
图像分割将不同语义的像素归入不同的分组中,例如分类和实例分割。每种语义的选择被定义成不同的任务,目前的研究为每种不同任务设计了不同的架构。本文提出了全新框架Masked-attention Mask Transformer (Mask2Former),能解决任何图像分割问题(包括全景分割、实例分割和语义分割)。它的关键组成部分包括 masked-attention,它通过在预测的 mask 区域内限制交叉注意力来提取局部特征。除了将研究工作减少至少三倍之外,它在四个流行数据集上的表现也明显优于最好的专用架构。
来源:CVPR 2022
作者:Bowen Cheng, Ishan Misra 等
内容整理:王寒
引言
图像分割研究的问题是像素分组。不同的像素分类语义,例如分类和实例成员,将研究分为了不同的类别:全景分割、实例分割和语义分割。
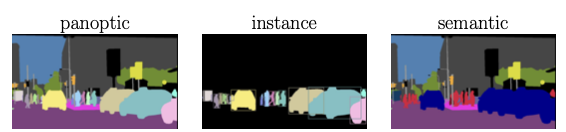

上图展示了三种不同的分割任务。本文提出的Mask2Former算法对上述三类任务都有效。
网络结构
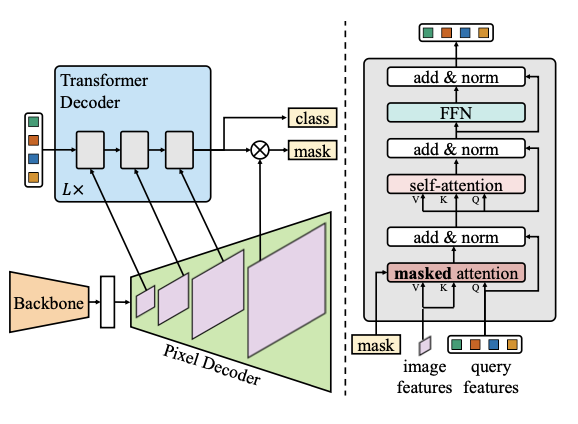
上图展示了Mask2Former算法的整体网络结构,为了便于阅读,图中省略了来自中间 Transformer 解码器层的位置嵌入和预测。
Mask2Former使用了与MaskFormer相同的backbone,一个像素解码器和一个transformer解码器。Mask2Former利用注意力transformer代替交叉注意力设计了新的transformer解码器,图中右侧部分。为了处理小物体,本文提出了一种高效解决方案来利用像素解码的高阶特征,每次将多尺度特征的一阶输入到transformer解码层。此外,本文将自注意力和交叉注意力的顺序交换,使query特征可学习,并且删除了dropout来让计算更加高效。
mask分类结构将像素根据类别分为N类,该分类具有足够的通用性,可以通过将不同的语义(例如类别或实例)分配给不同的部分来解决任何分割任务。挑战在于为每个部分找到合适的代表。例如,Mask R-CNN 使用边界框作为表示,将其应用限制在语义分割上。受 DETR 的启发,图像中的每个部分都可以表示为C维特征向量(“对象查询”),并且可以由使用一组预测目标训练的 Transformer 解码器进行处理。
元结构由三个组件组成:一个从图像中提取低分辨率特征的主干;一个像素解码器,它逐渐从主干输出中对低分辨率特征进行上采样,以生成高分辨率的每像素嵌入;一个 Transformer 解码器,它对图像特征进行操作以处理对象查询。最终的二进制mask预测是从带有对象查询的每像素嵌入中解码出来的。我们的 Transformer 解码器的关键组件包括一个mask注意力操作,它通过将交叉注意力限制在每个查询的预测mask的前景区域内来提取局部特征,而不是关注完整的特征图。
上下文特征在之前的研究中被证明对于分割是很重要。近期的研究表明,交叉注意力层的全局上下文会导致基于transformer的模型收敛速度慢。本文猜想局部特征足以更新query特征,且上下文信息可以被自注意力收集。基于这一猜想本文提出masked attention,是一种交叉注意的变体,它只关注每个query的预测mask的前景区域。
为了在利用高分辨率特征的同时减少计算量,采用了特征金字塔,将多尺度特征的一种分辨率一次提供给一个 Transformer 解码器层。
实验
数据集
COCO , ADE20K , Cityscapes, Mapillary Vistas. 全景分割和语义分割使用“things”和“stuff”进行评估,实例分割仅使用“things”评估。
像素解码器
Mask2Former兼容现有的所有像素解码模块。由于其目标是在不同的分割任务中展示强大的性能,使用更先进的多尺度可变形注意力转换器 (MSDeformAttn)作为默认像素解码器。
Transformer解码器
L = 3(即总共 9 层),默认情况下有 100 个query。辅助损失被添加到每个中间 Transformer 解码器层和 Transformer 解码器之前的可学习查询特征。
损失函数
使用二元交叉熵损失作为mask损失:

最终的损失函数是mask损失和分类损失的结合:
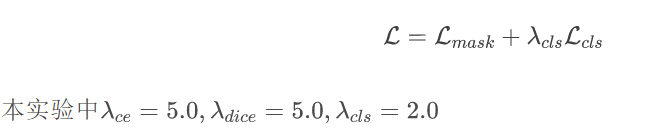
结论
评价指标

实验结果
全景分割实验(COCO 100类)结果如图:
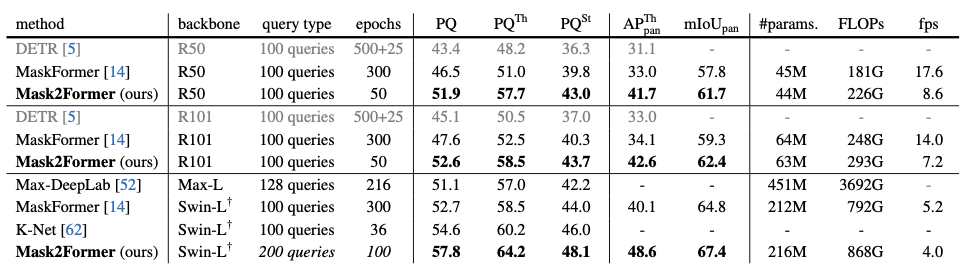
在所有指标上,Mask2Former都明显优于相同主干的算法。
实例分割实验(COCO 80类)结果如图:
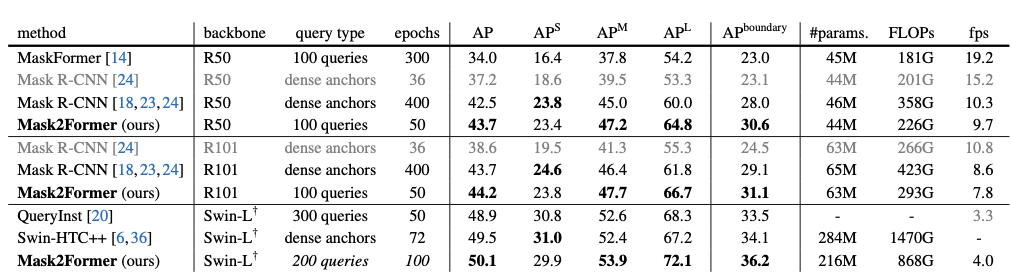
相比于R- CNN架构的其他算法,Mask2Former在AP和APboundary 指标上远远优于此前的算法。本文最好的模型与当前最好的实例分割专用模型效果相差不大。
语义分割实验(ADE20K 150类)结果如图:
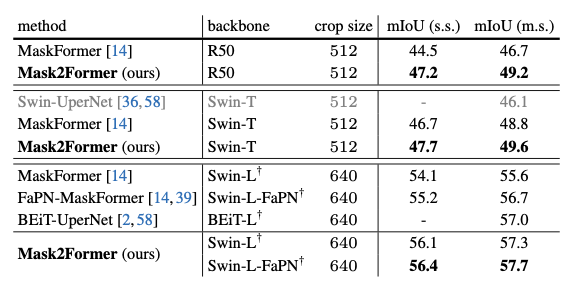
Mask2Former的表现大幅度领先不同架构的其他算法。本文最好的模型超过了当前最好的语义分割专用模型BEiT。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。