
数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已。
基于统计信号处理的传统噪声抑制方法是通过检测持续的背景声,来估计背景噪声,然后通过估计到的背景噪声计算增益因子对带噪语音进行抑制。但这种方式针对规律的稳态噪声比较有效,如空调声,吸尘器的声音等,而针对突发噪声,如撞击声,键盘声,关门声等等效果往往不如人意。随着深度学习的兴起,越来越多的人们开始关注并使用深度学习强大的非线性能力进行语音降噪。数据驱动的方法如何生成高质量的数据在训练过程中显得尤为重要,这里对AI降噪的一些数据扩增方法进行了总结和实现。
MixTransform
首先使用最多的就是让纯净语音和带噪语音按照不同信噪比进行混合,这样就可以得到丰富的带噪语音,一般采用随机数生成随机的信噪比,信噪比的范围可以根据自己的使用场景进行设定。
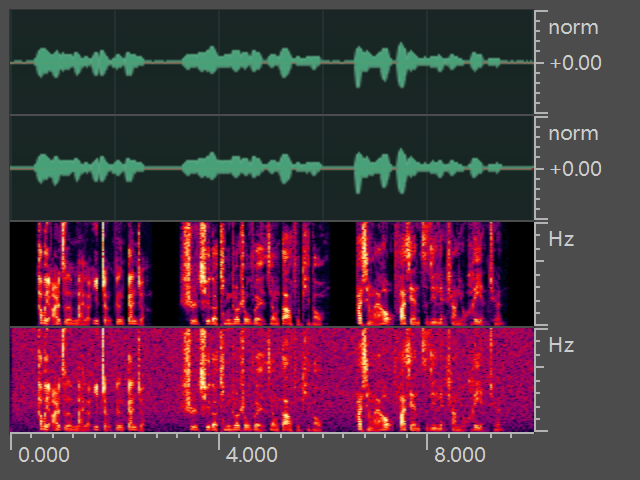

SpecTransform
在RNNoise论文中,作者提出使用二阶的IIR滤波器分别对语音信号和噪声信号进行处理,从而丰富语音频谱特性。
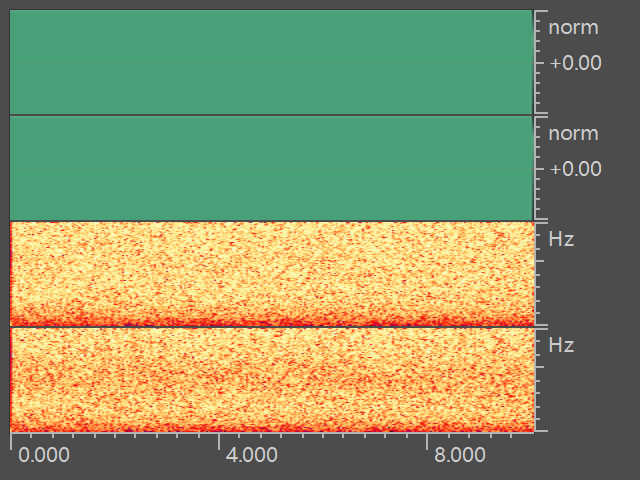
VolTransform不同设备的增益不同,不同距离的说话人声音大小不同,为了模拟这种情况,可以使用阶梯状的增益对语音信号进行处理。
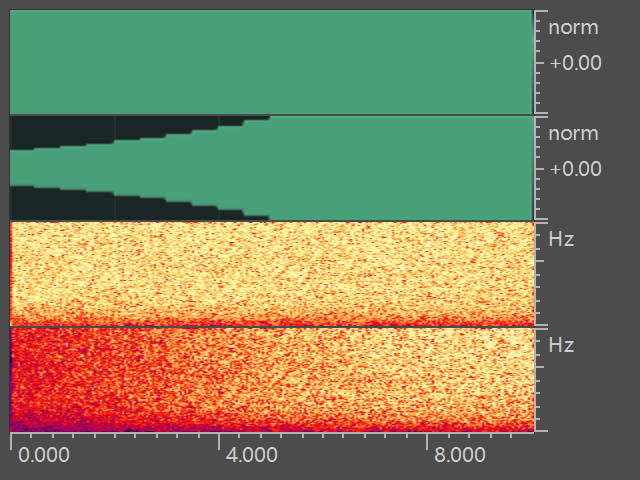
FilterTransform
我们知道有些设备会对输入信号进行EQ处理,从而使得声音具有一定的偏向性,这里可以使用滤波器进行类似的数据扩增。
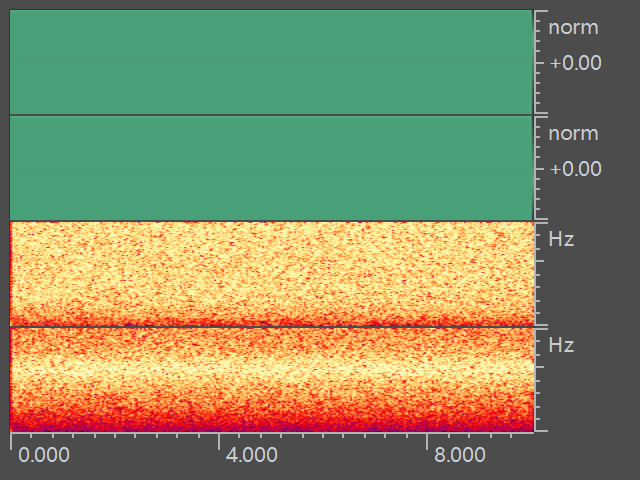
ClipTransform
当声音大小超过输入设备比特所能表示的最大范围后就会发生削顶,这种也是现实生活中常见的一种情况。
ReverbTransform
为了模拟不同的使用场景,可以通过RIR去模拟不同的房间对应的不同的混响时间。
BreakTransform
在网络通话过程中丢包是很常见的事情,我们可以通过时间轴上的mask来模拟语音帧不连续的过程。
HowlingTransform
啸叫也是会议通话场景经常会发生的情况,我们可以通过AIR和回路中大于1的增益来模拟这种情况。
DynamicTransform
上面所讲的都是针对一种情况的数据扩增方法,但是真实声学环境比较复杂,很容易想到使用以上的2种或者多种组合进行数据扩增。
Conclusion
以上就是AI降噪常用的数据扩增方式,当然篇幅有限还有其他的数据扩增方式没有介绍。总的来说,训练数据是否丰富和干净一定程度上决定了AI降噪模型的性能,正如本文开头那句话所阐述的道理。
作者:Ryuk
来源:语音算法组,本文相关代码在公众号语音算法组菜单栏点击Code获取
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。