
在日常生活中,声音是人们进行信息传递的重要媒介,为了保证信息的顺利传递,突破距离的限制,往往需要对声音信号进行放大,扩音系统应运而生。
扩音系统是指把声音信号进行实时放大的系统,主要由麦克风、放大器以及扬声器组成,在演奏厅,大教室,会议室等大空间场所得到了广泛应用。但是,扩音系统自使用以来,常常伴随着啸叫问题,极大地影响了用户的使用体验感。啸叫现象是指音频信号通过扬声器播放后,经过一定的传播路径,再次被麦克风拾取,经过放大器的处理后,最后经由扬声器播放,倘若在 “扬声器-麦克风-扬声器”的闭环电路中,存在某种正反馈导致某些音频频率发生自激振荡,就会产生啸叫现象。
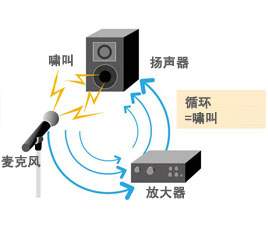

啸叫的产生会掩盖正常语音,给人的听感也不好,而且啸叫频点能量很高,严重时甚至能破坏会议中的扩声设备,因此我们需要对啸叫进行抑制。
我们以单通道扩声系统为例说明啸叫产生原理,系统模型如下所示:
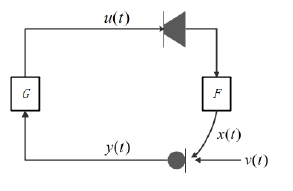
该扩声系统由麦克风、功率放大器和扬声器组成,其中G是功率放大器,F是声传播路径,v(t)和x(t)分别为声源信号和反馈信号,y(t)是麦克风的输入信号,u(t)是经过功率放大器处理后的声信号。
根据奈奎斯特稳定准则,当闭环系统的某个角频率w的回路响应的幅度和相位同时满足以下两个条件时,就会引起系统的不稳定,从而引起啸叫。
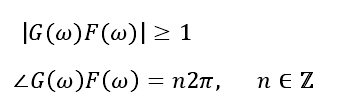
其中G(w)为放大器的频率响应,F(w)为声传播路径的频率响应。总的来说,产生啸叫必须同时满足振幅条件:反馈增益大于1。相位条件:声源信号的相位和反馈信号的相位是相同的。因此啸叫抑制技术实际上就是破坏啸叫产生的幅度要求或者相位要求。
研究人员针对啸叫抑制主要提出了两大类方法,被动抑制的方法和主动控制的方法。
被动抑制啸叫的原理是减少直达和反射声,我们可以根据声场特性,从声场布局、声场调整、扩音系统设计、扩音设备选型等方向抑制啸叫。主要包括:
(1)从室内建筑声学、如室内的装修,装修材料的选择等方向来抑制啸叫,具体的方法诸如:摆放更多的桌椅,安装天花石膏吊顶,选择吸声材料作为装修材料等等。
(2)合理地摆放麦克风和扬声器:将麦克风和扬声器置于不同的声场显然是最好的方法,可以破坏正反馈,避免啸叫,但这种方法难以实现。因此我们可通过选择合适的麦克风和扬声器的摆放位置来抑制啸叫,如让麦克风尽量不要正对扬声器。
(3)选择合适的扩声设备,如尽量选用低敏感度、高指向性的麦克风。
但是,这种方法只是被动地抑制啸叫,造价和施工难度太大,不具有普遍推广意义。
相较于被动抑制啸叫的方法,主动控制啸叫的方法利用数字设备进行实现,造价低,可复制,能够普遍推广。传统且主流的主动控制方法有三种,分别为相位调制法、增益控制法和自适应反馈抵消法。
相位调制法
相位调制法,简单来说就是移频法和移相法,移频法和移相法进行啸叫抑制的原理是把输入信号的频率分量往前或者往后移动,使得输入信号与声反馈信号频率之间的叠加现象消失,或者使声反馈相位和输入信号的相位产生偏差,破坏了啸叫形成的相位条件,从而达到抑制啸叫的目的。该方法算法简单,且对扩声系统增益有明显提升,可以快速实现啸叫抑制,但是对输入信号进行移频或者移相的操作,对信号的音质损失很大,会导致声信号的音质效果变差。
增益控制法
增益控制法通过降低正反馈环路中的增益,破坏了啸叫形成的幅值条件,达到啸叫抑制的效果。根据需要增益值降低的频带宽度的范围,增益控制法分为三类,自动增益控制法(AGC),自动均衡法(AEQ)和基于陷波滤波器的啸叫抑制法(NHS)。当需要将系统增益降低时,AGC会在信号的整个频带范围内降低增益,有些没产生啸叫的频点幅值也会被降低。AEQ会把声音信号分为几个频段,将啸叫频点对应的频段进行增益衰减,整体受影响不大。而NHS是在特定的频率点进行增益控制,采用陷波滤波器的啸叫抑制法只对自激振荡的频率点附近进行增益控制,在啸叫频率点检测准确的情况下,对附近频率的幅值影响比其它两种方法小,并且计算复杂度低。
自适应反馈抵消法
自适应反馈抵消法(AFC)根据输入信号,对声传播路径进行建模识别,从而估计得到声反馈信号,最后在麦克风的输入信号中减去估计出的声反馈信号,从而实现啸叫抑制。目前AFC的关键在于自适应算法的选择,应用较为普遍的是最小均方误差算法(LMS)。理论上如果可以精确地估计出声传播路径,AFC可以完全地消除啸叫。但是扬声器信号和麦克风信号一般具有一定的相关性,会造成一些估计误差,利用噪声信号法、非线性处理法等去相关技术可降低两种信号的相关性,但是去相关技术会导致一定的声信号失真,因此需要根据实际使用场景在去相关和音质之间做一个权衡。
近年来随着深度学习的发展,研究人员提出了基于深度学习的啸叫抑制解决方案,这类算法包含三个部分,特征提取,学习模型和训练目标。通过把啸叫信号和纯净语音信号混合得到的声信号作为训练样本,最终训练出能够抑制啸叫的网络模型。利用深度学习进行啸叫抑制的处理步骤通常是首先获得掺杂啸叫信号的混合声信号作为输入数据,再对混合声信号提取语音特征,根据期望声信号的不同提取不同的特征,常用的特征有时频特征、频谱、梅尔倒谱(MFCC)、Gamma倒谱(GFCC)等特征,之后建立网络模型,网络模型通常是RNN系列的模型及其变种,例如LSTM、GRU等。最后对网络模型进行训练得到一个可以将混合声信号映射为纯净语音信号的网络模型。目前,利用深度学习进行啸叫抑制的技术正在快速发展,希望在抑制啸叫方面能够达到更好的效果。
总的来说,传统方法和基于深度学习的啸叫抑制方法各有优缺点,我们需要根据实际应用场景来选择最合适的方法。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。