
语音到语音翻译(S2ST)对于打破语言壁垒与沟通障碍非常有益。传统的 S2ST 系统通常由语音识别(ASR),机器翻译(MT)和语音合成(TTS)三部分组成。与这些级联系统相比,直接 S2ST 能够用于翻译没有书面形式的语言;减少了计算需求,降低了推理延迟;还避免子系统之间的误差传递。
近年来 [1,2],利用自监督模型获得的离散单元(discrete unit)构建无文本 S2ST 系统逐渐成为主流,通过语音到单元翻译(S2UT)与基于单元的声码器的系统以支持跨语言 S2ST。我们主要有两大目标:1)高质量:直接语音到语音翻译在无文本下尤其具有挑战;2)低延迟:考虑真实实时同传时,高推理速度至关重要。
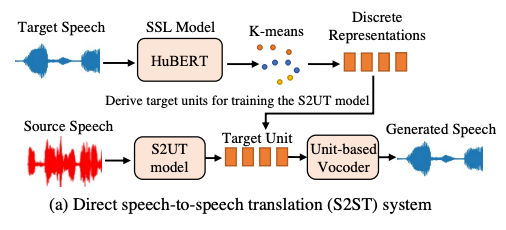

尽管离散单元的无文本 S2ST 系统带来了突破,但目前的 S2ST 研究仍存在两大挑战:
● 由于语音包含语言内容和声学信息(语者、旋律、音调和能量),因此相同含义的语音得到的自监督单元可能不同,不确定性的训练目标(target)降低了翻译的准确率。
● 在 S2ST 系统上构建并行模型时,由于序列单元间不存在条件依赖,因而并行系统的输出与实际目标分布可能存在差异。

论文标题:
TranSpeech: Speech-to-Speech Translation With Bilateral Perturbation
论文链接:
https://arxiv.org/abs/2205.12523
代码链接:
https://github.com/Rongjiehuang/TranSpeech
作者:黄融杰,来源于PaperWeekly
在今年的人工智能顶级会议 ICLR 2023 上,浙江大学和字节跳动提出了全新的基于双边扰动的非自回归语音到语音翻译模型 TranSpeech。针对自监督表征受声学特征影响而不确定性强的问题,提出了基于双边扰动(BiP)的模型微调,减轻了声学多峰性(Acoustic Multimodality)以提升翻译性能。
进一步地,我们使用 Mask-Predict 算法建立非自回归 S2ST 模型,显著加快解码过程。同时为了应对非自回归翻译中的语言学多峰性(Linguistic Multimodality)挑战,我们基于知识蒸馏构建了噪声更少、确定性更强的语料库。在三种语言对的实验结果表明,BiP 平均提高了 2.9 个 BLEU 点。就推断速度而言,并行解码与自回归基线相比实现了 21.4 倍的加速。
01 研究背景
我们在此介绍两种影响模型性能的多峰性挑战:1)声学多峰性:具有相同内容“Vielen dank”的语音可能因各种声学条件而不同;2)语言学多峰性 [3]:同一源词/短语/句子(“谢谢”)有多个正确的目标翻译(“Danke schon”和“Vielen dank”)。
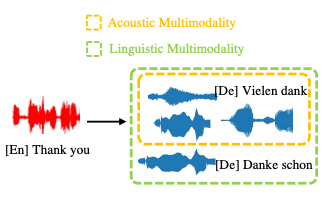
而语音可以分解为内容信息和声学信息(语者、旋律、音调和能量)两大部分:语言内容表示语音信号的含义,要将语音样本翻译成另一种语言,从语音信号中学习语言信息至关重要;在声学条件中,说话人身份被认为是说话人的声音特征,节奏表征了说话者发出每个音节的速度,音高是语调的一个重要组成部分,能量则影响说话的音量。
02 双边扰动微调
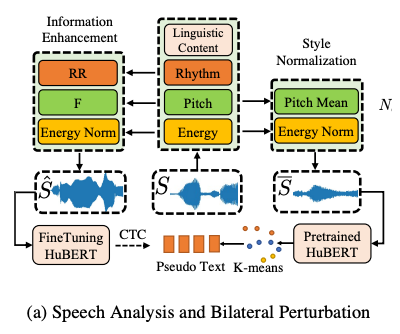
针对自监督表征受声学特征影响而确定性差的问题,我们提出了基于双边扰动(BiP)的模型微调,减轻了表征的声学多峰性(Acoustic Multimodality)以提升翻译性能。
我们主要关注单语者场景中具挑战性的声学特征,包括节奏、音调和能量变化。具体而言,我们利用预训练的自监督学习教师模型,使用扰动的输入语音和归一化的伪文本标签,利用Connectionist Temporal Classification(CTC)[4] 微调模型得到确定性更强的、声学不敏感的自监督表征,以提升翻译模型准确度,主要包括:
● 风格规范化阶段:获得具有数据集平均声学特征的音频,创建声学不可知的自监督表征,消除 CTC 目标(Target)的声学信息。
● 信息增强阶段:扰动输入音频的声学特征,在不同声学条件(如节奏、音调和能量)下创建语音样本变体,同时保留语言内容信息。
因此,我们使用扰动语音作为输入,以风格不可知“伪文本”作为目标训练语音到自监督表征的(Many-to-One)识别模型。鼓励学习语言学信息的、而声学“平均”的确定性表征,解决声学多峰性挑战并提高语音翻译的准确度。
为证明声学多峰性并验证双边扰动,我们可视化频谱并分别扰动声学特征(即节奏、音调和能量),创建扰动语音样本。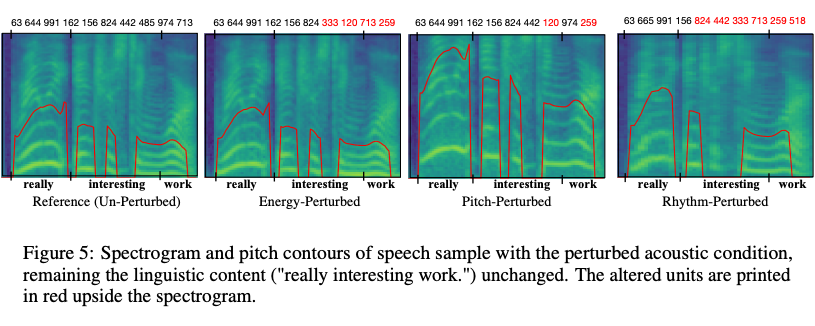
可以看到,在预训练自监督模型中,声学特征改变而语言学内容不变带来的自监督表征不确定性高达 22.7% UER。自监督模型同时学习语言内容信息和声学信息,因此相同内容而声学信息(语者、旋律、音调和能量)不同的语音中得到的自监督表征是不确定的。与之不同的是,使用所提出的双边扰动(BiP)后微调模型,得到的 UER 出现了显著下降,证明了 BiP 有效地缓解声学多峰性挑战。
03 非自回归语音翻译
我们 1)使用 BiP 微调的自监督模型 HuBERT [5] 获得目标语音的离散自监督单元;2)建立用于语音到单元翻译(S2UT)的序列到序列模型 TranSpeech,3)应用单独训练的基于单元的声码器 [6,7] 获得目标语言语音。
从模型结构上,我们使用了 Conformer 编码器以及 Transformer 解码器。同时使用 Transformer XL [7] 的具有相对正弦位置编码的多头注意力机制,提高自注意力模块的鲁棒性,并更好地推广到不同的输入语音长度。
为了缓解非自回归翻译的语言学多峰性,我们应用知识蒸馏技术从自回归教师模型中构建了新的翻译语料库,比原始语料库具有更少的噪声因素,且更具确定性。
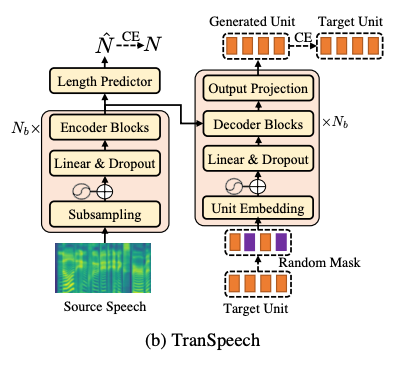
在非自回归解码策略中,我们应用 Mask-Predict [8] 策略,具体来说:1)训练中,给定目标序列的长度 N,我们首先从 1-N 的均匀分布中采样遮蔽(Mask)单元的数量,然后随机选择遮蔽位置。对于训练损失,我们计算遮蔽位置中生成的单元和目标单元之间的交叉熵(CE)损失,同时加入了目标长度预测的 CE 损失。2)推理中,该算法运行预定的T次迭代优化,总体上我们在每次迭代时遮蔽 (Mask)单元,然后进行预测(Predict)。
在第一次迭代 t=0 中,我们预测目标序列的长度 N,并遮蔽所有单元 Y。在每轮迭代中,我们确定较高分数的单元,继续遮蔽(Mask)具有最低置信度的 n 个单元: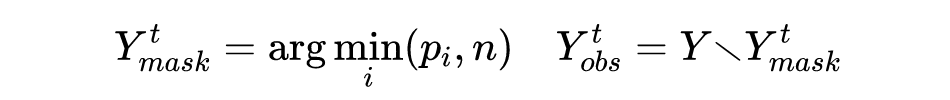 其中 n 是关于迭代轮次 t 的函数,我们在本工作中使用线性衰减(Linear decay)。掩蔽后,TranSpeech 基于源语言语音 X 和未掩蔽单元 Yobs 预测掩蔽单元 Y,并更新各单元置信度。与此同时,我们探索使用了高级解码方式,包括:
其中 n 是关于迭代轮次 t 的函数,我们在本工作中使用线性衰减(Linear decay)。掩蔽后,TranSpeech 基于源语言语音 X 和未掩蔽单元 Yobs 预测掩蔽单元 Y,并更新各单元置信度。与此同时,我们探索使用了高级解码方式,包括:
长度 beam 搜索:我们选择具有最高概率的前 K 个候选长度,同时并行解码具有不同长度的目标序列。
噪声并行解码:我们使用自回归教师模型获得序列置信度,以确定最佳整体翻译。
04 实验结果
我们使用CVSS-C翻译数据集的三种语言对上进行了实验,包括法语-英语(Fr-En)、英语-西班牙语(En-Es)和英语-法语(En-Fr)。
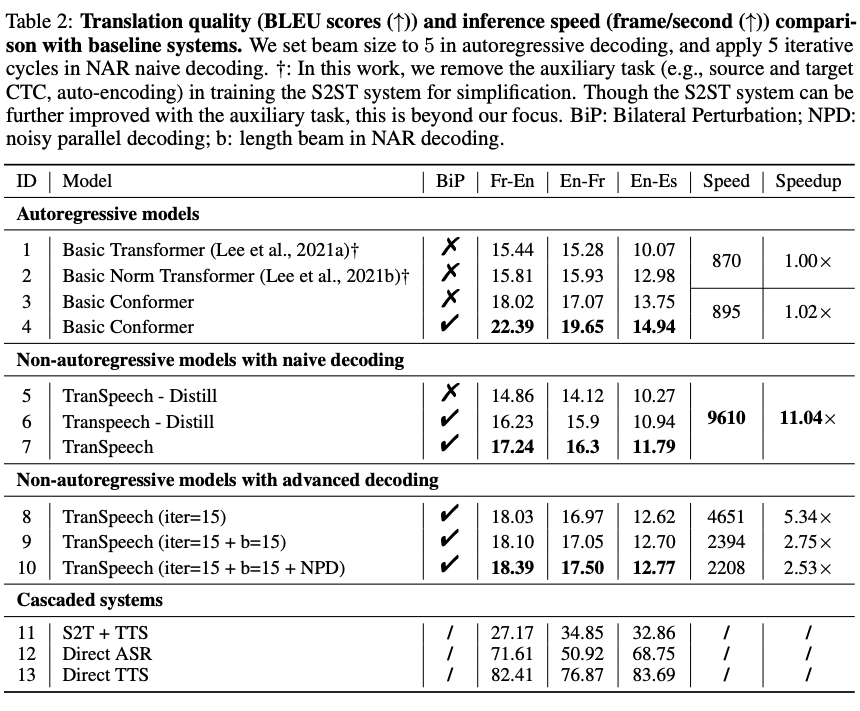 主要得出以下结论:
主要得出以下结论:
● 双边扰动(3 vs. 4)在 S2ST 性能提高了 2.9 个 BLEU 点。
● Conformer 模型架构(2 vs. 3)显示了 2.2 个 BLEU 点的精度增益。
● 知识蒸馏(6 vs. 7)被证明可以缓解语言学多峰性,在蒸馏语料库上的训练提供了大约 1 个 BLEU 点的提升。
● TranSpeech 超过了最佳公开基线(2 vs. 6),且在 S2ST 上实现新的 SOTA 只需要 2 个掩码预测(Mask-Predict)迭代轮次。
● 当考虑非自回归预测的速度-性能平衡时,更多的迭代轮次(7 vs. 8)或高级解码方法(例如,长度 beam 搜索(8 vs. 9)和噪声并行解码(9 vs. 10))进一步提升翻译精度。
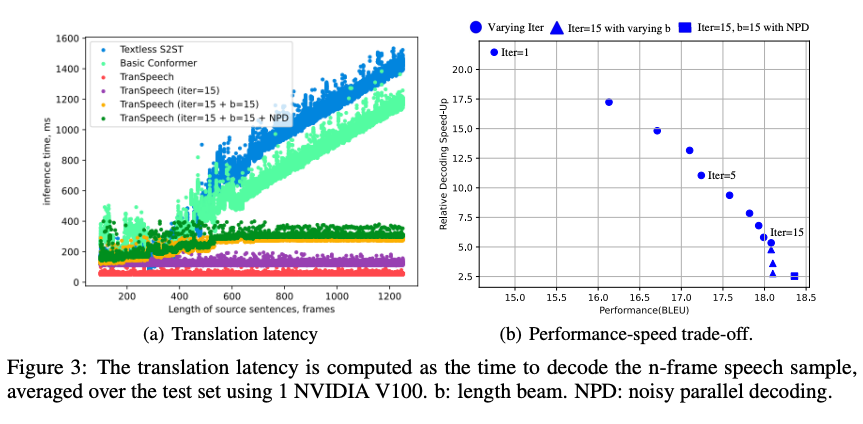 在解码速度上,自回归基线解码时间随着长度上具有线性增长。而非自回归模型 TranSpeech 不同长度序列的解码时间几乎是恒定的,尽管有多个周期的 Mask-Predict 迭代轮次。与自回归基线相比,TranSpeech 的速度提高了 21.4 倍。另一方面,它也可以保持 BELU 18.39 的最高质量,同时获得 253% 的加速。
在解码速度上,自回归基线解码时间随着长度上具有线性增长。而非自回归模型 TranSpeech 不同长度序列的解码时间几乎是恒定的,尽管有多个周期的 Mask-Predict 迭代轮次。与自回归基线相比,TranSpeech 的速度提高了 21.4 倍。另一方面,它也可以保持 BELU 18.39 的最高质量,同时获得 253% 的加速。
05 总结与展望
针对翻译质量,我们提出了基于双边扰动(BiP)的自监督模型微调,减轻了表征的声学多峰性(Acoustic Multimodality)以提升翻译性能。针对翻译速度,我们使用 Mask-Predict 算法建立非自回归解码,并应用知识蒸馏技术应对语言学多峰性(Linguistic Multimodality)挑战。在三种语言对的实验结果表明,与基线 S2ST 模型相比,BiP 平均提高了 2.9 个 BLEU 点。就推理速度而言,并行解码与自回归基线相比实现了 21.4 倍的加速。
TranSpeech 是我们研究通用语音翻译(Universal Translation)的关键一步,未来我们将持续提高 S2ST 的翻译质量,并积极拓展到多模态 S2ST 翻译领域。
参考文献
[1] A. Lee, P.-J. Chen, C. Wang, J. Gu, X. Ma, A. Polyak, Y. Adi, Q. He, Y. Tang, J. Pino et al., “Direct speech-to-speech translation with discrete units,” arXiv preprint arXiv:2107.05604, 2021.
[2] A. Lee, H. Gong, P.-A. Duquenne, H. Schwenk, P.-J. Chen, C. Wang, S. Popuri, J. Pino, J. Gu, and W.-N. Hsu, “Textless speech-to-speech translation on real data,” arXiv preprint arXiv:2112.08352, 2021.
[3] Jiatao Gu, James Bradbury, Caiming Xiong, Victor OK Li, and Richard Socher. Non-autoregressive neural machine translation. arXiv preprint arXiv:1711.02281, 2017.
[3] Alexei Baevski, Michael Auli, and Abdelrahman Mohamed. Effectiveness of self-supervised pretraining for speech recognition. arXiv preprint arXiv:1911.03912, 2019.
[4] Wei-Ning Hsu, Benjamin Bolte, Yao-Hung Hubert Tsai, Kushal Lakhotia, Ruslan Salakhutdinov, and Abdelrahman Mohamed. Hubert: Self-supervised speech representation learning by masked prediction of hidden units. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 29:3451–3460, 2021.
[5] Adam Polyak, Yossi Adi, Jade Copet, Eugene Kharitonov, Kushal Lakhotia, Wei-Ning Hsu, Abdelrahman Mohamed, and Emmanuel Dupoux. Speech resynthesis from discrete disentangled self-supervised representations. arXiv preprint arXiv:2104.00355, 2021.
[6] Jungil Kong, Jaehyeon Kim, and Jaekyoung Bae. Hifi-gan: Generative adversarial networks for efficient and high fidelity speech synthesis. Advances in Neural Information Processing Systems, 33:17022–17033, 2020.
[7] Zihang Dai, Zhilin Yang, Yiming Yang, Jaime Carbonell, Quoc V Le, and Ruslan Salakhutdinov. Transformer-xl: Attentive language models beyond a fixed-length context. arXiv preprint arXiv:1901.02860, 2019.
[8] Marjan Ghazvininejad, Omer Levy, Yinhan Liu, and Luke Zettlemoyer. Mask-predict: Parallel decoding of conditional masked language models. arXiv preprint arXiv:1904.09324, 2019.
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。