
2021年12月,Semiotic成为Graph的第四个核心开发团队。虽然我们的章程是专注于利用研究为 Graph 带来新的人工智能 (AI) 和密码学功能,但在为协议做出贡献时,我们也有一种应用和以影响为导向的心态。我们通过在Graph Network 上运行索引器来做到这一点,这需要专门的 DevOps 技能,并且我们从 2021 年初开始运行具有竞争力的索引器semiotic-indexer.eth 。此外,我们还利用我们的 AI 专业知识发布了两个自动化软件 Graph 生态系统的工具:AutoAgora 和 Allocation Optimizer。
这篇文章概述了我们过去和当前的 AI 工作,并概述了未来如何将 Graph 独特的数据索引功能用于 AI 应用程序的想法。
Graph 是一种去中心化协议,用于索引区块链数据并使其可用于下游应用程序的查询,例如 dapp 前端、图表、仪表板或数据分析。Graph 中有许多 AI 的用例。迄今为止,Graph 中的主要人工智能用例是部署用于自动决策的工具。一个新兴的人工智能用例是降低进入门槛,以访问由Graph 索引的丰富的 web3 数据。我们将主要关注前一个用例——在 Graph 中使用 AI 实现自动化。
Graph 和一般的去中心化协议使用激励机制来鼓励协议参与者以最佳和诚实的方式行事。激励机制是对期望行为的奖励——这是行为经济学的一个概念。例如,在Graph 中,消费者通过支付 GRT 来激励索引器为查询提供服务。Indexers、Curators、Delegators 和 Fishermen 也存在类似的机制,他们都有激励机制来指导他们的行为。
构建去中心化协议的一个含义是决策制定从中心化实体(例如公司)转移到协议中的参与者。在 Graph 的背景下,去中心化导致参与者需要做出许多复杂的决定。Semiotic Labs 使用人工智能和相关技术来部署工具,以简化协议参与者的决策过程。我们为两个 AI 相关工具的开发做出了贡献:AutoAgora 和 Allocation Optimizer。这两种工具都有助于索引器提高协议性能和收入。
汽车市场
Graph 的核心目的是为用户提供查询服务。在一个简化的场景中,该协议涉及多个索引器(数据卖家)、消费者(数据买家)和网关。当客户向多个网关之一发送查询时,网关会根据索引器的出价、服务质量 (QoS)、延迟等各种因素在索引器之间分发查询。索引器通过提供查询来赚钱,同时可以自由控制他们所服务的查询的价格。这个过程如下图所示:


索引器以模型的形式表达对各种 GraphQL 查询的出价,该模型以称为 Agora 的特定领域语言定义。Agora 价格模型将查询映射到它们在 GRT 中的价格,即为给定索引器执行查询的数量提供具体价格。然而,为每个子图创建和更新 Agora 模型可能是一项繁琐且耗时的任务,因此许多 Indexer 使用静态的、扁平的定价模型。
为了帮助索引器定价并确保他们遵循查询的市场价格,Semiotic Labs 创建了一个名为AutoAgora的开源工具。AutoAgora 使创建和更新 Agora 价格模型的过程自动化,使索引器更容易提供反映服务特定查询形状的实际成本的动态定价。简而言之,对于希望在Graph Network 上为其查询服务提供更具竞争力和灵活定价的索引器,AutoAgora 是一个有用的工具。
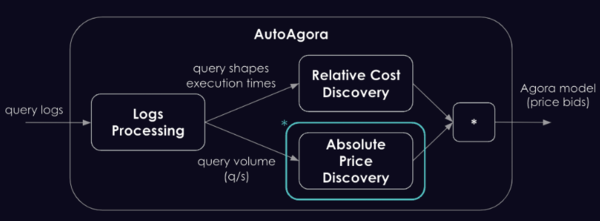
如上所述,AutoAgora 由多个模块组成,这些模块协同工作以自动化创建和更新 Agora 价格模型的过程。这些模块包括:
- 日志处理:解析日志以提取传入的查询、它们的形状和执行时间;
- 相对成本发现:将相似的查询形状分组并计算它们的资源使用统计数据(例如平均执行时间);
- 绝对价格发现:试图通过根据过去提供的查询量调整价格来最大化收入。
我们在绝对价格发现模块中使用了 AI,如上图中的红框所示。这个模块实现了一种用于强化学习的可训练的随机代理。在定价查询的context中,代理的策略表示为可能查询价格的高斯分布,代理采取的操作是从该策略分布中采样的。一旦采样,价格用于更新 Agora 模型,随后发送到几个网关之一。从所有的技术复杂性中抽象出来(并简化了很多),bandit 用于更新其策略的逻辑可以描述如下:如果运行 AutoAgora 的索引器服务量很大,那么价格应该提高,如果有没有查询服务,那么显然价格太高了。
分配优化器
Graph Network 目前部署了 750 多个子图。在消费者可以进行子图查询之前,索引器必须“同步”与子图相关的区块链数据,然后将 GRT 分配给子图。同步子图然后提供查询是一项非常耗费资源的任务,因此索引器通常不会同步所有子图。实际上,Graph网络看起来类似于下图,索引器仅分配给许多可能的子图中的一些:
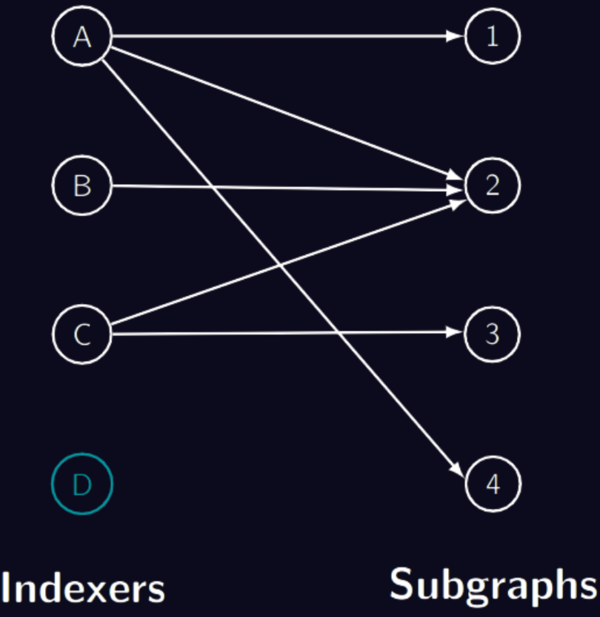
索引器如何知道它们应该分配给哪些子图?这就是策展人的角色。策展人在子图上发出(临时存放)GRT。如果特定子图的查询费用增加,策展人自己会得到奖励,因此理性的策展人会尝试向查询费用高的子图发出信号。相应地,协议经济学将索引器推向高查询费用子图,以便它们为这些查询提供服务。通过遵循信号,索引器将以查询费用结束在子图上。然而,分配问题并不那么容易。如果所有索引器仅索引具有最高信号的子图,它就不会工作。如果是这种情况,则不会提供其他子图。因此,索引奖励奖励索引器位于具有高信号的子图上,但也会因为他们位于已经有很多其他索引器分配的股份的子图中而受到惩罚。为了找出索引哪些子图,索引器必须遵循索引奖励,而不是信号。
对于许多索引器来说,遵循索引奖励是非常重要的。事实上,完整的问题原来是优化一个子模块函数,这在学术文献中仍然没有解决的问题。Allocation Optimizer是一种用于索引器的开源工具,它至少起到了一定作用。该工具将当前管理状态、其他索引器的现有分配、特定索引器可用的 GRT 数量以及 Gas 成本作为输入。然后该工具代表索引器解决优化问题。分配优化器的输出是对索引器的建议。该建议包括应分配给哪些子图以及分配多少。
分配优化是一个困难的数学问题,但解决数学问题本身并不能改进协议。通过为索引器提供一个可以计算其最佳分配的工具,我们可以增加他们的索引奖励收入并释放他们的一些时间,以便他们可以专注于为子图查询提供高质量的服务。
AI和Graph的未来
到目前为止,在这篇文章中,我们重点介绍了目前部署用于 The Graph Network 的 AI 相关工具。但是 The Graph 还能如何利用 AI?而且,从另一个角度来看,AI 构建者如何利用 The Graph?
ChatGPT 的发布是 AI 的 iPhone 时刻——它是一种使 AI 访问民主化的工具。ChatGPT 是更广为人知的大型语言模型 (LLM) 的品牌名称。LLM 在总结和合成文本数据方面非常强大。它们也可以用于处理数值数据,但让法学硕士正确地做数学仍然是一个新兴的研究领域。我们已经启动了一个试点项目,使用 LLM 来访问和总结 The Graph 的大量信息。具体来说,我们将使任何对 web3 数据感兴趣的人都能够使用自然语言直观地访问它。请继续关注更多详情。
AI 构建者如何利用 Graph?一种方法是使用Graph 的数据来训练新的 AI 模型。可能听说过训练神经网络需要大量数据,而这正是我们在Graph 中所拥有的。此外,如果有计算机科学背景,可能听说过“垃圾输入,垃圾输出”,这是指错误的输入应该提供错误的输出这一事实。ChatGPT、GPT-4 和其他 LLM 存在“输入垃圾,输出垃圾”的问题,因为它们是根据互联网的大部分公共(因此是虚假或矛盾的)数据进行训练的。这也是 ChatGPT 经常出错的原因之一。Graph 数据的超能力之一是它是可验证的,这意味着它是准确的。因此,我们拥有大量准确的数据,可用于训练更值得信赖的人工智能系统。
用 AI 赋能Graph网络
虽然该协议在数据索引方面比 AI 得到更广泛的认可,但 Graph确实具有在其堆栈中有效利用 AI 所需的许多属性。对于索引器,Semiotic Labs 创建了开源 AI 工具来自动执行复杂的决策,这既可以提高协议的效率,又可以提高索引器的收入。对于 Graph 的用户,我们已经启动了一个试点项目,该项目将允许使用自然语言查询访问 Graph 的丰富数据。而且,在未来,Graph 可能成为用于训练新人工智能模型的可信、可验证数据的来源。
参考链接:https://thegraph.com/blog/using-ai-to-enhance-the-graph/
—煤油灯科技victorlamp.com编译整理—
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。