
这是AI降噪的第二期,上一期我们介绍了AI降噪的N种数据扩增方法,这一期我们介绍下AI降噪的一些损失函数。
降噪,或者语音增强,经过近50年的研究发展,涌现出了很多优秀的降噪算法,从最简单的谱减法,到维纳滤波,再到子空间的方法以及基于统计模型的MMSE估计器,然而传统信号处理的降噪算法在imcra-omlsa出现之后发就展趋于平缓。在2014年中科大的徐博士用DNN直接对数功率谱映射进行降噪的实验拉开了深度学习降噪的序幕,随后各种各样的研究如雨后春笋般爆发。
在此期间AI降噪的损失函数也经历着快速的发展,一开始基于对数功率谱映射完全是使用回归的思想进行降噪,后面则使用Mask作为学习目标,这里的损失函数仍是以MSE为主;后面人们发现基于MSE的损失函数无法正确的反映语音质量,因此一些基于SNR的损失函数被相继提出。在这个阶段,相位对语音质量影响不大的观点仍然在人们心中保留。然而随着后续研究的推进,人们发现把相位纳入损失函数的计算当中可以取得更好的效果,至此基于复数的神经网络结构全面开花。AI降噪的损失函数有很多种,在有限的篇幅内全部介绍完也不现实,因此本文介绍每一类的一种或几种。大多数语音增强都是通过估计语音与噪声信号的mask来实现的,可以参考基于Mask的语音分离。
Signal Model
在语音增强领域,我们一般假设信号中的噪声是加性噪声,因此经过短时傅里叶变化后,在频域观测到的信号可以分解为期望信号S和噪声信号N的和,
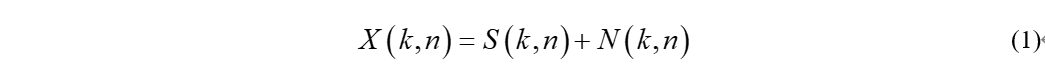

而语音增强的目的就是估计出期望信号,即
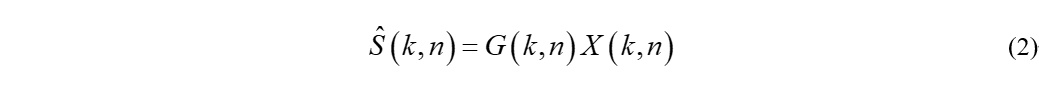
其中G既可以是实数也可以是复数。
Distance-based Loss
基于距离度量的损失函数有的会直接使用估计出来的mask进行计算,如RNNoise的损失函数。
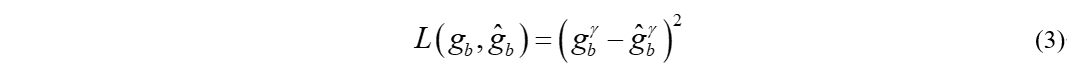
但更为一般的做法是计算估计出来的幅度谱与真实的幅度谱之间的MSE。
我们以L2 MSE的损失函数为例,解析该损失函数如何在语音增强任务中引导模型的学习。首先将损失函数改写为如下形式:
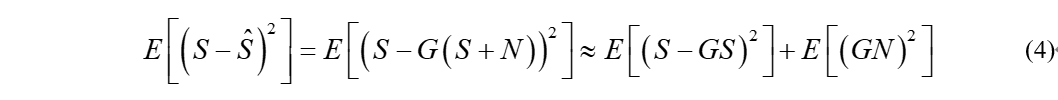
那么等号右边可以分解为两部分,第一部分语音本身的失真,第二部分是噪声的抑制。一般来说当信噪比很大时,我们希望尽可能保持较小的失真,反之我们希望尽可能地抑制噪声。那么我们可以看出公式(4)的一些问题,当噪声比较小时,我们估计出的G会接近于1,那么右边第一项接近于0,但是噪声项被完整的保存下来,反之亦然。因此加权MSE被提出用于来平衡语音本身的失真和噪声的抑制程度,即
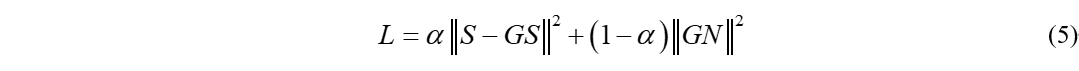
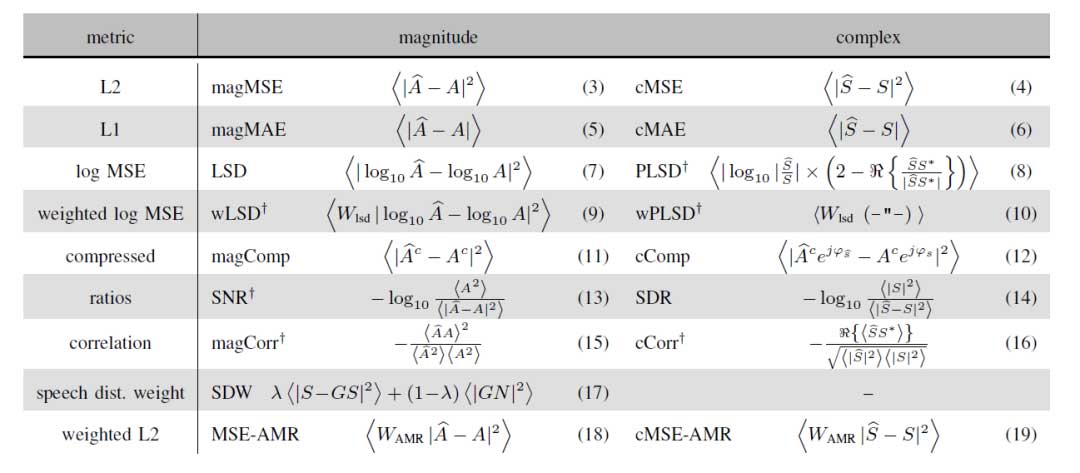
除了上面介绍的几种之外,基于距离度量的损失函数还有很多其他形式,如有的在复数域计算,有的会进行对数或者压缩运算,简单总结如下表所示。
SNR-based Loss
基于距离度量的损失函数虽然简单有效,并且有一定的可解释性,但存在一个问题。损失函数无法和客观指标一致,有的时候损失函数低,但效果可能不尽人意,因此有人想到为什么不直接用客观指标作为损失函数呢?因此常用客观评估语音质量的一些计算方法被设计成了语音增强的损失函数,最常见的便是SNR了。但是SNR是整数,并且越大越好,而损失函数我们希望越小越好,那么怎么办呢?很简单,加个负号就好了,即
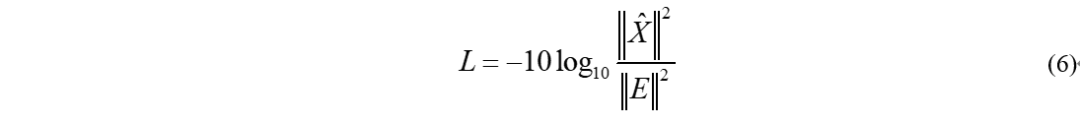
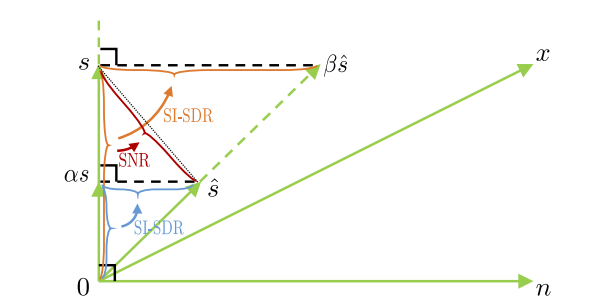
除了SNR之外,SI-SDR也是语音增强中常用的损失函数。简单来说将估计出来的向量 s_hat分解到ground truth及其正交方向,容易得出s_hat与s越平行,SI-SDR越大,反之SI-SDR越小。SNR与SI-SDR示意如下所示。
同样的为了将SI-SDR作为损失函数,我们也对其加上一个符号,即
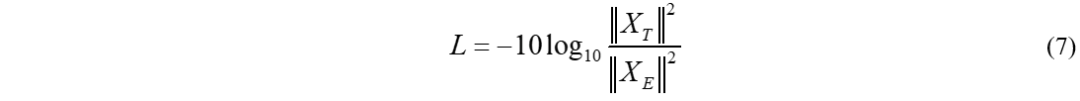
值得注意的是,如果单独使用SI-SDR,可能会导致模型估计输出与输入之间的幅值不稳定,并且如果训练数据中存在0值时,单独使用SISDR时会出现问题,公式计算不稳定,SNR的值都会爆炸,所以一般会结合一定尺度的MSE loss一起使用。除了上面介绍的两种损失函数之外,还有许多基于SNR改造的损失函数,这里就不一一列举了。
Perceptual-based Loss
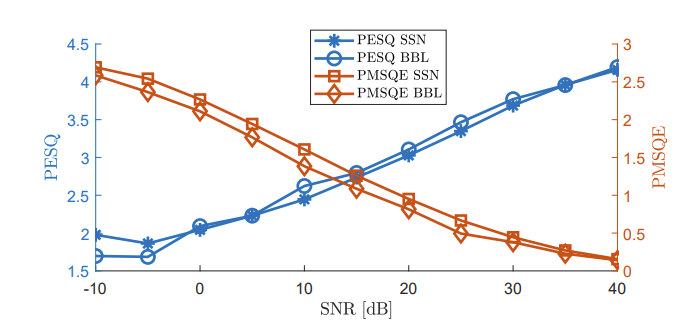
有时候客观指标好了,但是感官不一定好,为了一步到位,有人提出了使用一些符合人们听觉的损失函数。首先让人想到的是PESQ(perceptual evaluation of speech quality),然而尴尬的是PESQ整体计算流程并不可导,秉承着没有条件创造条件也要上的精神,学者们对PESQ计算流程进行改进,提出了PMSQE(perceptual metric for speech quality evaluation)损失函数,遗憾的是与PESQ相同,PMSQE只能针对8kHz/16kHz的信号计算loss,一般都重采样到8kHz进行loss计算。下图是不同信噪比下PESQ和PMSQ的关系,可以看出,PESQ和PMSQE近似成反比,并且相对于SNR具有单调性。
除了PMSQE之外,短时可懂度( short-time objective intelligibilit, STOI)也可以作为语音增强的损失函数,我们知道短时可懂度取值范围从0到1,分数越高可懂度越高,作为损失函数时需要对其加上负号。然而STOI存在一定的缺陷,当测试语音中噪声分量剧烈波动时,STOI与主观测试结果相关性不高,相关系数只有0.47。后来学者们提出了ESTOI( Extended Short-Time Objective Intelligibilit)损失函数来弥补这缺陷。
总结
语音增强的函数多种多样,有些方法只有使用过才知道差别。根据看过的一些论文有以下经验:
- 加入VAD做多任务训练可以辅助模型收敛
- 把噪声分量也作为loss的一部分,并给语音和噪声的loss不同的权重,可以balance噪声抑制与语音的保留
- 使用MSE时,同时联合幅度谱的loss和复数域的loss会带来提升
- 基于compressed的loss比常规的MSE要好,但是压缩系数需要调
- ……
- 优质的数据集比以上几条都重要
参考文献:
[1]. https://www.microsoft.com/en-us/research/uploads/prod/2021/08/23.pdf
[2]. https://arxiv.org/abs/2212.00369
[3]. https://zhuanlan.zhihu.com/p/436809988
[4]. https://zhuanlan.zhihu.com/p/627039860
[5]. https://arxiv.org/pdf/1909.01019.pdf
作者:Ryuk
来源:语音算法组
原文:https://mp.weixin.qq.com/s/PsXb2k5p6seq3s3p0c2z9g
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。