
编者按:Gstreamer作为一个比较流行的开源多媒体框架,其优秀的架构使其具有高度的模块化和良好的扩展性,并具有广泛的应用前景。LiveVideoStackCon2022上海站大会我们邀请到了英特尔加速计算系统与图形部工程师何俊彦老师,为我们详细介绍了Gstreamer的框架和特点,视频的模块化处理,以及其硬件加速的实现与应用案例,并总结和展望Gstreamer的发展与趋势。
文/何俊彦
整理/LiveVideoStack
链接:https://mp.weixin.qq.com/s/IGZ03tBe9Czc4JWF-N0lPQ
大家好,我是何俊彦,来自英特尔的OTC(Open Source Technology Center)部门,已经从事了多年的open source的开发工作。曾参与过X11、Xorg中driver的开发,也做过mesa中的3D driver,后来也做过一些GPU相关的OpenCL的研发。近几年主要在为Gstreamer 提供英特尔GPU相关的video编解码加速插件。目前,我也是Gstreamer社区里的maintainer之一。本次我分享的主要内容是关于Gstreamer中的视频处理与硬件加速。


以上是本次的agenda。首先,介绍一下Gstreamer的Framework,做一个简单的概述。然后,具体介绍视频处理和硬件加速在Gstreamer中的实现。接着讲解一些常用的Gstreamer的pipeline和example,其中可能也有大家感兴趣的AI pipeline的搭建。最后介绍下英特尔对Gstreamer开源社区的贡献以及今后在Gstreamer中的工作。
01 The Framework And Overview of Gstreamer
 首先讲解一下为什么要使用Gstreamer。之前有人说Gstreamer过度依赖插件,但我认为这个说法并不十分准确,其实Gstreamer全是插件。每一次播放,编码或者转码都会以一条pipeline的形式出现,而里面所有的元素则都以插件的形式存在。因此,我们的任务就是要开发好每一个插件,然后将其放入pipeline中,让插件之间能更好地协作。
首先讲解一下为什么要使用Gstreamer。之前有人说Gstreamer过度依赖插件,但我认为这个说法并不十分准确,其实Gstreamer全是插件。每一次播放,编码或者转码都会以一条pipeline的形式出现,而里面所有的元素则都以插件的形式存在。因此,我们的任务就是要开发好每一个插件,然后将其放入pipeline中,让插件之间能更好地协作。
相信各位都多少了解FFmpeg,其是业界广泛使用的编解码框架,使用人数超过Gstreamer。为了更好的介绍Gstreamer,我们先将Gstreamer与FFmpeg做如下对比:
与FFmpeg相比,Gstreamer的优势在于其更易扩展的框架和更广阔的视角。FFmpeg主要还是用于做编解码,但Gstreamer还包括2D/3D rendering等功能,而且这几年也引入了很多deep learning的插件, 比如英伟达做了DeepStream,英特尔做了DL Streamer等。
此外,Gstreamer也更容易上手使用。FFmpeg的help信息有很多页,初学者可能需要耗费一两周的时间了解学习帮助信息。与此同时,FFmpeg满屏参数交织在一起的命令行,有时也让人不好理解。
而Gstreamer只需要简单搭建pipeline,放入正确的插件,插件之间以!符号相连接,即可完成,非常的直观。而各个插件的具体参数是自动协商完成的,不需要用户指定大量的参数。比如让decoder连接一个视频后处理插件来完成格式和分辨率转换,我们只需指定最终输出格式和分辨率,而decoder与后处理插件之间的具体格式,分辨率以及颜色空间等具体参数的协商都是自动完成的,所以用户使用起来就很方便。
但此处不得不说,所谓“成也萧何,败也萧何”,有时候其自动协商的结果并不是我们想要的,或者说跟我们期望的行为有差距,这就会造成一些问题和bug。因此有些人使用Gstreamer后,会觉得Gstreamer的理念很好,上手很方便,但是使用起来bug较多。其实这主要还是因为插件开发者没有完全follow框架的要求或者插件自身存在bug造成的,而框架本色是足够稳定和出色的。所以,作为我们开发者,需要开发好Gstreamer的每一个插件来减少上述问题。
与FFmpeg相比,Gstreamer也有不好的地方。FFmpeg最大的优势是代码简洁、效率高,而Gstreamer为了保证插件机制和良好的可扩展性,其代码相对比较复杂,类和类之间的互相依赖和层次关系也比较繁复, 使得其学习周期也比较长。即使一个工作多年的老手在debug的时候,也不一定马上能在Gstreamer里找到对应的处理函数和出错代码,而是需要耗费一定的时间来跟踪和分析。
其次,FFmpeg只有一个repo,而由于扩展性的需求,Gstreamer会使用多个repo来分别存放基本框架,基本库和插件。这在带来灵活性的同时也造成了一些问题,比如增加了build的难度和依赖性,安装binary的时候也容易出现不兼容的问题。
另外,相较于FFmpeg,Gstreamer的内建codec也相对要少一些。
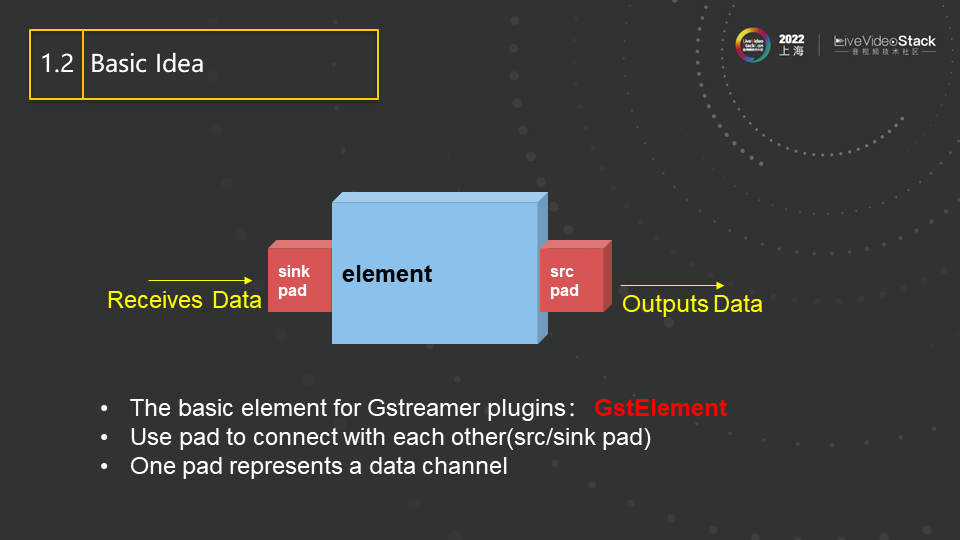
这是Gstreamer中一个element的基本形式。两端的pad来负责输入和输出,而由当中的element来完成具体工作。比如一个decoder,输入是H264的码流,输出则是decoded数据,也就是我们常说的视频帧,所以此处的element就可以实现为一个完整的H264的解码器。该解码器的实现可以是一个完整的内部实现,也可以封装已有的外部解码器来实现。比如,我们可以把OpenH264项目build成library的形式并适当封装,在此element中直接调用,从而实现该H264解码器插件的功能。
我们可以发现,这里的输入输出格式是非常随意的,甚至输入可以是video,输出是audio,这就使插件的设计有了更大更灵活的空间。比如我们录取了一个视频,视频里的每一帧都是拍的某本书的一页,于是我们可以设计这样一个pipeline,其中一个element将video转换成text,然后连接另一个element,其接受text输入,并用语音将其全部读出并输出audio,从而完成了将整本书转成audio的功能。这些element的设计方式在Gstreamer是被完全允许的。当然,FFmpeg也能完成上述功能,但在提交代码到社区和upstream过程中会有遇到很大的麻烦和挑战,因为这种video转text或者text转audio的模式,在FFmpeg中并没有现成的归类,也许需要你提出新的filter类型或新的模式。
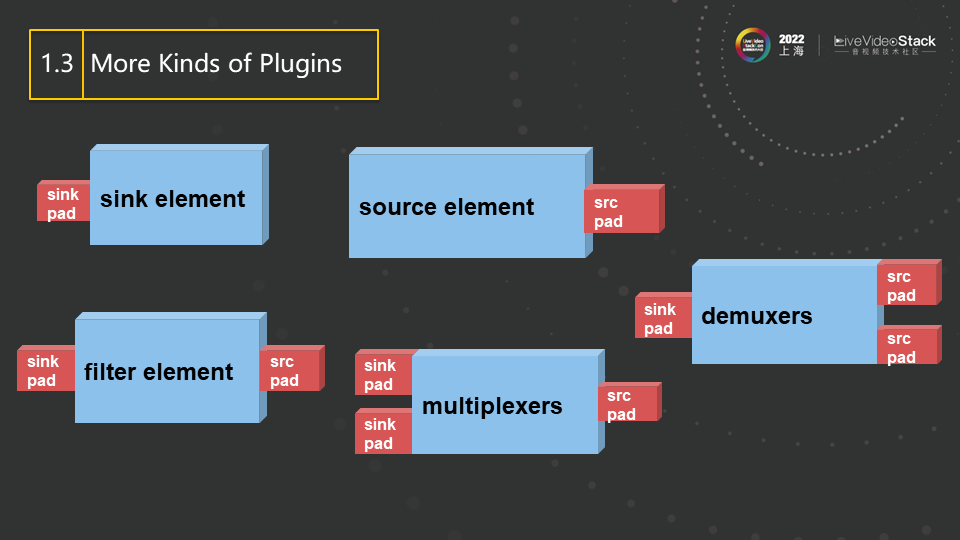
这是更多element的类型,demuxer对应FFmpeg里的av input format,source element对应于FFmpeg里的URL,用来产生源输入,filter element则对应于FFmpeg里的filter。总的来说,这些内容有与FFmpeg相似的地方,但是会以element的形式进行管理,最后用pipeline将这些内容连接在一起,由第一个向最后一个推送数据。
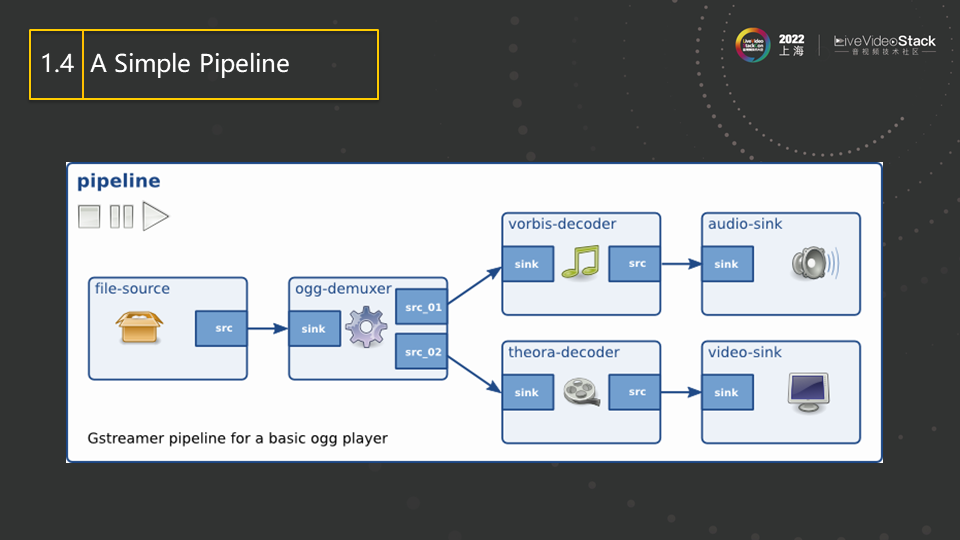
这是一个简单pipeline的例子,所有的element都会放在pipeline里面,然后由source发起数据并向demuxer(相当于FFmpeg里的av input format)推送,demuxer对数据进行解交织,然后一路传送audio,一路传送video,在各自经过decoder解码后,最后分别通过audio-sink来播放出audio,通过video-sink来播放出video。上述内容就是一个最经典、最简单的Gstreamer的pipeline,pipeline相当于一个大的容器,里面每一个元素都是element,也就是plugin(插件)。
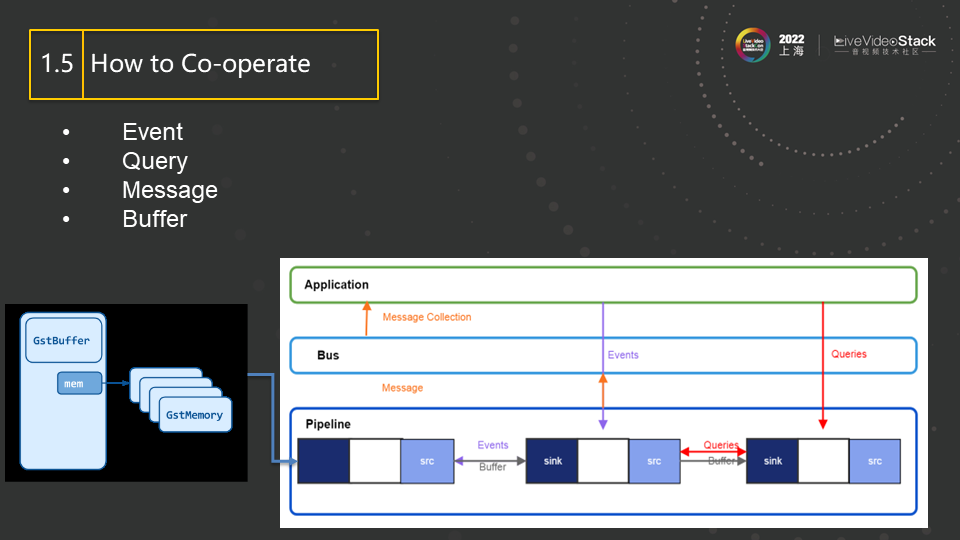
element之间是有交互的,上下游element之间可以通过Event(事件)来同步状态, 而通过query(询问)来同步信息。
举个Event的例子,有一种Event叫做EOS(End Of Stream),现在比如当前pipeline正在录制一个H264的视频,其中有两个element,上游是camera,下游是H264的encoder。由于encoder在编码过程中要产生reorder,所以camera采集的帧会被cache在encoder的stack里,而不会马上产生编码输出,直到一组GOP(Group of Pictures)完成, encoder才会统一为这一组GOP进行编码并产生输出。所以当camera采集完成最后一帧时,就需要发送一个EOS Event到下游,表示流已完成,不会再有后续帧产生。而encoder收到此Event后,即使最后一个GOP没有完成,也会将所有已经cache的帧进行编码,产生最后的编码输出,确保不至于漏掉最后几帧。
再举个例子来说明Query,若我们有一个display,可以在屏幕上显示 video(假设只支持RGB格式),而decoder的输出大多是NV12或者I420格式的。所以,我们要在decoder跟display之间接一个videoproc(video post processing视频后处理)的element来进行格式转换。在此,我们并不需要指定videoproc的输入输出格式,它会自动的通过query的方式询问上下游所支持的格式,从而判断出其要做一个NV12→RGB的格式转换。这种方式也就是Gstreamer里面的的自动协商。
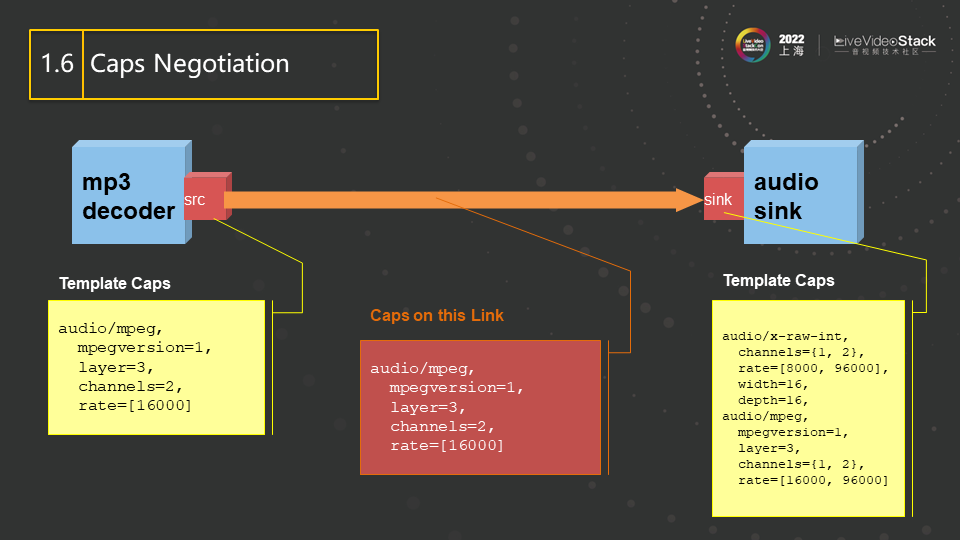
Gstreamer中的element之间参数自动协商的结果最后会表示成一个caps,中文称为能力,其内容可能包含分辨率,数据格式,帧率等等。比如一个音频播放器既支持原始audio格式又支持mp3压缩格式的播放,所以在它的caps中就有raw和mp3两个选项,表明它可接收这两种格式的输入。而decoder的输出格式是固定的,它由码流里的内容所决定。所以在连接这两个element时,要找到两者的交集,得到的结果就是最终所要传输数据的caps(即图中红色方框的部分),也就是两者协商一致的参数或参数集。如图中,协商结果为mp3格式、双通道、码率为16000的audio。自此以后,decoder需要向下游传输红色方框里规定格式的audio,不能自行改变。这种能力的自动协商,基本不需要用户的指定,而是由两个element之间自动协商完成。
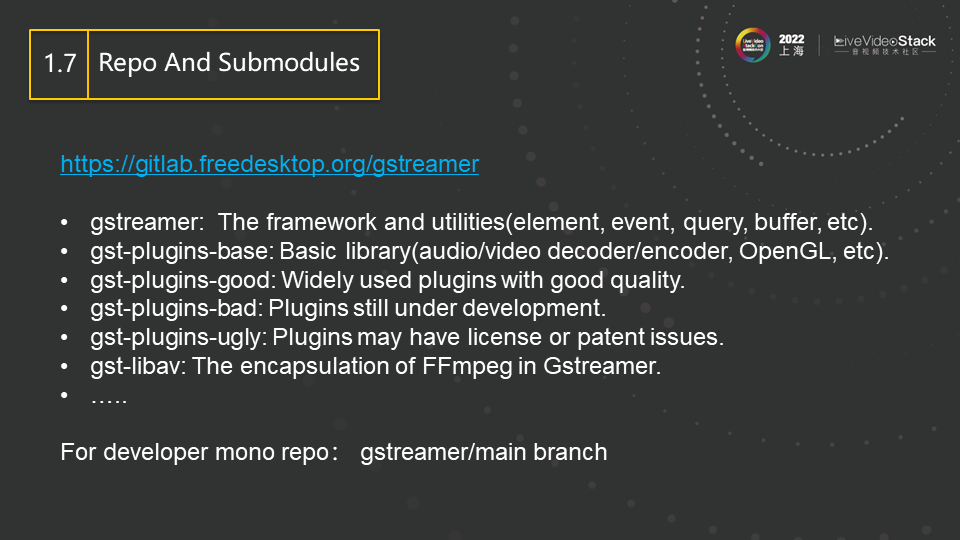
关于source code的分布结构,Gstreamer也采用了比较分散的方式,以方便插件的开发。与FFmpeg把所有的内容放在同一个repo里不同,Gstreamer将其各个模块根据功能分为了多个repo分别存放。其框架和基本库分别被方在gstreamer和gst-plugins-base这两个repo中,其他的repo存放各种插件,并只依赖于这两个repo,互相之间没有依赖。其中gst-plugins-good主要包含比较成熟的插件,gst-plugins-bad则主要包含正在开发的插件,gst-plugins-ugly不是指code质量差,而是主要放置了一些有license问题的插件,用户可以根据地域和法规,进行选择性的规避或安装。
经常会有人提到FFmpeg不能和upstream的code进行同步的问题。这是因为做具体工程时,我们的开发模式多是基于一个固定的FFmpeg版本做修改,而向社区回馈这些修改并被merge的难度又非常大, 所以就只能维护一个私有的FFmpeg repo并不停迭代。而与此同时,upstream的开发者也没闲着,不断的给官方的FFmpeg添加各种新的feature和bug fixing。双方从此分叉, 久而久之,等你再想rebase回到官方的FFmpeg,体验其新功能时,发现已经是不可能。相反,Gstreamer就可以有效的规避这一点。在开发一个新的插件时,开发者不需要在已有的repo里进行commit,而完全可以新建一个repo(甚至不需要开源)并由自己来维护,只要这个新建的repo依赖于刚才提到的两个基本库即可。而这两个基本库的升级是非常平稳的,兼容性也很好,因此可以随时进行升级,与最新的upstream保持同步。而由于所有的repo都只依赖于基本库,所以各个repo之间的插件可以无阻碍的进行协同工作,这就解决了用固定库做私有库的问题。
02 The video Processing And Hardware Acceleration

接着,我们介绍在Gstreamer里如何处理video。图中展示的是各种video相关的插件,主要分为八大类。
首先是demux,用于解交织,分开一个文件中的各路audio和video,它包括qtdemux,matroskademux等;mux与demux功能相反,用于加交织,比如matroskamux能将H264的video码流和AC3的audio码流根据时间戳交织在一起,形成MKV文件。
parse相当与码流过滤器,比如可以用它来找码流中帧的边界(对于decoder很重要,decoder多需要一个完整的帧数据来解码,而不是一帧中的部分slice)。另外,它也可以做一些码流语法层格式的转换,比如从DVD中的H264帧没有前导码,但空间或cable里传输的H264需要前导码进行同步,所以若想将当前空间传输里的码流录入DVD里或转成RTXP格式时,就需要用parse将其前导码去掉。
decoder和encoder即编解码器,不需解释。需要注意的是,Gstreamer除了有内建的encoder和decoder(即实现了一个完整的SW或HW decoder或encoder),其还经常通过包装和wrap一些现有成熟的codec project的方式来实现。比如FFmpeg就被包装成了一个插件, 图中展示的avdec_h265就是通过wrap的方式来使用FFmpeg中的H265 decoder,而openh264dec则是通过包装openh264工程得到。一些著名的encoder工程,比如x264和x265也被分别包装成了x264enc,x265enc插件。
postproc相当于FFmpeg里的filter,主要支持各种scale转换和color format转换,以及高斯滤波,锐化等操作。
render即渲染,可以理解为视频的输出。FFmpeg里的render支持较少(据我所知只有SDL),Gstreamer就对这部分进行了扩展,包括glimagesink(使用OpenGL的3D渲染),ximagesink(输出到X),waylandsink(输出到wayland)等,总体来说支持的比较完整。
其他还剩下一些杂项,包扩deinterlace(场帧处理)、videorate(帧率转换)和videocrop(视频截取)等。
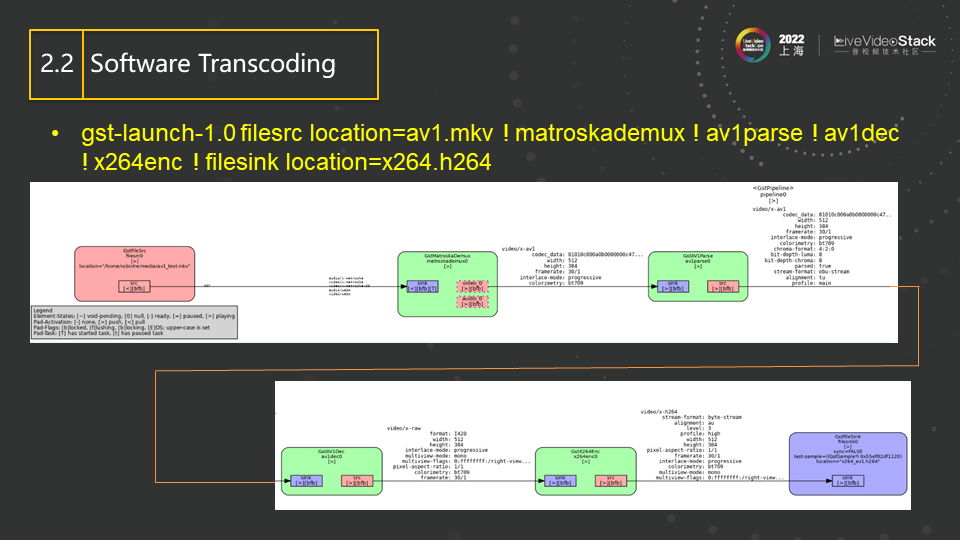
这是一个简单的软件转码的pipeline实例,其首先使用AV1的decoder将AV1的码流解出,然后使用x264enc将其压缩,最后保存为H264文件。该图是用Gstreamer自带的工具生成的,图中绘制了pipeline中的每一个element,element之间的关系以及element之间协商和传输的数据格式(即前面提到的caps)。

接着介绍基于硬件加速的Gstreamer的插件。首先来看VAAPI,VAAPI是由Intel提出的一套硬件加速API。MediaSDK则是对VAAPI的进一步封装,使用户更方便使用(MediaSDK也经常被称作QSV)。D3D11/12主要用于在Windows上提供加速。V4L2主要基于ARM平台,其硬件加速的driver通常会实现在kernel里。Vulkan是最近提出的,此外还有Cuda最近也补充了关于视频硬件加速的API。
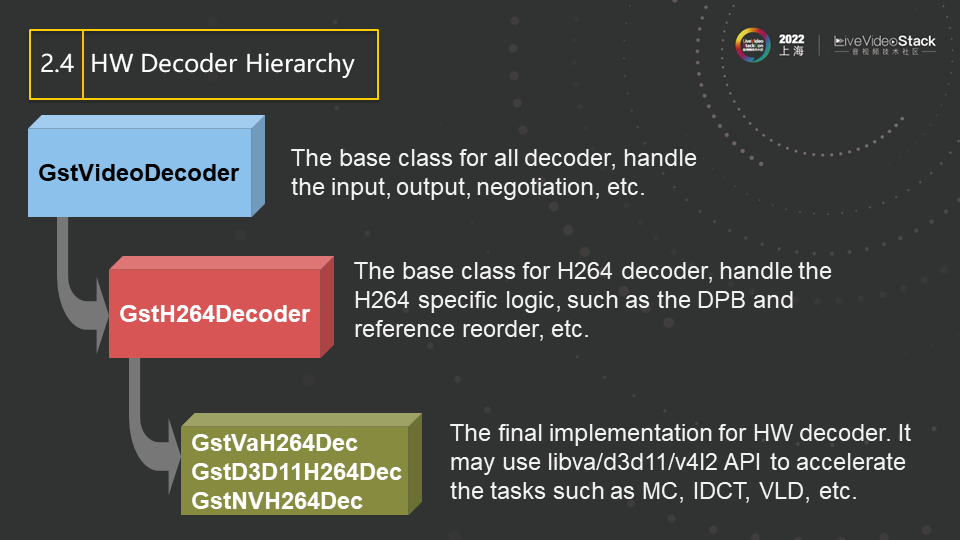
接着介绍一下硬件加速的具体实现。以decoder为例,一个完整的decoder,其大致可以分为状态维护(或者叫状态机)和解码运算两部分。状态维护包括比如SPS和PPS中参数的检测和设定,参考帧的维护和重排列,以及缺帧等常见错误的处理等, 而解码运算则包括比如VLD、MC等。前者逻辑性强但运算量很少,而后者逻辑性很少却要求大量的计算,所以,大多硬件加速的API设计都会针对后者,而把逻辑性较强的状态维护部分留给软件来实现。在Gstreamer中亦是如此, 并结合了面向对象的思想, 把所有decoder都需要的部分(比如输入输出管理,帧的cache机制等)放在基类中, 把H264特定的逻辑(比如H264的参考帧管理,Interlaced码流中上下场的管理等)抽象到H264 decoder中,而子类GstVaH264Dec、GstD3D11H264Dec和GstNVH264Dec则调用具体的HW加速API来进行解码运算部分的加速。
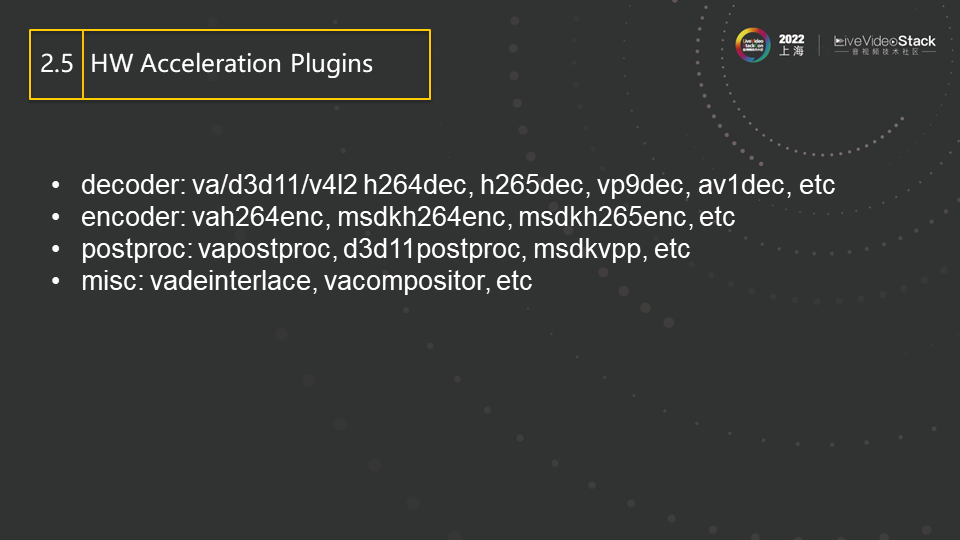
这些是Gstreamer里已有的硬件加速的插件,其囊括了几乎所有市面上流行的codec,如h264、h265、vp9,av1等。插件的名字一般采用 加速库名+codec名+功能 来命名。比如vah264dec就是基于VAAPI加速的H264 decoder。当然,除此之外,还有基于硬件的视频后处理插件vapostproc,vadeinterlace,以及多路视频复合插件vacompositor等。
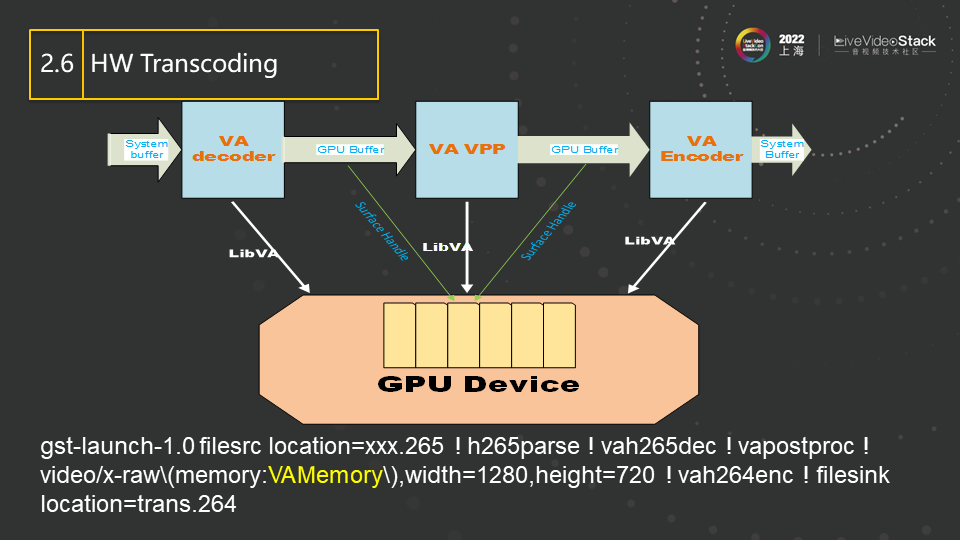
这张图说明Gstreamer在编解码过程中如何使用硬件。首先,decoder会将码流中需要解码的data从主存拷贝到GPU 的memory中,并驱使GPU运行解码运算生成解码图像(因此,生成的解码图像也自然就在GPU的memory中,我们也经常也叫surface)。之后的VPP(Video Post Processing)插件会以此surface作为源,在GPU上运行color conversion和scaling等算法,生成一块新的surface并送给encoder。最后,encoder同样会在GPU上运行编码算法,从而产生新的码流。图中的各个插件之间只传输GPU的surface handle,没有内存拷贝,这样就实现了整条pipeline在GPU上的全加速。
03 Use Gstreamer: Pipelines And Examples
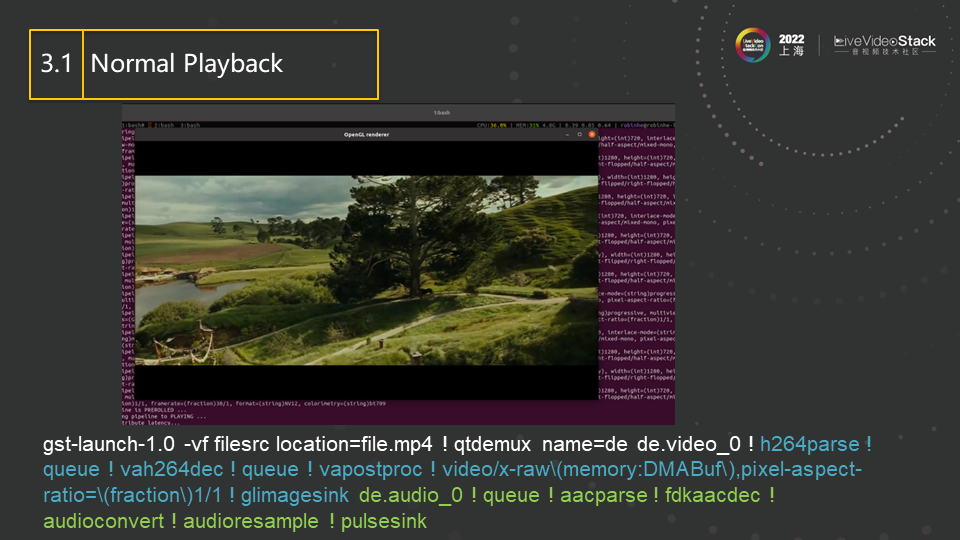
我们现在来举一些实际的Gstreamer的例子。首先是用命令行来放一个文件,视频输出下方即是该完整的命令行(一个完整的gst-launch也通常会被称为一个pipeline)。该文件是一个MP4格式文件,qtdemux会解交织该文件,送出两路数据,一路video(图中蓝色部分),一路audio(图中绿色部分)。

再看一个比较有趣的例子。identity(图中黄色部分)是一个比较有意思的插件,这个插件有一个属性是可以让其随意丢掉x%的数据。我们正好可以用这个插件来测试decoder的稳定性、鲁棒性。这里假定x是20,也就是丢失20%的帧。如图,因为部分数据有丢失,会造成部分解码错误或者reference帧丢失,所以解出有garbage的图像是在意料之中,也是可以接受的,但不能接受的是解码程序crash。图中是丢掉20%的数据的效果,若丢掉80%的数据,那会造成只有少部分图片残影被显示, 但同样的,一个稳定强大的decoder在此情况下依然不能crash。

这是一个称为crop的element/plugin,它可以用来做视频裁剪,图中右边的图像就是对左边的图像裁剪掉其左边的200像素和下边的81像素获得的。这个功能本省并不稀奇,这里需要注意的是,Gstreamer中,该videocrop插件会自动进行一些性能优化。在上面的命令行中,videocrop下游的vapostproc插件,在进行hue转换的时候,本身就可以设置src image的有效区域,而这就相当于进行了一次隐含的crop操作。所以,在此处,videocrop不会进行真正的crop操作,而是只把要crop的范围作为meta data传送给下游即可。这种智能的性能优化,也正是通过query机制,询问下游的能力而做出的。
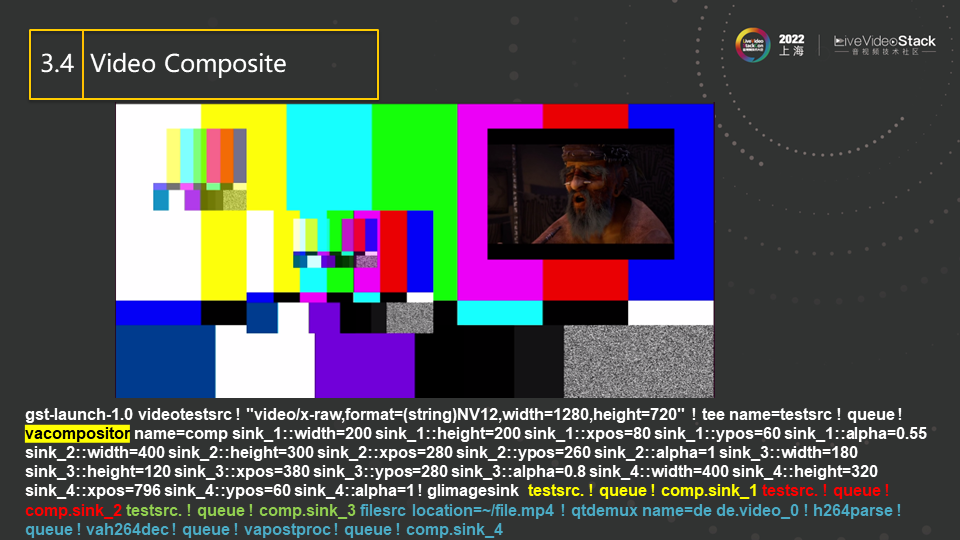
这是之前提到的compositer插件,它的功能就是能将各路video交织到一起。图中一共有五路video被合并到了一起。我们可以指定每一路的位置、alpha值和分辨率,让其出现在我们想要的位置。命令行中,第一路没有显式指定参数,所以其会整屏显示,也就是该图的底图,而黄色内容表示第二路,红色内容表示第三路,绿色内容表示第四路,蓝色内容表示第五路,其中第五路是video解码输出。各路输出的位置如图中所示。显然,compositer很适用于安防的监控场景,将每个摄像头的内容组合拼接到一起,即多输入单输出,即可得到一个经典的安防监控画面。
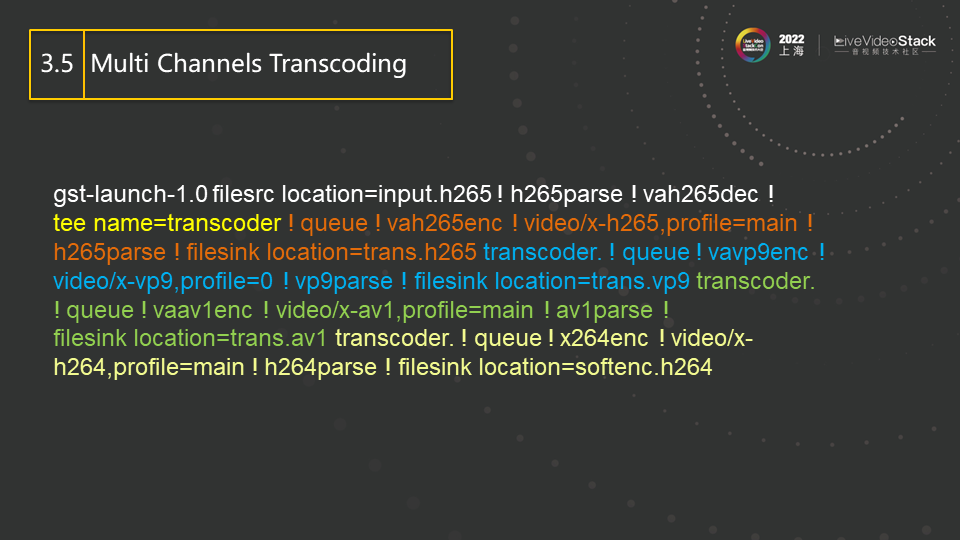
这是一个多channel转码的例子。H265的解码(黄色部分)的输出会被插件tee以只读的方式分别送给4路encoder,分别是使用VAAPI加速的H265编码器(橙色部分),使用VAAPI加速的VP9编码器(蓝色部分),使用VAAPI加速的AV1编码器(绿色部分)和软件的x264的编码器。这条pipeline可以同时完成1对4的转码,而解码只需一次,比较省资源。

这是一个使用DL Streamer进行人脸识别的例子。其中蓝色方块表示DL Streamer的插件。完成decode后,DL Streamer的插件会做face detection、age/gender classification、 emotion recognition(即识别表情、年龄)等,然后会做watermark,其将传输下来的前面每一级识别的信息数据画上去,最终传给display进行显示。Gstreamer的方便之处在于,可以随意添加、删除或修改上述流程中的任一级,比如在脚本里删掉face detection或emotion recognition,就不会再做face detection或emotion recognition。
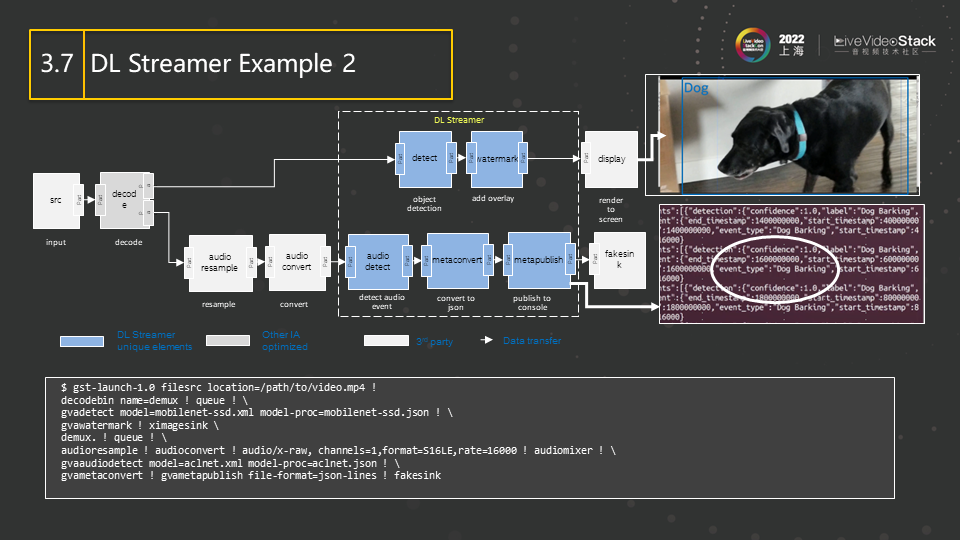
这是一个识别audio的例子。完成decode后,经过audio resample和audio convert这两个基本的audio处理,然后将内容传送给audio detect等deep learning插件,最后识别出来图中是狗在叫。完成decode后的另一路会做object detection,识别出狗的大概位置,然后将狗框出。这是一个用Gstreamer搭建的典型的带有deep learning的pipeline,可以对其进行扩展。
04 Our Job and The Future Trend
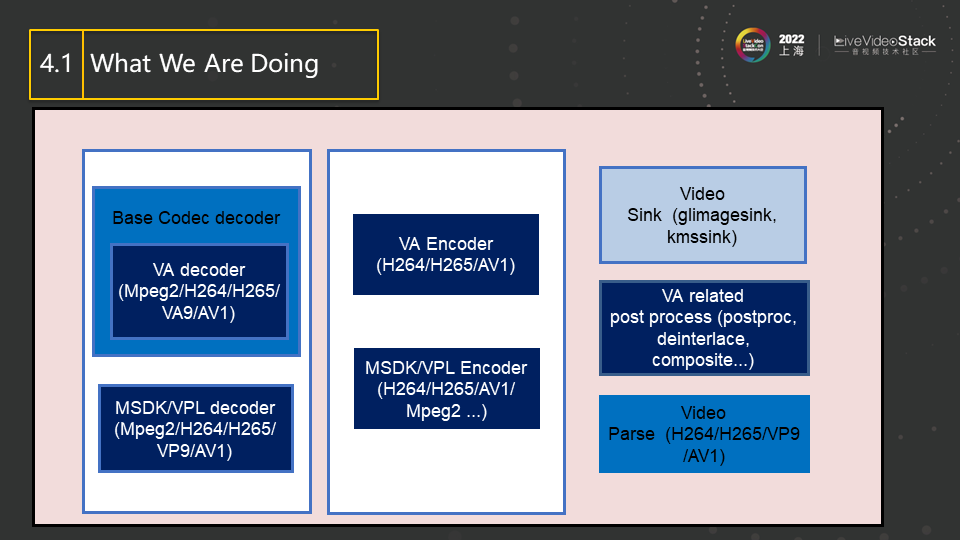
最后介绍一下我们团队目前的工作。我们首先还是会关注Gstreamer的在codec方面的开发,也会为Intel的硬件提供更好的加速插件,其他的部分比如rendering等也会有比较多的涉及。图中蓝色方块表示我们在Gstreamer的open source社区直接负责的element,方块的颜色越深表示我们对其的掌控力越强,表示其由我们主导。方块的颜色越淡表示我们对其的掌控越弱,比如有些需要和其他公司合作开发等。之前提到的DL Streamer还未提交到upstream,而是存放在另外一个repo中。由于Gstreamer模块化和易扩展的特点,其可以随时与最新的Gstreamer同步, 并和其他插件进行良好的协同工作。
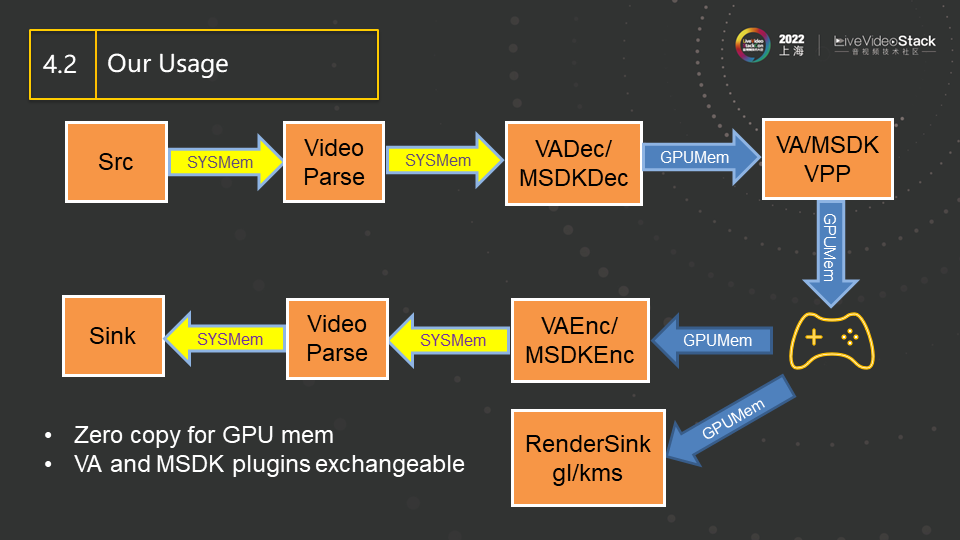
该图是我们想要实现的目标,可称之为PCI Copy Free(不需要在CPU和GPU之间进行任何video相关的数据拷贝)。即图中蓝色箭头部分,无论是运算还是memory都应在GPU侧,而不应再出现在CPU侧。
图中,在decoder解出video后,所有的image和对image的处理都应该在GPU端发生,比如图中的VPP(Video Post Processing),encoder等。手柄表示可以插入用户自己想要的插件,完成特定功能。比如可以用3D/OpenGL的插件在video上画水印,画图等,也可增加deep learning的插件来做深度学习。生成完自己想要的内容后,可以再通过encoder进行压缩,或者直接将内容在屏幕上进行渲染。我们的目标是使得这些插件能完全协同工作在GPU上,这个目标是有一定挑战的。

这是下一步我们要做的内容,AI预分析的encoder。比如,在encode之前,可以用deep learning 的插件来找出图中的关注点。如图所示,我们关注的不是图中的花草,而是运动员是否能跳过栏杆,所以我们需要将更多的码率放在热点上(此处是人身上),而非其他部分(比如背景的花花草草上)。而这些作为背景的植物,其细节又比较多,在编码时容易产生较多残差,反而会占用比较多的码率。所以, 在编码时,我们应该给热点区域设定更小的QP(H264术语,可以理解为更好的质量),从而把更多的码率分配给关注的热点,这样运动员的部分就能更清晰,观众的主观观感就会更好。要实现以上方案,就需要在encoder之前,插入deep learning 的插件,分析出热点区域。
以上就是本次分享的全部内容,谢谢大家!
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。