
在本篇文章中,作者提出了 DiffEdit,一种用以文本为条件的扩散模型进行语义图像编辑的方法。语义图像编辑是图像生成的延伸,其额外的约束条件是生成的图像应尽可能地与给定的输入图像相似。本文的主要的贡献是通过对比不同文本参数条件下的扩散模型的预测,自动生成输入图像中需要编辑的区域,并在 ImageNet 上实现了最先进的编辑性能。
来源:ICLR 2023
作者:Guillaume Couairon 等
论文题目:DiffEdit: Diffusion-based semantic image editing with mask guidance
论文链接:https://arxiv.org/abs/2210.11427
内容整理:汪奕文
引言
语义图像编辑的任务包含了根据文本要求对输入图像进行修改的任务。语义图像编辑任务与图像生成任务有很大的相似之处,可以看作是对以文本为条件的图像生成的扩展,并有一个额外的约束条件:生成的图像应尽可能地接近给定的输入图像。
在以往的工作中,对于语义图像编辑任务来说缺乏两个关键的特性:
- 图像修复会丢弃图像编辑所需的输入图像的信息;
- 必须提供一个 mask 作为输入,以告诉扩散模型图像的哪些部分应该被编辑。
在以往的工作中,也存在不使用 mask 作为输入的扩散模型方法。然而,这些编辑方法倾向于修改整个图像,而非进行局部编辑。此外,向输入图像中添加噪声会丢弃重要的信息,其中包括在应该被编辑的区域内部和外部的信息。
本文提出了 DiffEdit 算法,可以自动找到输入图像中哪些区域应该根据文本要求进行编辑。通过对比有条件的和无条件的扩散模型的预测,模型能够找到需要编辑的图像区域。此外,本文还证明了使用反向去噪模型,在潜在空间中对输入图像进行编码,而非简单地添加噪音,可以更好地将编辑的区域融入背景,并产生更微妙和自然的图像编辑结果。
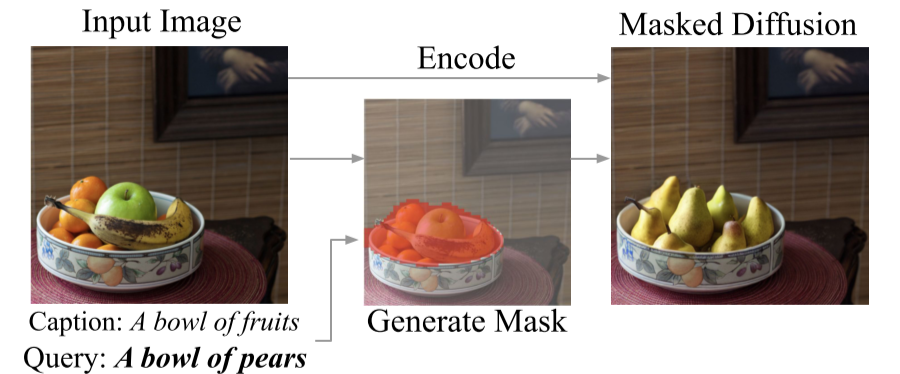

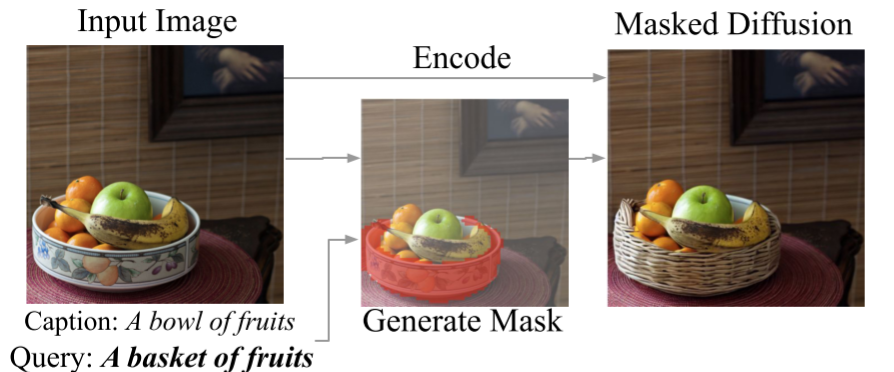
背景
扩散模型
去噪扩散概率模型 (DDPM) 是一类生成模型,它被训练来反转扩散过程。在一定数量的时间步数 T 内,扩散过程逐渐向输入数据添加噪声,直到产生的分布是高斯的。然后,训练一个神经网络来逆转这一过程,在训练中最小化去噪目标:
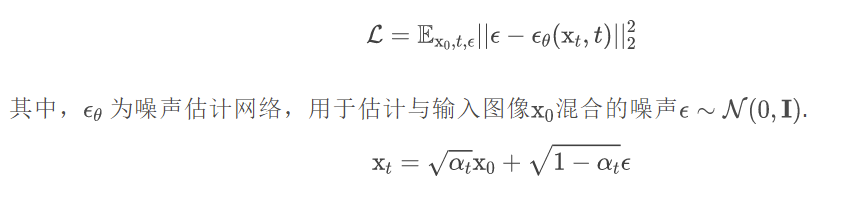
DDIM
DDIM 不再限制扩散过程为马尔可夫链,可以采用更小的采样步数来加速生成过程。从 xt ~N(0,I)开始按照下式迭代:

方法
网络模型
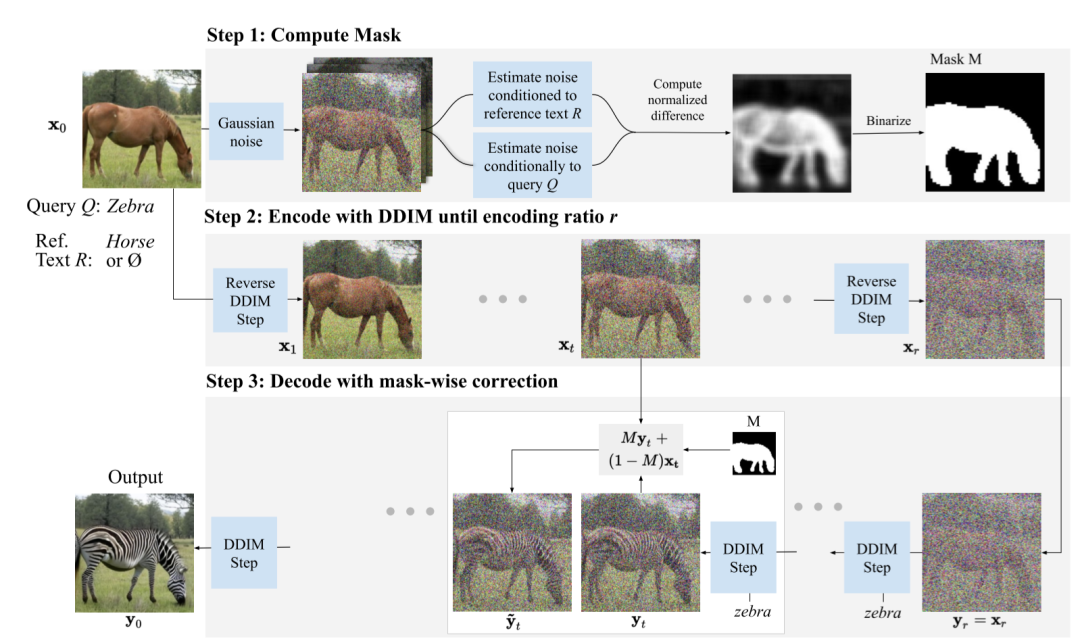
Step1 计算图像编辑 mask 当对图像去噪时,在不同的文本条件下,扩散模型将产生不同的噪声估计值。我们可以根据估计值的不同之处,得出哪些图像区域与条件文本变化有关的信息。因此,噪声估计值之间的差异可以用来推断出一个 mask,以确定图像上哪些部分需要改变以达到文本要求。去除噪声预测中的极值,并通过对一组噪声的空间差异进行平均来稳定效果,然后将结果重新缩放到[0, 1]的范围内,并用一个阈值进行二进制化,就得到了图像编辑 mask。
Step2 DDIM 编码 使用 DDIM 编码 Er 对输入图像 xo 在时间步 r 上编码。这是在无条件模型下进行的,即使用条件文本为ɵ,在这一步没有使用文本输入。此步骤的中间结果 xt 将在 Step3 中用到。
Step3 基于 mask 的解码 首先,使用目标文本引导的扩散模型做采样得到 yt,并用 mask 来引导扩散过程。对于在 maskM 外的图像部分,编辑后原则上应与输入图像相同,所以通过用 DDIM 编码推断出的中间结果 xt 替换 M 外的像素值来指导扩散模型,这将通过解码自然地映射回原始像素。
理论分析

实验
实验设置
数据集 首先,在 ImageNet 数据集上,对于给定的一张属于某个类别的图像进行编辑,使其转换目标所指向的另一个类别的物体,编辑目标通常为场景中的主要对象。其次,为了评估改变背景或次要对象的图像编辑效果,在由Imagen基于文本生成的图像上进行编辑。最后,在 COCO 数据集上进行图像编辑,以评估基于更复杂文本的编辑效果。
扩散模型 实验中,使用了 Stable Diffusion 的潜在扩散模型作为backbone。在 ImageNet 上训练了 256 X 256 的类条件模型。
实验结果
ImageNet
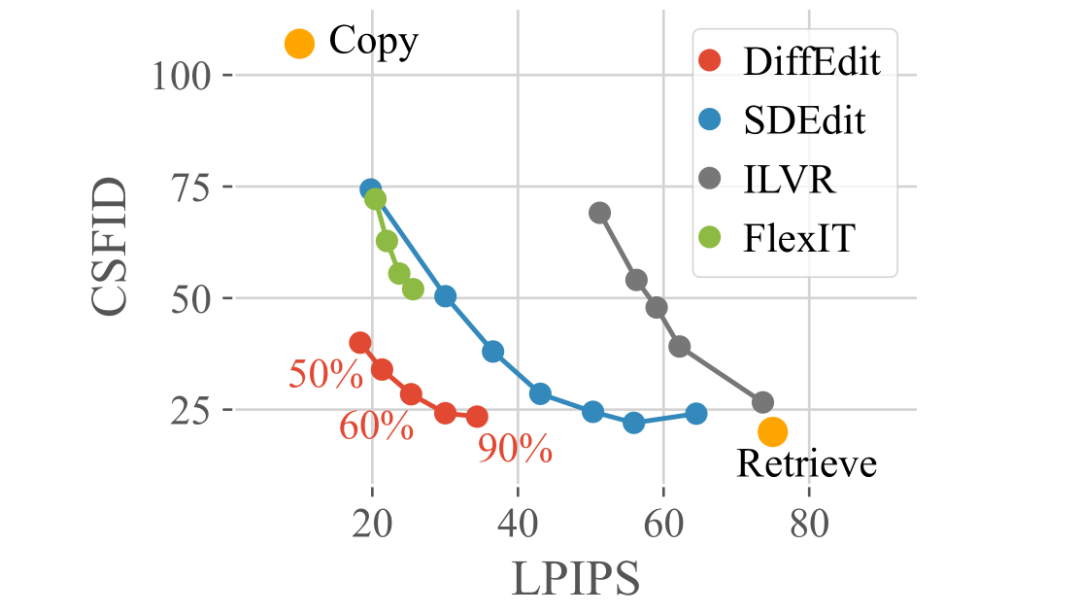

Imagen 生成的图像
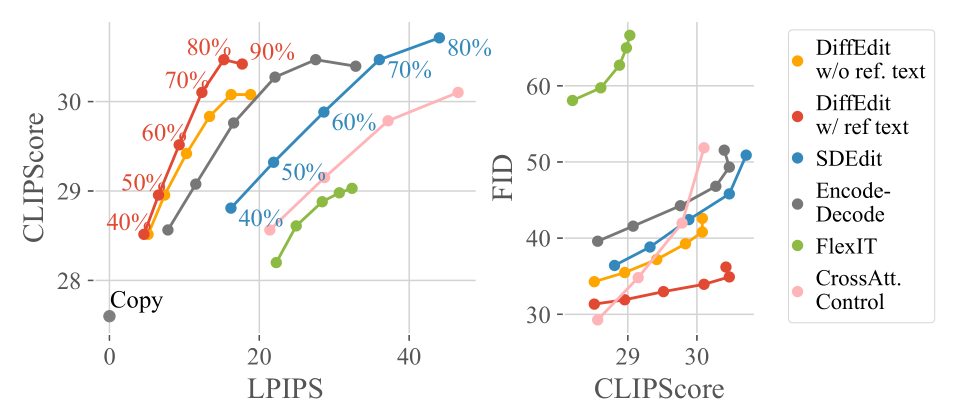

COCO
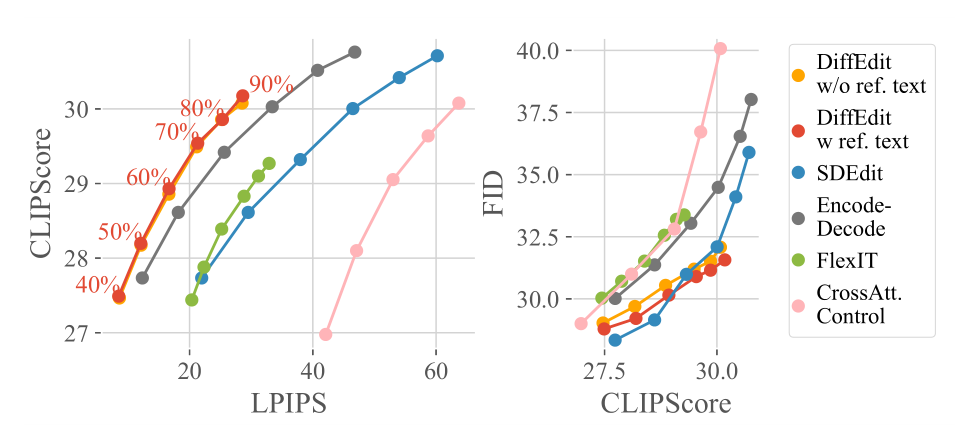

消融性实验
消融性实验包含了 DiffEdit 的两个核心部分,mask 推理和 DDIM 编码。
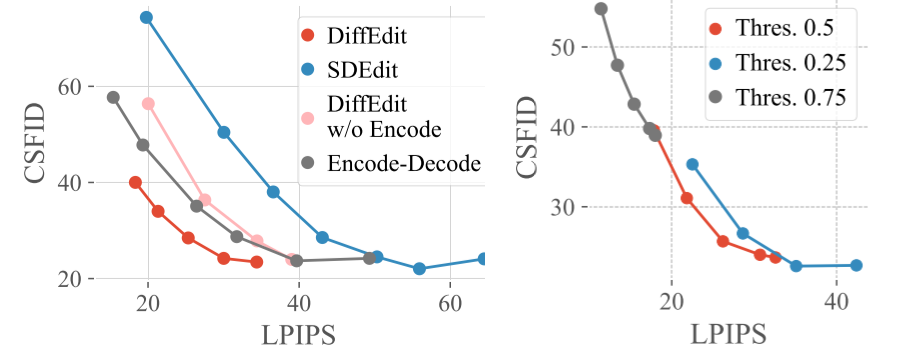
加入了 mask 推理和 DDIM 编码之后,分别都改善了 trade-off,减小与输入图像的平均编辑距离。此外,将这两个元素同时结合到 DiffEdit 中时,可以得到更好的 trade-off,显示出它们的互补性。mask 能更好地保留背景,而 DDIM 编码则保留了 mask 内输入的视觉外观。不同的 mask 二值化阈值结果如上右图所示。与 0.5 的阈值相比,较低的阈值 0.25 会导致生成的 mask 更大,即图像编辑区域更大;较高的阈值 0.75 会导致 mask 的限制过大。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。