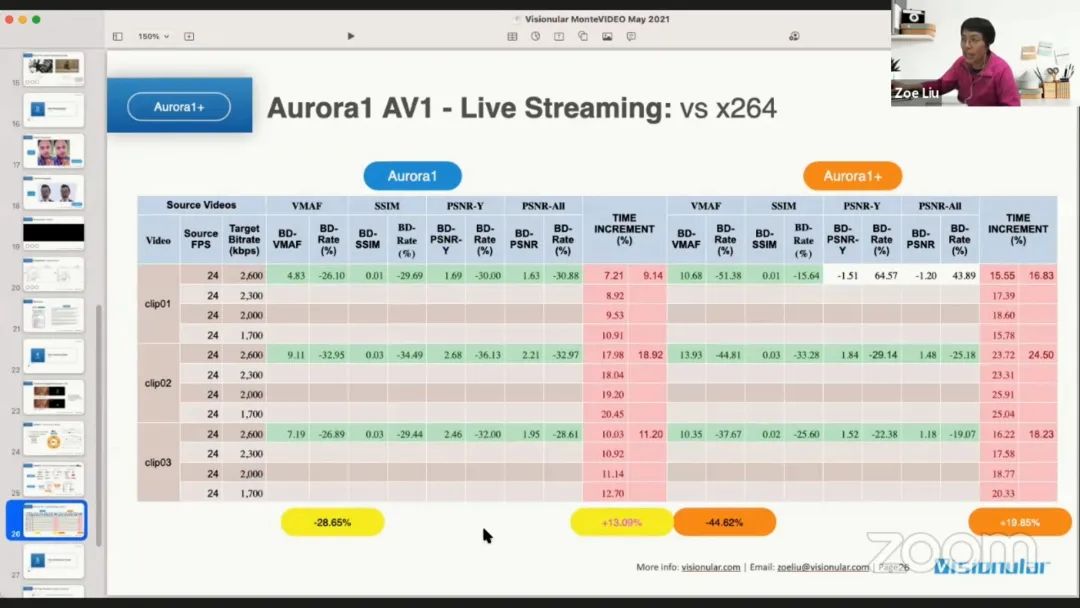
这里给出 Aurora1 AV1 编码器应用于直播流媒体的结果。所有的客户视频都是利用 x264 编码器进行原始编码,这里对 1080P 视频进行了比较,给出了不同的客观质量分数。在 VMAF 指标下,相比于 x264,Aurora1 AV1 可以达到 28.65% 的码率节省。在应用了视频分类、预处理和增强技术之后,可以节省 44.62% 的码率。
在复杂度方面,Aurora1 AV1 增加了 13.09% 的编码复杂度,而加了增强阶段的 Aurora1+只增加了 7% 的复杂度,但是额外得到了 19.85% 的码率节省。
来源:Global Video Tech Meetup
主讲人:Zoe Liu
内容整理:冯冬辉
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。