
本文提出了一种基于时空分辨率自适应的视频压缩框架(ViSTRA),该框架基于定量分辨率决策,在编码过程中对输入视频进行时空动态重采样,并在解码器处重建全分辨率视频。时间上采样采用帧重复,空间分辨率上采样采用卷积神经网络超分辨率模型。ViSTRA 已集成到高效视频编码参考软件(HM 16.14)中。
来源:TCSVT 2018
论文题目:Video Compression Based on Spatio-Temporal Resolution Adaptation
论文链接:https://dl.acm.org/doi/10.1109/TCSVT.2018.2878952
作者:Mariana Afonso,Fan Zhang and David R. Bull
内容整理:王妍
ViSTRA 框架通过国际挑战验证的实验结果显示了显著的改进,基于 PSNR 的 BD-rate 提高了 14.5%,基于主观视觉质量测试的平均 MOS 差为 0.52。
本文的主要贡献包括:
- 将空间和时间适应整合到一个单一框架中;
- 提出一个量化-分辨率优化(QRO)模块,该模块应用感知质量指标和机器学习技术来生成可靠的分辨率适应决策;
- 使用基于 CNN 的超分辨率模型重建全空间分辨率内容,专门针对压缩内容进行训练;
- ViSTRA 框架与 HEVC 参考软件(HM 16.14)的集成。
ViSTRA 框架
整体框架
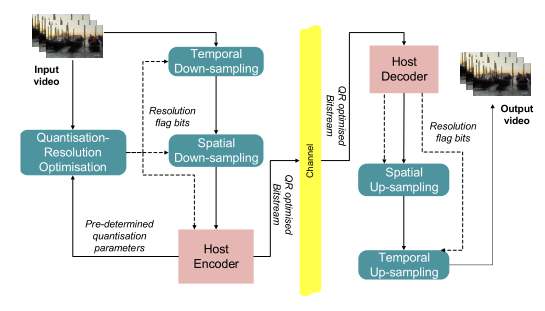

ViSTRA 整体框架集成了时空适应与视频编码,以最大限度地提高码率-质量性能。全分辨率视频的视频帧首先由 QRO 模块处理,该模块根据视频内容和输入量化参数(QP),负责预测其对空间和时间适应的适应。该模块做出两个决定:一个是空间适应,一个是时间适应。这些决策分别控制用于空间和时间下采样的模块,在比特流中使用标志位来表示适应。主机编码器的输入是分辨率优化后的视频。在解码器处,从比特流中提取标志位得到编码器的重采样决策,并解码分辨率重采样后的视频帧。最后,对解码帧进行空间和时间上采样得到原始分辨率帧。
时间适应决策是在两帧之间做出的,并且要求每帧添加一个标志位到比特流中。相比之下,空间适应决策是为每个图片组(GOP)做出的,每个 GOP 需要一个标志位。如果随后发现两个 GOP 包含不同的空间决策,例如,第二个 GOP 的分辨率是第一个 GOP 分辨率的一半,则在该点引入分裂,并对两个单独的比特流进行编码。由于 HEVC 本身不支持不同空间分辨率的编码,因此需要这个过程。
QRO 模块
在压缩之前,全分辨率视频帧被送到 QRO 模块,其中时间和空间分辨率随后根据初始量化参数和视频内容进行优化。
时间决策
时间分辨率优化采用帧率相关的质量度量 FRQM,来评估时间下采样视频帧与其全帧率原始视频帧之间的感知质量差异。时间下采样是使用帧平均实现的。如果得到的 FRQM 分数高于预先确定的阈值 TH,则对时间下采样的视频帧进行编码,以取代原始版本。在这一步中,只使用了比例 2 进行下抽样,每个决策都是在 2 帧的时间窗口内做出的。时间分辨率标志 TRflag 表示是否进行了时间分辨率适配,计算方法如下:
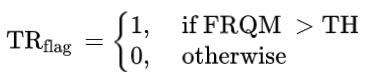
其中 TH = 48,对应的 DMOS 为 10(从 0 到 100)。这确保了在时间上重新采样的视频和原始视频之间没有显著的感知差异。
空间决策
空间分辨率决策模块使用来自未压缩视频帧的低水平时空特征,采用了基于学习的方法。这些特征仅在 Y (luma)通道上计算,并用于预测量化参数(QP)阈值 QPthres。在 QPthres 下,以较低分辨率编码输入视频将比原始分辨率产生更高的码率-质量性能。在这一步中,使用单一比例 2 进行重采样。
在本文中,除了 PSNR 外,还计算了连续帧的两个时空特征,归一化交叉相关(Normalized Cross-Correlation, NCC)和时间相关(Temporal Coherence, TC),共使用 4 个特征进行预测,形成特征向量 K,如下所示:

这些特征是为训练数据集计算的,该数据集由来自 Harmonic Inc 视频数据库的 7 个临时裁剪的超高清视频组成。在计算所有序列的特征向量和真实 QP 阈值(基于 HM 16.14 的多重编码)后,拟合的线性回归参数为 W =[−0.62,1.94,−0.58,−3.87],β = 63.7。训练数据拟合的均方根误差(RMSE)为 3.26 (QP 值)。

时空重采样
时间下采样使用帧平均来实现,上采样采用最近邻插值。
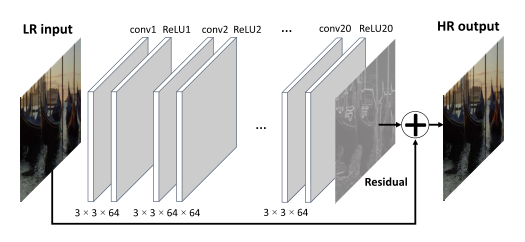
空间重采样采用了 VDSR 的 CNN 架构,并对其进行 HEVC 压缩视频的再训练。该架构包含 20 个卷积层,64 个 3 × 3 滤波器和 ReLU 激活函数,并应用了残差学习。
训练 CNN 的数据集与 QRO 模块的训练集相同。训练机制如下:
- 使用下采样比为 2 的 Lanczos3 滤波器对每个序列进行下采样。
- 使用 HEVC (HM 16.14)对低分辨率版本进行编码和解码,随机访问主配置使用 4 个不同的 QP 值 (22、27、32 和 37)。
- 使用相同的过滤器对重建的视频进行上采样。
- 从上个过程中得到的帧被用作 CNN 的训练输入,输出目标是原始的未压缩帧。
作者选择得到的视频帧的子集,将其分成 41 × 41 像素的块( CNN 的接受野大小),并随机选择 400 个块。此外,为了给 CNN 提供更强的泛化能力,以块旋转的形式对数据进行增强。因此,总共大约有400 万个块被用于训练 CNN。最后使用 CAFFE 进行训练,批大小为 64,学习率为 10-4 (固定),权重衰减为 10-4 , 轮次为 10。
实验结果

测试数据集由 9 个序列组成,4 个 HD (1920 × 1080)和 5 个裁剪 UHD (2560 × 1600),来自JVET (联合视频探索小组) UHD 测试集和 BVI 纹理数据库。此外,每个序列都有 4 个目标比特率点,以提供低质量的锚点。为了满足测试序列的目标比特率,QP 值迭代调整,直到输出比特率足够接近目标比特率。上图是每个序列的样本帧和目标比特率点。
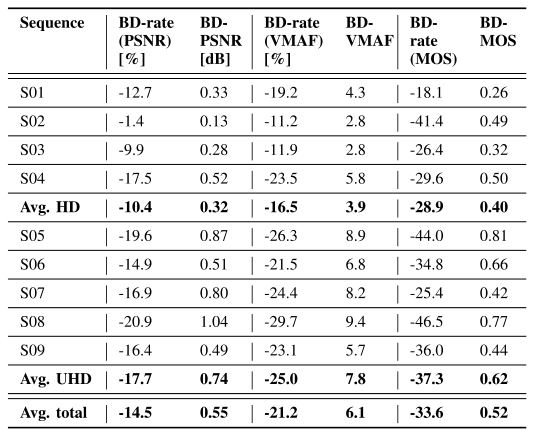
上表是 ViSTRA 框架相对于 HEVC HM 16.14 的测试结果,测试结果基于 PSNR、视频多方法评估融合(VMAF)和主观测试。可以看到, ViSTRA 框架取得了显著的改进,平均提高了 14.5% 的 BD-rate (使用 PSNR )和 0.55 的 BD-PSNR。当使用与主观质量相关性更好的 VMAF 时,结果更为明显,平均提高的 BD-rate 为 21.2%,BD-VMAF 为 6.1。并且 ViSTRA 在提高空间分辨率方面取得了更显著的进步,2560 × 1600 测试序列提高的 BD-rate (PSNR) 为 17.7%,而 1920 × 1080 测试序列的只提高了 10.4%。这是由于更高分辨率的空间冗余增加,下采样过程丢失的信息更少。主观测试证实了所提出的框架所获得的感知质量增益,平均 BD-MOS 为 0.52。
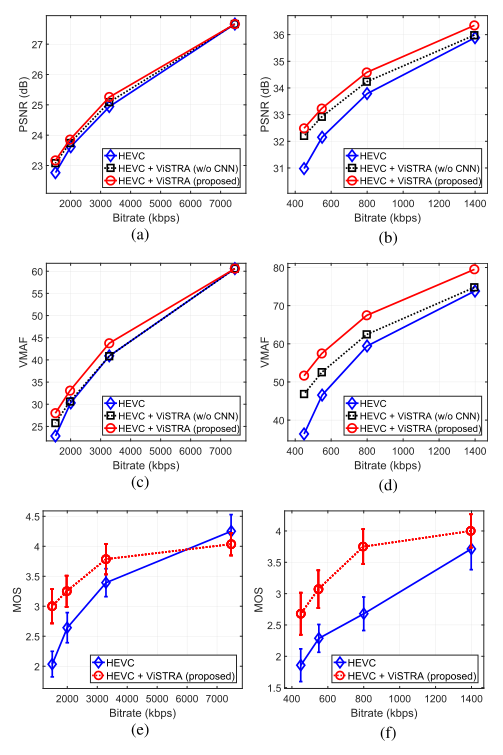
上图是 LampLeaves (S03)和 CatRobot (S05)两个测试序列的比特率-质量曲线。该图还比较了两个示例序列在解码器中不使用 CNN 的 ViSTRA 下的性能。平均而言,CNN 的使用使重构帧的质量提高了 0.19 dB 和 3.5 VMAF 值,这体现在基于 PSNR 的BD-rate提高了 6.0%,基于 VMAF 的 BD-rate 提高了 14.1%。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。