
用户生成内容(UGC)的视频质量评估是工业界和学术界的一个重要话题。大多数现有方法仅关注感知质量评估的一个方面,例如技术质量或压缩失真。本文创建了一个大规模数据集,以全面地探索 UGC 视频的质量特征。除了数据集的主观评分和内容标签之外,本文还提出了一个基于 DNN 的框架来彻底分析内容、技术质量和压缩程度在感知质量中的重要性。模型能够给出视频的质量评分以及三类质量指标,很好的建立了人类对视频质量的感知与视频本身某些量化指标之间的联系。
来源:Google Research
题目:UVQ: Measuring YouTube’s Perceptual Video Quality
作者:Yilin Wang, Feng Yang
原文链接:https://blog.research.google/2022/08/uvq-measuring-youtubes-perceptual-video.html?m=1
UVQ模型链接:https://github.com/google/uvq
内容整理:李雨航
背景
YouTube 等在线视频共享平台需要了解感知视频质量(即用户对视频质量的主观感知),以便更好地优化和改善用户体验。视频质量评估(VQA)试图通过使用客观的数学模型来模拟用户的主观意见,建立视频信号和感知质量之间的联系。传统的视频质量指标,例如峰值信噪比 (PSNR) 和视频多方法评估融合 (VMAF),都是基于参考的,重点关注的是目标视频和参考视频之间的相对差异。这些指标很适合专业生成的内容(PGC),例如电影等。它们假设参考视频具有原始质量,并从相对差异中推断出目标视频的绝对质量。
然而,YouTube 上上传的大多数视频都是用户生成内容(UGC),由于视频内容和原始质量的高度不确定性,我们面临着新的挑战。大多数 UGC 上传都是非原始的视频,一样大的相对差异可能意味着完全不同的感知质量。例如,与低质量上传的失真相比,人们对高质量上传的失真更敏感。因此,基于参考的质量评价在 UGC 情况下变得不准确且不一致。此外,尽管 UGC 数量很大,但目前带有质量标签的 UGC-VQA 数据集有限。与具有数百万用于分类和识别的样本的数据集(如 ImageNet 和 YouTube-8M)相比,现有的 UGC-VQA 数据集要么规模较小(如 LIVE-Qualcomm 有从 54 个特定场景捕获的 208 个样本),要么没有足够的内容多变性(不考虑内容信息的采样,如 LIVE-VQC 和 KoNViD-1k)。
在 CVPR 2021 上发表的 “Rich Features for Perceptual Quality Assessment of UGC Videos” 中,我们描述了如何尝试通过构建类似于主观质量评估的通用视频质量模型(UVQ)来解决 UGC 质量评估问题。UVQ 模型使用子网络从高级的语义信息到低级的像素失真来分析 UGC 质量,并提供可靠的质量评分(利用全面且可解释的质量标签)。此外,为了推进 UGC-VQA 和压缩研究,我们增强了开源的 YouTube-UGC 数据集,其中包含来自 YouTube 上数百万个 UGC 视频的 1500 个代表性 UGC 样本。更新后的数据集包含原始视频和相应转码版本的真实标签,使我们能够更好地理解视频内容与其感知质量之间的关系。最后,我们发布了 UVQ 模型的开源版本。
主观视频质量评估
为了了解感知视频质量,我们利用内部众包平台收集 MOS 评分,范围为 1-5,其中 1 是最低质量,5 是最高质量。我们从 YouTube-UGC 数据集中收集真实标签,并将影响质量感知的 UGC 因素分为三个高级类别:内容、失真和压缩。例如,没有有意义内容的视频将不会获得高质量的 MOS。此外,视频制作阶段引入的失真以及第三方平台引入的视频压缩失真(例如转码或传输)也会降低整体质量。
我们发现MOS= 1.242 一段模糊的游戏视频获得了低 MOS,甚至低于没有任何有意义内容的视频。一种可能的解释是,观众可能对具有清晰叙事结构的视频(例如游戏视频)有更高的视频质量期望,而压缩失真会显着降低视频的感知质量。
UVQ 模型框架
评估视频质量的常用方法是设计复杂的特征,然后将这些特征映射到 MOS。然而,即使对于领域专家来说,设计一个有用的手工特征也是困难且费时的。此外,现有的最有用的手工特征是从有限的样本中总结出来的,在更广泛的 UGC 案例中可能表现不佳。相比之下,机器学习在 UGC-VQA 中变得更加突出,因为它可以自动从大规模样本中学习特征。
一种简单的方法是在现有 UGC 质量数据集上从头开始训练模型。但因为质量 UGC 数据集有限,这种方法不太可行。为了克服这个限制,我们在训练 UVQ 模型过程中加入了自监督学习步骤。它能使我们能够从数百万个原始视频中学习全面的质量相关的特征,而无需真实的 MOS。
根据主观 VQA 总结的质量相关的分类,我们开发了具有四个新颖子网络的 UVQ 模型。前三个子网络,我们称为 ContentNet、DistortionNet 和 CompressionNet,用于提取质量特征(即内容、失真和压缩),第四个子网络称为 AggregationNet,用以将提取的特征映射生成质量评分。ContentNet 采用监督学习方式进行训练,并使用 YouTube-8M 模型生成的 UGC 特定内容标签。DistortionNet 经过训练可以检测常见的失真,例如原始帧的高斯模糊和白噪声。CompressionNet 专注于视频压缩失真,其训练数据是按不同比特率压缩的视频,它利用同一内容的两个压缩变体进行训练,这些变体被馈送到模型中以预测相应的压缩级别(对于更明显的压缩失真,压缩级别越大)。
ContentNet、DistortionNet 和 CompressionNet 子网络在大量没有真实质量评分的样本上进行训练。由于视频分辨率也是一个重要的质量因素,因此分辨率敏感的子网络(CompressionNet 和 DistortionNet)是基于块的(即每个输入帧被分为多个不相交的块并单独处理),这使得我们可以在原始分辨率上捕获所有细节,而无需缩小尺寸。这三个子网络提取质量特征,然后由第四个子网络 AggregationNet 连接起来,并结合来自 YouTube-UGC 的真实 MOS 来预测质量评分。
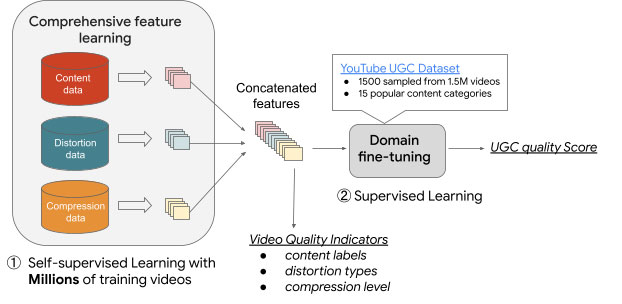

使用 UVQ 分析视频质量
构建好 UVQ 模型后,我们用它来分析从 YouTube-UGC 中提取的样本的视频质量,并证明其可以提供质量评分以及单一质量指标得分,从而帮助我们了解视频质量的具体问题。例如,DistortionNet 检测到下面第1张图片所示的多种失真,例如抖动和镜头模糊,而 CompressionNet 检测到第二张图片所示已被严重压缩。


此外,UVQ 可以提供基于块的反馈来定位质量问题。对于下面这一段视频,UVQ 报告第一个块(t = 1 时刻)的质量良好,压缩级别较低。然而,该模型在下一个块(t = 2 时刻)中识别出严重的压缩失真。
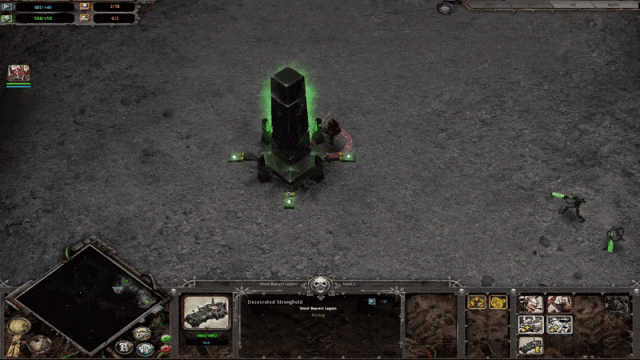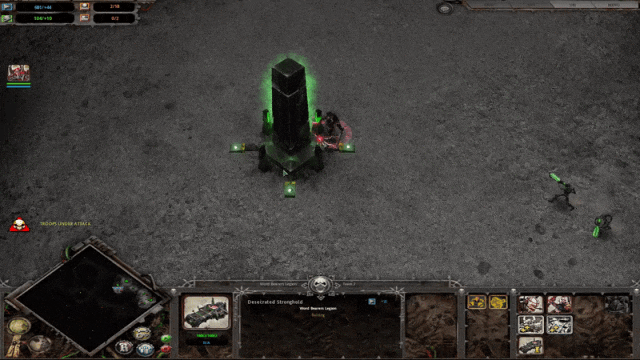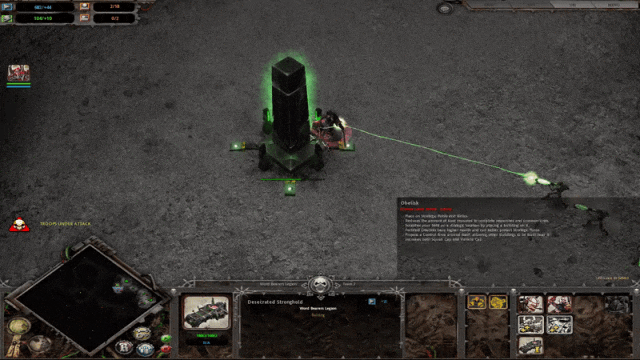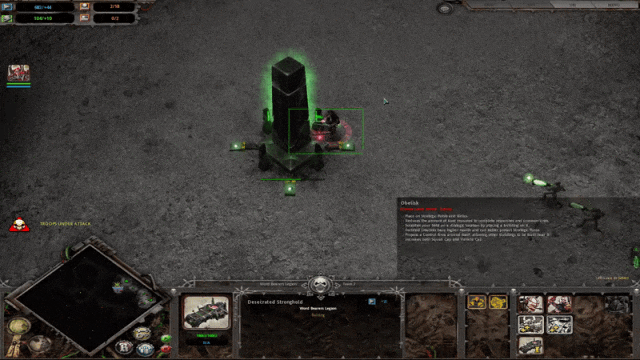

在实际应用中,UVQ 可以生成视频诊断报告,其中包括内容描述(例如策略游戏)、失真分析(例如视频模糊或像素化)和压缩级别(例如低压缩或高压缩)。以下面的视频为例,UVQ 报告称,从各特征来看,内容质量良好,但压缩质量和失真质量较低,三者结合,整体质量为中低。我们看到这些结论与内部用户专家总结的很接近,表明 UVQ 可以通过质量评估进行推理,同时提供质量评分。
总结
我们开源了 UVQ 模型,该模型会生成一份包含质量评分和见解的报告,可用于评价 UGC 视频感知质量。UVQ 从数百万个 UGC 视频中学习全面的质量相关特征,并为无参考和参考案例提供一致的质量视角。要了解更多信息,请阅读我们的论文或访问我们的网站以查看 YT-UGC 视频及其主观质量数据。我们也希望增强的 YouTube-UGC 数据集能够促进该领域的更多研究。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。