
本文介绍上海交通大学宋利教授带领的 medialab 实验室最新发表在ACM TOMM的工作,基于混合时域对齐及局部双向循环的视频去模糊方法。在该论文中,我们提出了一个用于视频去模糊的局部双向循环网络。该方法采用全局前向循环以及局部的后向循环,有效地利用双向信息进行帧重建。同时构建一个融合的时间域合并模块,该模块结合了基于流和基于核对齐方法的优越性。
来源:ACM TOMM 2023
作者:Chen Li, Li Song, Rong Xie, Wenjun Zhang
论文链接:https://dl.acm.org/doi/10.1145/3587468
整理:煤矿工厂
背景
在视频的采集过程中,如果手持设备快速抖动或者镜头内物体快速移动,通常会使得图片产生运动模糊。现有基于深度学习的视频去模糊模型架构主要分为两类:迭代结构和循环结构。迭代结构利用滑动窗作为帧输入,逐步移动到视频的尾帧,这种结构的“视野”可能受限,无法准确提取利用到间隔更长帧的信息。而循环结构则类似于循环神经网络,则能够利用到较为长期的信息关联。
本文以循环网络为骨干进行模型构建,主要面对两个问题:
- 时间域对齐的性能,目前的循环框架一般只利用卷积层来进行隐状态的对齐。这种结构有助于提高模型运行的效率,但却可能无法有效处理模糊视频中相对复杂的运动;
- 未来帧特征的利用和融合,大多的循环骨干网络仅仅使用前向连接,这样无法利用到未来帧可能提供的信息。
关于第一点,我们考虑利用显式的运动信息进行帧间匹配。具体来说,我们融合了基于流及基于核的帧间匹配方法的优势,构建了一个融合的时间域对齐模块。基于流的方法有助于处理及融合相对大尺度的运动,但是模糊的输入可能会混淆运动估计的过程,极大影响流估计的准确性。基于核的方法则可以通过保持图像结构相对完整来缓解失真。对于第二点,为了有效地利用来自未来帧的特征,我们在全局的前向循环连接骨干之上,在局部窗口中引入了局部的反向循环连接。同时,为了降低计算成本,我们在较低的分辨率下计算运动信息,并且使用多尺度的结构来逐步细化特征。
方法简述
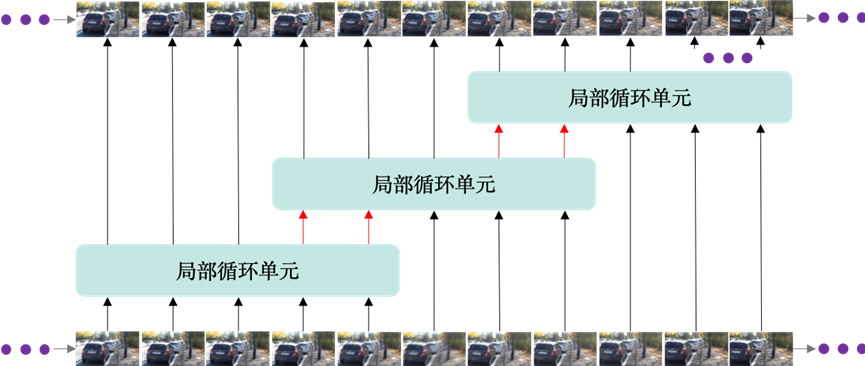

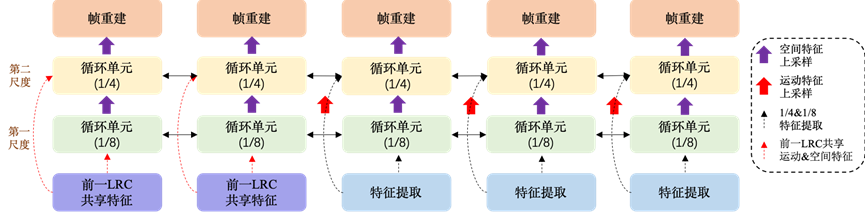
图1展示了本章中去模糊网络的结构图,而图2与图3则展现了各模块的详细网络构成。从图1来看,全局循环的骨干架构由连续的局部循环单元(LRCs)组成,这些单元也是我们所提出方法的基本单元。每个LRC均采用5个帧作为输入,并且预测相对应的五个清晰帧。相邻的两个LRC单元具有两个重叠帧,靠后的LRC输入包含上一个单元前两帧在循环网络中提取的特征以及三个新帧的特征。图5-4则展示了LRC的结构,除了前两帧之外,通用框架中均包含一个特征提取模块,一个帧重建模块,以及两个以全分辨率的1/8(第一尺度)和1/4(第二尺度)尺度上所使用的循环单元。
局部双向循环机制
每一个局部循环单元(LRC)由5个帧作为输入。如图1所示,给定五个输入帧,局部双向循环的基本结构如下所述。我们首先不考虑LRC之间的特征共享,只考虑每个LRC单元中的内部结构特征。我们在该框架的早期阶段引入了一个特征提取模块,生成两个尺度的特征图作为第一和第二尺度中循环单元的输入,我们选择提取的特征中两个较低分辨率尺度的特征作为后续一系列循环模块的输入。
在第一个循环单元中,我们利用当前帧特征和邻近帧特征,首先在全分辨率1/8的尺度上生成清晰的空间特征和运动信息。然后,我们对这些特征进行上采样,以便适配第二尺度中循环单元(RU)的输入要求。在第二个循环单元上,网络利用包含上采样空间特征和运动信息的原始特征来生成更加细化的特征。得到了修复后的特征,帧重建模块可以对特征进行上采样并且合成最终的清晰帧。
循环单元的详细结构展示在图3(a)中。每一个循环单元均包含一个前向循环单元(FRU)和一个后向循环单元(BRU)。在每个尺度上,其特征首先经过前向循环单元以及反向循环单元来生成得到空间特征以及运动特征,前向循环单元的空间特征则进一步被视为反向循环单元的输入。同时,翻转的运动特征也被设置为反向运动估计以及更高分辨率前向运动估计的先验。之后,将反向单元的输出特征上采样并翻转作为第二个尺度的参考特征,而两个尺度的结构和流程相似。
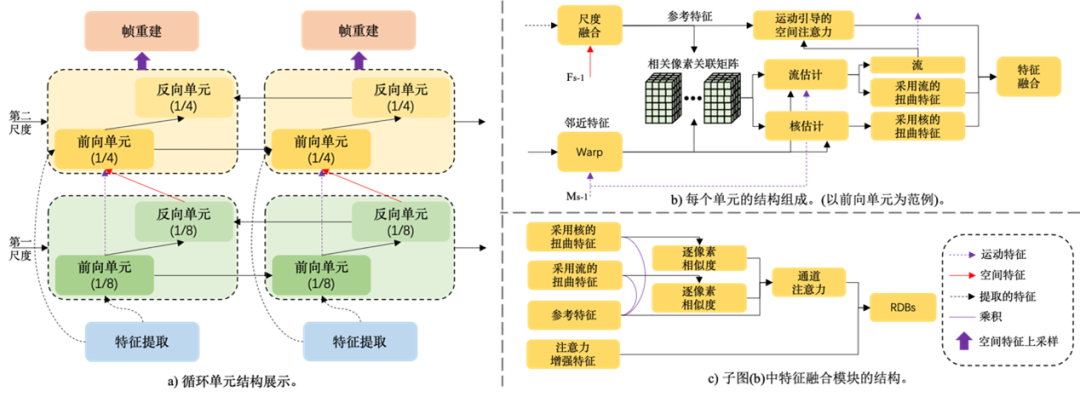
混合的时域对齐模块
我们提出融合模块的详细结构可见于图3(b)和图3(c)中。不同单元的网络结构构造相似。我们以第二个尺度中的前向循环单元为例,给定第一个尺度中的运动流先验和空间特征。我们首先采用尺度混合模块将参考特征以及上采样的空间特征混合。之后我们使用上采样的运动流先验对邻近帧特征进行扭曲。将扭曲后的邻近帧特征与当前帧特征相组合,我们能够进一步估计出相关像素关联V。而V通过相邻帧的空间特征在每个像素的邻域Ω内相乘来计算得到。V被用于估计残余的粗模糊流以及扭曲核。
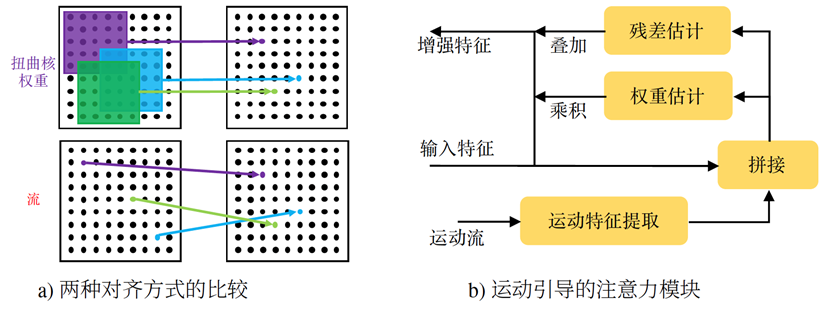
正如图4(a)所示,基于核的扭曲方法使用加权和的方式将邻近帧的局部特征迁移到当前帧上,而基于流的特征匹配方式则通过“一对一”的映射方式来进行特征迁移。在预先扭曲的特征上应用基于流及基于核的方法,我们能够得到两种类型的对齐特征。之后,将残差运动流添加在运动流先验之上以得到细化之后的流。
除此之外,只使用基于扭曲的方法可能因为对模糊帧的不准确运动估计而诱发形变。图像帧中的轮廓,特别是运动区域的边缘,应被进一步强调以增强空间特征。因此,我们采用运动引导的空间注意力模块(MGA),如图4(b)所示。MGA从细化的运动流以及增强的空间特征中估计一个调制系数和残差信息。
如上所述,我们获取了三种类型的信息:采用流的扭曲特征,采用核的扭曲特征以及注意力增强的特征。我们使用当前输入帧的特征作为参考,并且在参考特征及扭曲的特征之间利用单层卷积来估计注意力掩码。在与该注意力掩码相乘之后,基于核的扭曲特征,基于流的扭曲特征以及参考帧特征通过通道注意力机制来进行融合。
损失函数
本实验的损失函数包含两项,L1_Charbonnier损失以及频率域损失函数。
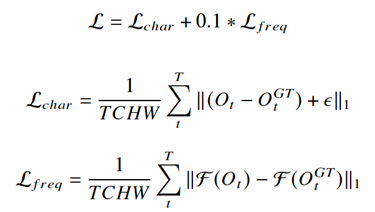
模型效果
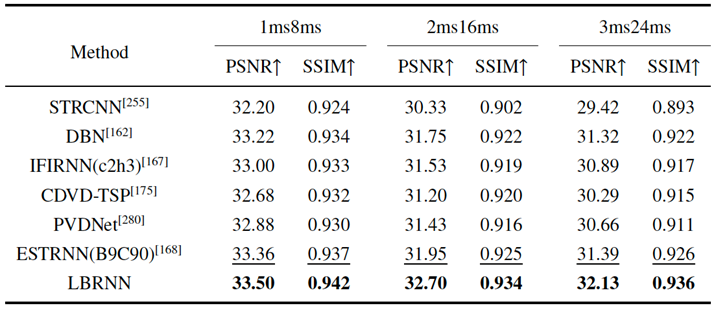
这里展示我们的模型在GOPRO数据集上的一些效果,如表1和图5所示。对比之前的一些方法,我们的方法(LBRNN)可以大幅提升去模糊的性能,并且降低模型的效率。


我们也在真实模糊数据集BSD上进行了训练测试,该数据集根据曝光时间配置分为三个子数据集。其中,曝光时间越短的子数据集质量越好。从表2及图6可以看出,我们的方法在不同配置下均大幅提升了去模糊性能。

模型分析
我们针对不同损失函数以及各个模块的配置进行实验,实验结果如表3所示。频率域损失,基于流以及基于核的warping方式还有MGA模块均为所提出模型带来了一定增益。

此外,我们还探究了基于流以及基于核的warping方式对模型的具体影响。如图7所示,基于流及基于核的方式分别对于较大尺度的运动及小尺度运动产生有利影响。而混合的方式则有效结合了两种方式的优势,在每种场景均得到最优的结果。最后我们也提供了一段去模糊的效果视频来说明本方法的有效性。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。