
随着短视频、直播、智慧城市、5G等的快速发展,视频内容铺天盖地,五花八门,相应的处理需求也多种多样。如何能高效地应对?需要在数据处理系统,底层计算能力,以及算法研究等多方面协同努力。LiveVideoStackCon 2022 北京站邀请到沐曦AI解决方案总监——虞新阳,为大家梳理视频处理的需求及介绍沐曦应对视频处理场景的GPU产品等。
文/虞新阳
编辑/LiveVideoStack
原文:https://mp.weixin.qq.com/s/0LIR5_EJQlboAO3JEnSCZA
大家好,我是虞新阳,早期主要从事GPU架构研发相关工作,包括视频架构以及computer架构,曾在国际旗舰厂商主导设计硬件解码器的架构设计和研发。对compute更上层的应用感兴趣后加入互联网公司,曾负责阿里巴巴智能家装设计整体解决方案。2021年加入沐曦,一家提供GPU芯片及计算解决方案的算力公司,负责AI算法方向的解决方案。本次分享的主题是《海量视频处理的应对和算法实践》。


为什么要研究视频的处理?
首先,人最基本的属性包括视觉、听觉、嗅觉、味觉、触觉等,其中的视觉和听觉是主要的信息接收和沟通管道。从人的基本属性可以看出,音视频永远不会过时,不管是在当前飞速发展的现实社会还是在今后的元宇宙场景中。
其次,第三方数据对视频的重要性也有总结。2021年,互联网消耗的数据流量主要集中在视频,占比大概是75%。一年后占比还在持续增加,由于短视频、直播等各种更贴近人类视听属性的应用的爆发,客户端的占比达到82%,移动端达到79%。可以想象,视频内容的占比还会持续增加。
为什么我们要特别关注这个问题呢?因为计算需要感知上层应用,或者说一个应用只有充分利用了算力才能够跑得快,而算力只有深刻分析理解应用,并不断进行迭代优化,才能设计出更好的算力。两方相互结合能更好地提升整体系统性能。

本次分享主要包括四部分:
1、视频处理需求理解
2、系统解决方案
3、视频处理算法实践
4、后续工作
-01-视频处理需求理解

图中数据来自Bitmovin2021年的视频发展报告,它本身的调研数据来自于包括65个国家,大中小企业的工程、算法以及市场从业者等,覆盖面非常广。
挑战方面,主要包括直播低延时、成本控制(最主要是带宽流量)、各种设备可播放(笔记本、pad、手机)、精控分析、插广告等。
趋势方面,标黄部分特别重要:第一点,原来H.264是绝对的主流,但在2021年开始出现了首次下降(91%->83%),而专利费较高的H265提升却较明显(42%->49%),我理解是因为带宽的成本太高,比起额外的专利费,大家更需要降低带宽成本。第二点,无论是国外的亚马逊、国内的阿里、腾讯等,它们的云服务都在持续发展,编码采用云服务的比例持续提升。第三点是基于内容的编码,也就是智能视频编码,比例提升到了35%。
其它期待AI赋能的场景包括ASR、视频分析、打标签、视频质量的优化等。
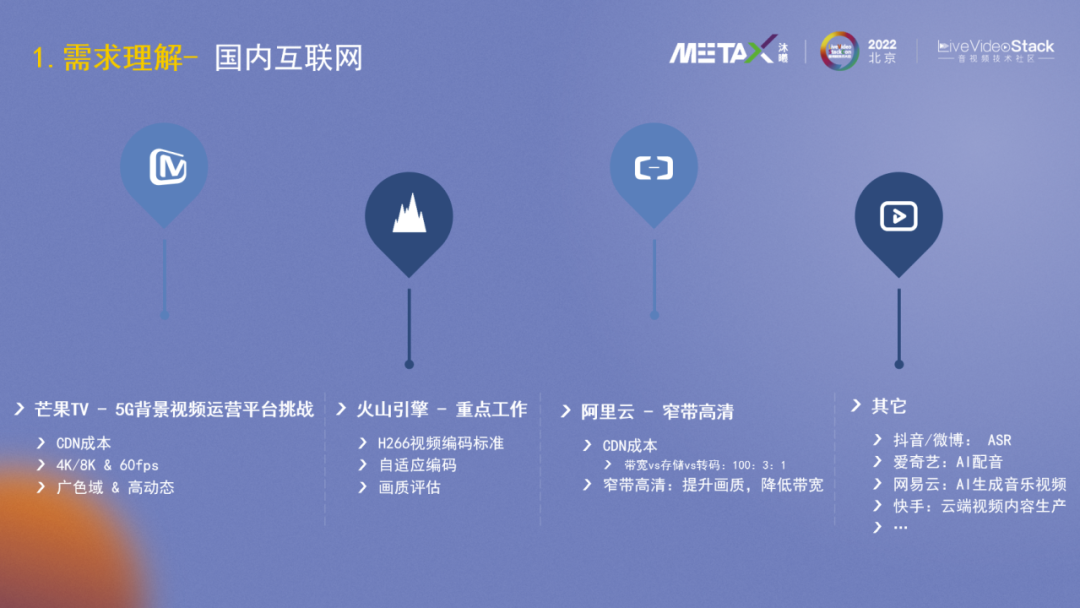
接下来也简要介绍下国内互联网的情况(来源于过往的公开分享):
芒果TV,既是视频内容生产商,同时也是运营商,他们分享了5G背景下视频运营平台的挑战,包括CDN成本,4K/8K&60fps的应对等。
火山引擎,他们重点投入了新一代的编码器H266,并研发自适应编码、画质评价(感知短视频质量并确定推荐权重)等。
阿里云有一个产品叫窄带高清(降低带宽提升画质)。它具象地总结CDN成本占比,从他示例的视频云厂商来说,带宽:存储:转码的成本占比是100:3:1,应该远超出了很多人的感知。
抖音和微博在研发ASR技术来自动生成字幕,爱奇艺、网易云的工作重点是AI配音、AI生成音乐视频等。

最后来看看工业界的需求,主要包括智能安防、智慧交通、智能制造等。
国内的智能安防很发达,处理场景包括边缘端、服务器端等,对采集的海量视频的基本处理包括编解码、结构化分析及比对等。
智能交通包括路边停车识别、车路协同,以及汽车自动驾驶等,视频解码和结构化处理是这些功能最底层的要素。
智能制造主要是工业机器人,包括家电等的生产制造。最重要的场景是检测分类,也有定位、测量等工作。
梳理后可以发现,大方向还是视频编解码+AI,虽然后处理略有不同,有的偏结构化存储,有的偏检索分析,有的偏定位控制等。

从前面的3个维度可以发现,海量音视频处理的基本形态是视频编解码+AI,重点需求是低时延、视频压缩、视频超分、视频分类检测及ASR,其他需求还包括视频处理(切片、转HDR等)、视频分析、视频推荐等。
重点需求中的低时延直播,主要在硬件层进行解决;而压缩、超分等需求算法侧可以发挥很大作用。
-02-系统解决方案
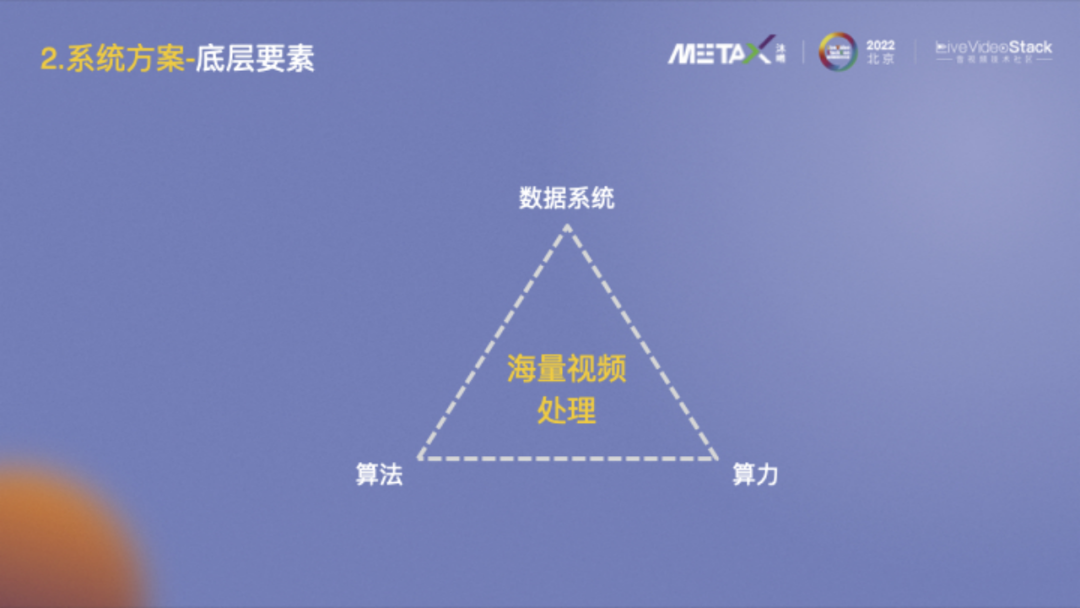
大家对这张图应该不陌生,AI最基本的三要素包括算法、算力和数据。平移到海量视频数据的处理,需要一个高效的数据系统做支撑,其中算力提供底层基础能力,算法协助数据系统更加智能高效。接下来主要介绍下算力和算法方面。
海量视频处理对算力侧的需求包括强编解码能力、强AI推理能力和高性价比。

这里介绍下沐曦的曦思®N100产品。根据上述需求,我们针对性地设计了这款产品,它具备很强的编解码能力,解码支持96x1080p@30fps,标准包括H264/H265/AV1/AVS2,支持8K;编码更强,能支持128×1080@30fps,标准包括H264/H265/AV1,支持8K。此外,它还具备很强的AI推理能力,上文提到很多场景同时需要编解码能力和AI能力,它的AI算力达到160TOPS int8, 80TFLOPS FP16/BF16,此外它也有很好的带宽能力,相关的软件栈、开发工具、虚拟化等配套能力也很齐备。
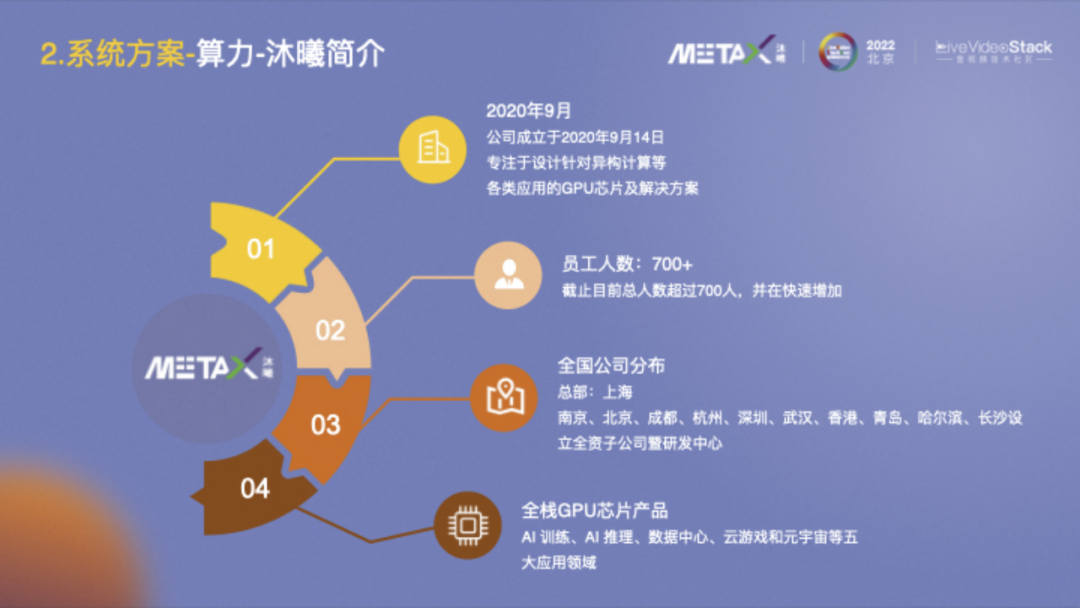
也简要介绍一下沐曦,它成立于2020年9月,专注于设计针对异构计算等各类应用的GPU芯片及解决方案。公司发展速度很快,有80%以上的员工是硕士及以上学历,70%以上的员工平均工龄超过10年。沐曦基本每年会推出一款产品进行持续迭代。
-03-视频处理算法实践
针对算法实践,接下来重点介绍下我们在视频压缩、视频超分和ASR上的一些工作。
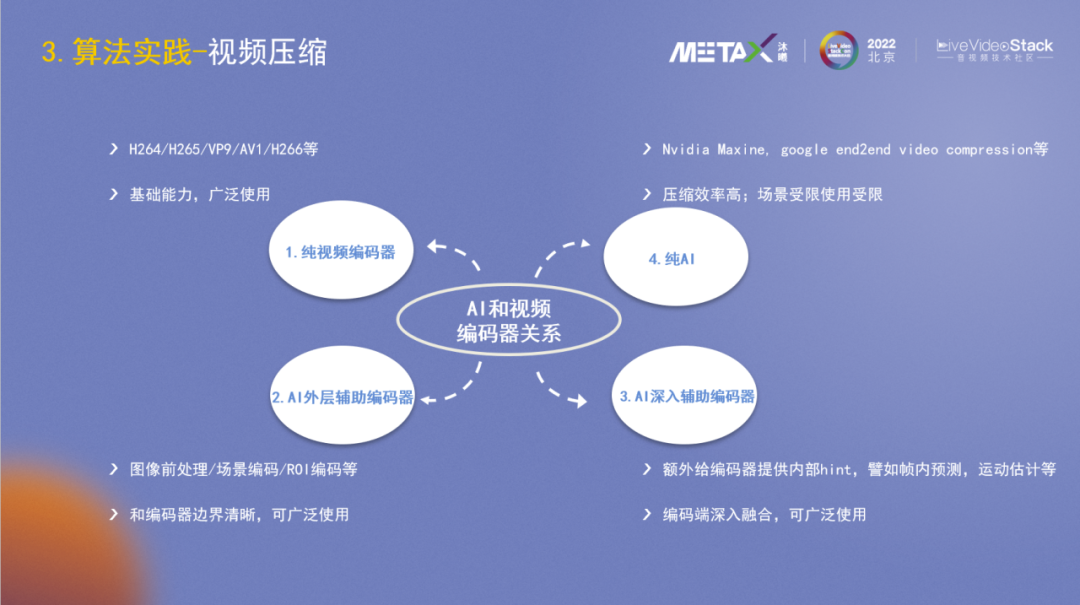
根据AI和编解码的关系,视频压缩解决方案主要可分为四种:
1、纯视频编解码:也是当前最普遍最基础的形式,采用标准的视频标准如H264等。
2、AI外层辅助编码:AI和标准编码器有清晰的边界,依托FFmpeg框架等,主要在帧级别进行数据的交互控制,编出来的码流符合标准。
3、AI深入辅助编码:AI算法参与编码的深层次控制,为编码器提供各种hint,譬如帧内预测、运动估计等,需要在编码器内部做相关的能力和接口实现。
4、纯AI编码:是未来的发展趋势,抛弃了H.264/H.265等基于预测变换之类工具的编码思路,而是用AI网络进行编解码,英伟达和Google等都有发布相关的工作。当前比较适用的场景是会议系统,无需重复传输背景,只需传输人脸关键点信息等即可较好恢复画面,编解码端也可控。新一代的编解码标准(VCM, DCM)也有在往这个方向努力。
接下来分析下以上四种编码方案的应用场景:纯视频编码器,在任何场景都适用,无论是手机、电脑还是pad等等,因为编解码器支持已官方内嵌在各种芯片和解决方案中。AI外层辅助编码器,AI在外层辅助,和编解码的边界很清晰,编出的码流符合规范,各种已有设备也都能播放。AI深入辅助编码器,码流符合标准,可以广泛使用,但需要算法和编码器底层深入协同,公司之间在这个层面合作的可能性较小,且不太适用于硬件编码器方案。纯AI,个人认为在10年之内不会广泛使用,一方面因为算力和标准,它需要各种设备都具备不错的AI算力,然后编解码端需要有大家都认同的标准协议;另外一方面在标准统一后,大规模采用也需要好几年的时间(参考H264/H265等的普及)。
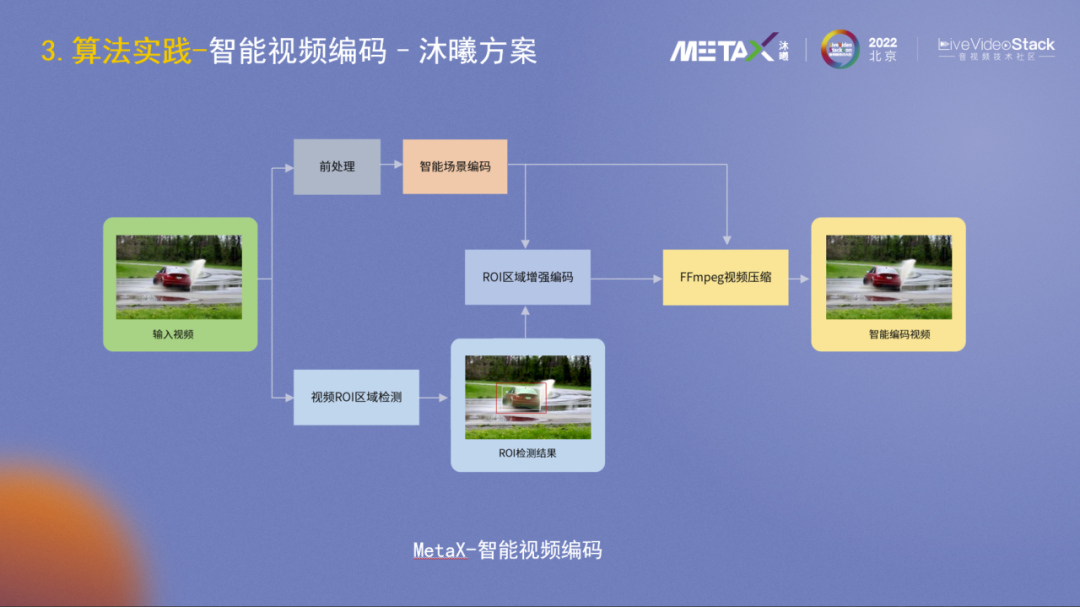
沐曦的智能视频编码方案是AI外层辅助编码,整体框图如图所示。视频输入后分为两路,先进行前处理、场景编码和ROI区域检测,然后再合并进行ROI区域增强编码决策,最后用通用的接口调用FFmpeg框架进行视频压缩。
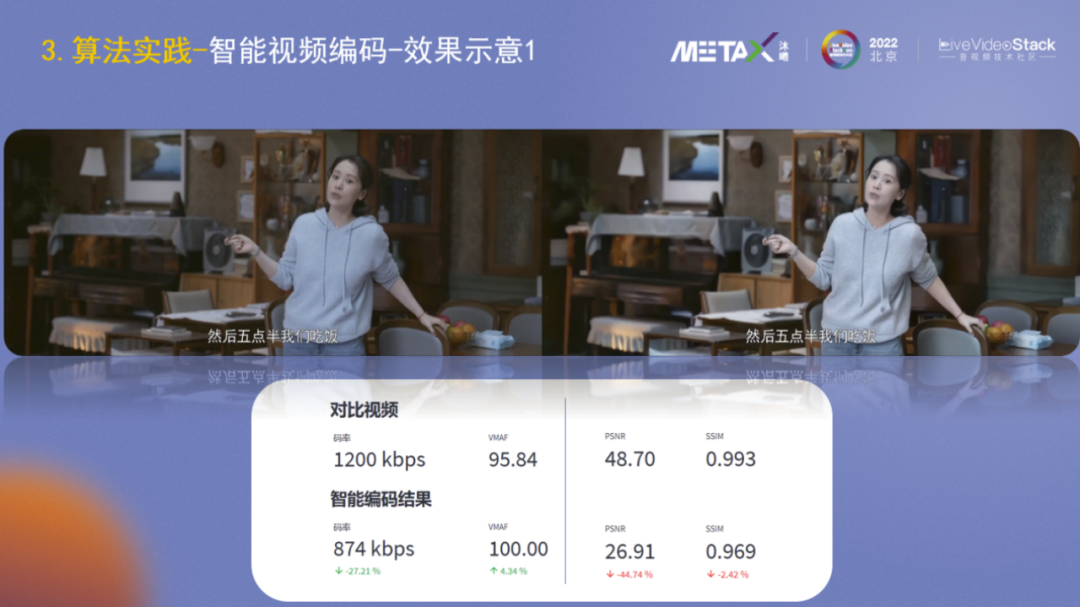
在具体介绍各模块之前,大家先看下智能视频编码前后的效果对比。左侧是H.264默认编码,经过智能编码后,码率下降了27%,主观质量VMAF还有所提高,但PSNR、SSIM有明显下降。
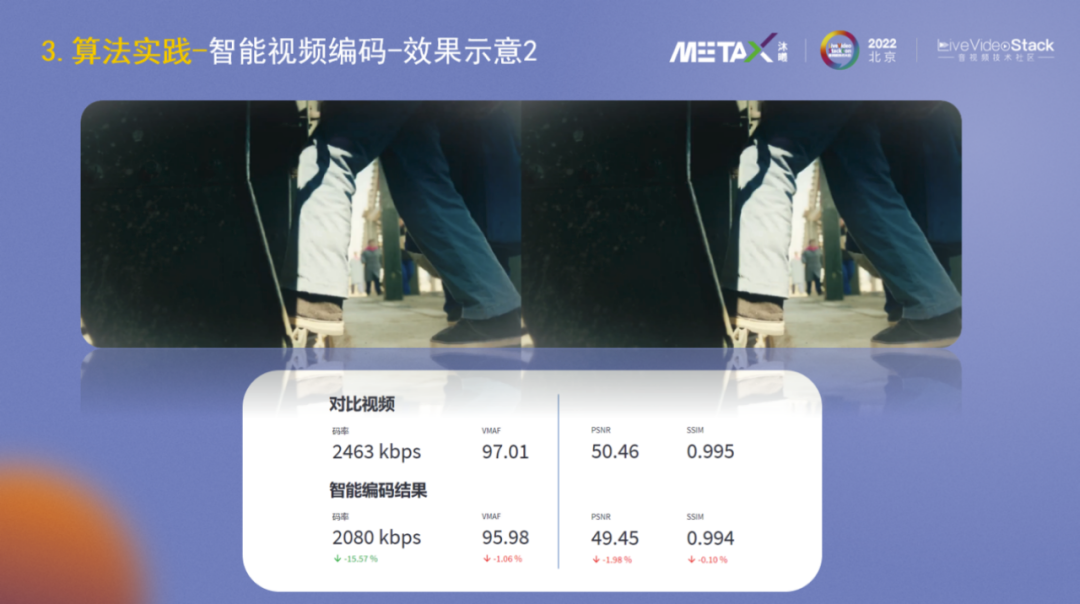
在效果示意2中,视频码率下降了15%,VMAF略有下降,PSNR和SSIM改变也很小,因为视频没有经过前处理。
前处理的底层原理,是人眼视觉系统有一些基础属性,主要包括:对边缘轮廓信息敏感,对运动敏感,对对比度敏感,对高频信息(白噪声、小雪花)不敏感,亮度感受强于色度等。
对原始图片做了修改后差距会变得更大?实际上,压缩总体上是降低质量、模糊图片的过程,前处理阶段会把重要信息先提升起来,再通过H.264/H.265压缩时又降低下去,加减相抵。总体过程使得处理前后的VMAF差距不大,但PSNR降低会较明显。

针对前处理,我们主要做了以下两方面的工作:退化质量修复和主观质量增强。
退化质量修复:视频内容的编码效果不理想,很多时候是输入时的质量就不高,普遍存在的一个质量问题是重复压缩。比如上传一张图片到微信,默认它会进行二次压缩,如果再经过其它应用或手机可能又会压缩一遍,整体画质就会逐步下降。其次是噪声,大部分噪点是拍摄采集端数字化时引入的,另外在传输保存过程中也可能会引入噪声。噪声对编码器很不友好,因为没有规律会引起预测后的编码残差较大,浪费挺多的码流。主观质量增强:人是视觉动物,导演拍摄时会进行场景布置,补光及后期制作,各种设备包括手机等持续优化甚至美化图片,都是为了让拍出来的东西让人感受更好,所以从某种角度看来,并不是要一模一样的真实才有意义。对主观质量的增强,我们主要处理了边缘增强和SDR2SDR+。
下图示例了去失真修复,细节增强以及SDR2SDR+等的效果,对比左侧的原始图片可以看出是明显会更清晰明亮些的。
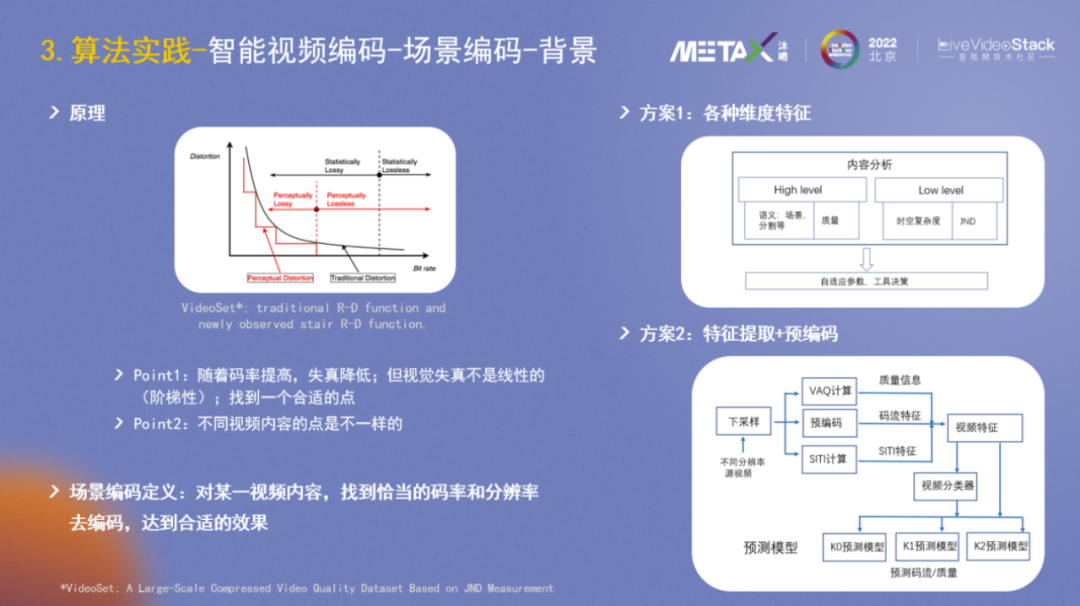
场景编码的原理相信大家并不陌生,视频编码领域的R-D曲线描述了一个基本原理:码率越低,失真越大。论文VideoSet进行了进一步的研究,发觉人的视觉感受并不是光滑的R-D曲线,而是阶梯状的,类似于我们学英语时并不是循序渐进的,而是平稳一段时间然后会突然提升。在AI算法训练侧也有类似现象,Loss很多时候也是一段一段震荡下降的。所以在对一个视频进行压缩时,需要找到一个合适的点,使得Distortion差不多的情况下,Bitrate尽量小。另外,不同视频内容,比如游戏变化较剧烈,动画变化较少,合适的点是不一样的。
综上,可以对场景编码做一个定义:对某一视频内容,找到恰当的码率和分辨率去编码,达到合适的效果。
在过往的音视频大会上,各大厂商也分享了不少的方案,譬如方案1,它会提取各种维度特征如High-level(场景、质量)、Low-level(时空复杂度、JND),然后得到自适应参数进行决策。方案2侧重于特征提取+预编码,即通过下采样、预编码、VAQ计算后得到一些特征,然后再预测码率和编码质量。
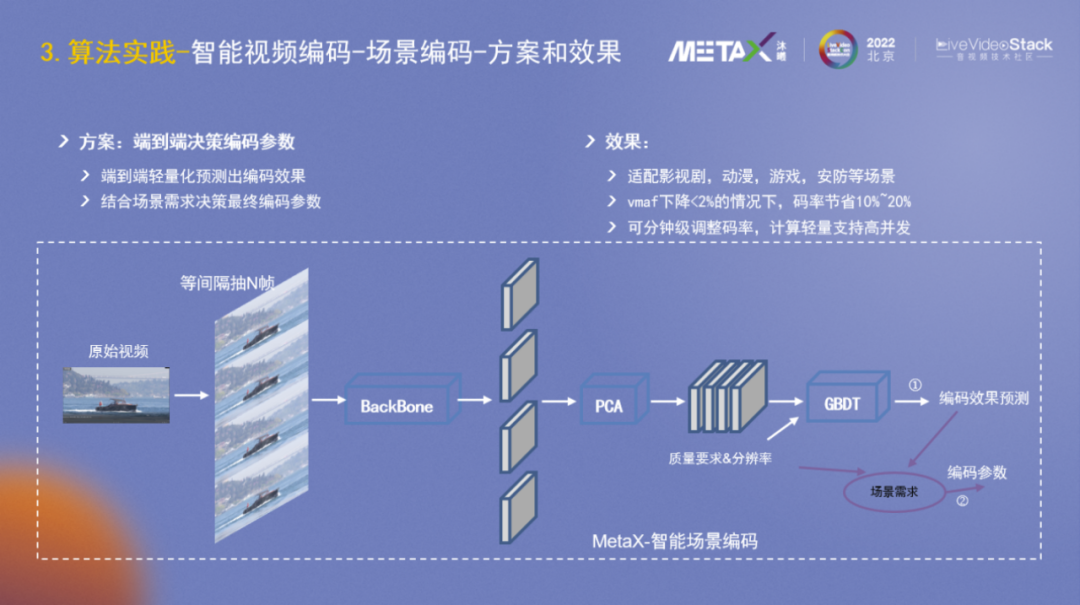
在以上方案的基础上,进一步思考,是否可以直接端到端而非分阶段分类别地提取特征呢?
通过探索尝试,我们设计研发了图中的算法模型和策略,它能够端到端轻量化地预测出编码效果,然后结合场景需求决策出最终的编码参数。模型已经适配影视剧、动漫、游戏、安防等场景。在VMAF下降<2%的情况下,码率节省10%~20%;并且可以分钟级调整码率;计算轻量支持高并发譬如32路。

ROI检测的发展历程大致是中心区域ROI—人脸ROI—字幕ROI—主观感兴趣区域ROI。主观感兴趣区域ROI的难度较大,且因人而异。思考实践后,我们定义重要的前景就是感兴趣区域,然后前景分割技术目前也是比较成熟了。
一个特殊的场景是游戏,如王者荣耀、绝地求生等与当前前景分割的公开数据集领域差异很大,因此在开源预训练模型上的效果很差。此外不同游戏场景的差异也很大,数据标注繁琐且泛化能力差。我们的研发目标是带普遍意义的基础解决方案,是否存在一种避免数据标注然后泛化性高的算法能力,能够自动在各种游戏场景分割检测重要目标,譬如英雄?
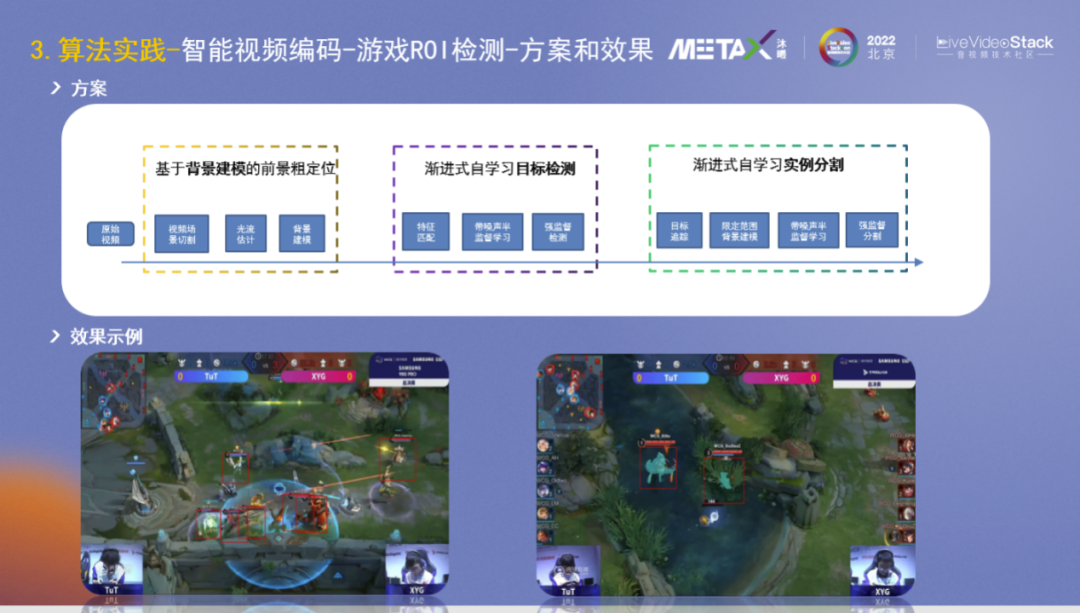
我们的检测分割方案大体可以分为三个研发阶段:
1、基于背景建模的前景粗定位:基于人眼对运动物体的敏感,先对视频进行场景分割,然后在做光流估计,再结合背景建模算法,可以较粗糙的检测出来英雄。
2、渐进式自学习目标检测:再结合特征匹配和带噪声的半监督学习,可以训练出一个模型较细致地框出英雄。
3、渐进式自学习实例分割:在前两个阶段的基础上继续努力,进行目标追踪,限定范围内的背景建模等,可以很好地进行实例分割。
下方是效果示例,这些游戏视频并没有标注任何训练图片,是通过纯算法学习出来的。

检测出感兴趣区域后,接下来的问题是来应该分配多少码流对它进行编码。
方案1的实现是第三种视频压缩方案,它和编码器深入融合,通过分析统计所有宏块的QP,然后根据目标,譬如30%码流分给20%ROI区域,修正得到各QP值并进行配置。
基于AI外层辅助编码,我们避免在帧内进行数据交互,而是考虑直接在帧级别控制。
FFmpeg开放了dqp(delta-QP)进行区域调整,整个问题可以抽象为决策问题:设置全图、ROI区域、过渡区域的dqp值以及设置过渡区域的大小。具体方案充分利用了AI的能力,端到端的直接学习预测,可以较好地解决这一问题。
从效果上看,ROI检测结合专家知识能节省~5%的码率;然后在相同VMAF下,ROI决策相比专家知识能额外节省~3%的码率。
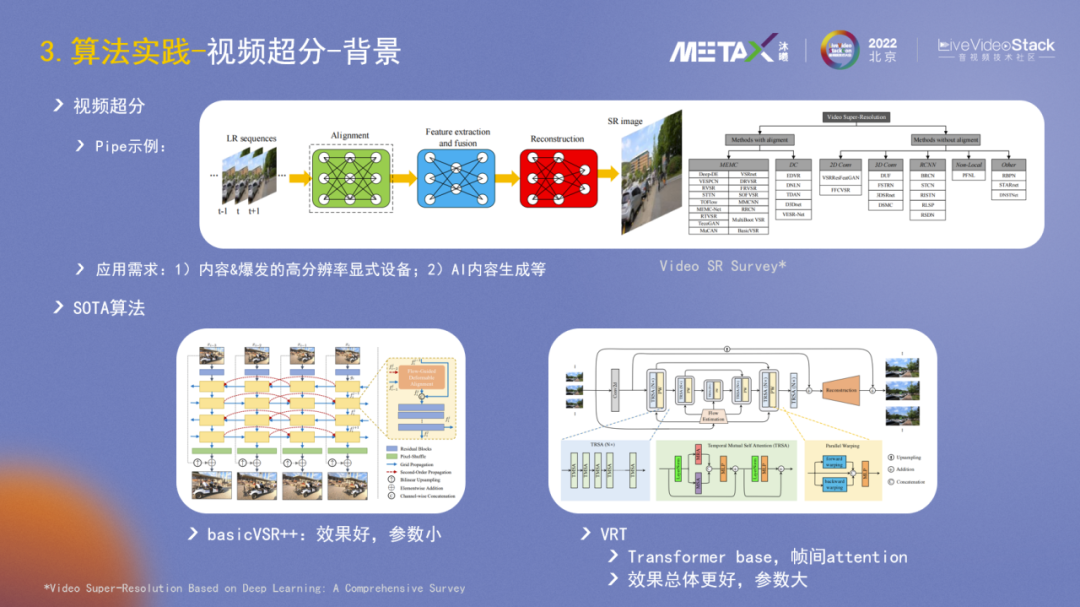
视频超分方面,随着显示设备如电视机等越来越大,一个重要需求是在影视剧等视频内容上,可以是视频内容的源侧做超分提升内容质量;也可以是在终端侧做超分提升显示效果。另一个可见的大需求是AIGC,超分模块会和diffusion模块协同生成video。
Video SR Survey这篇文章较好地总结了超分pipeline和主流的方法。整个过程可描述为输入低分辨率视频序列,进行图像数据的对齐,然后做特征提取和融合,最后进行重建。右侧归纳总结了一些主流的算法模型,包括运动估计、光流、2D/3D卷积等。
2022年有两个SOTA算法,一个是basicVSR++,基于LSTM做特征的双向传播,需要的帧不多,对齐技术用光流;另一个是VRT,使用Transformer结构,用QKV而非传统光流做特征的匹配融合,总体效果更好,但参数量也更大。
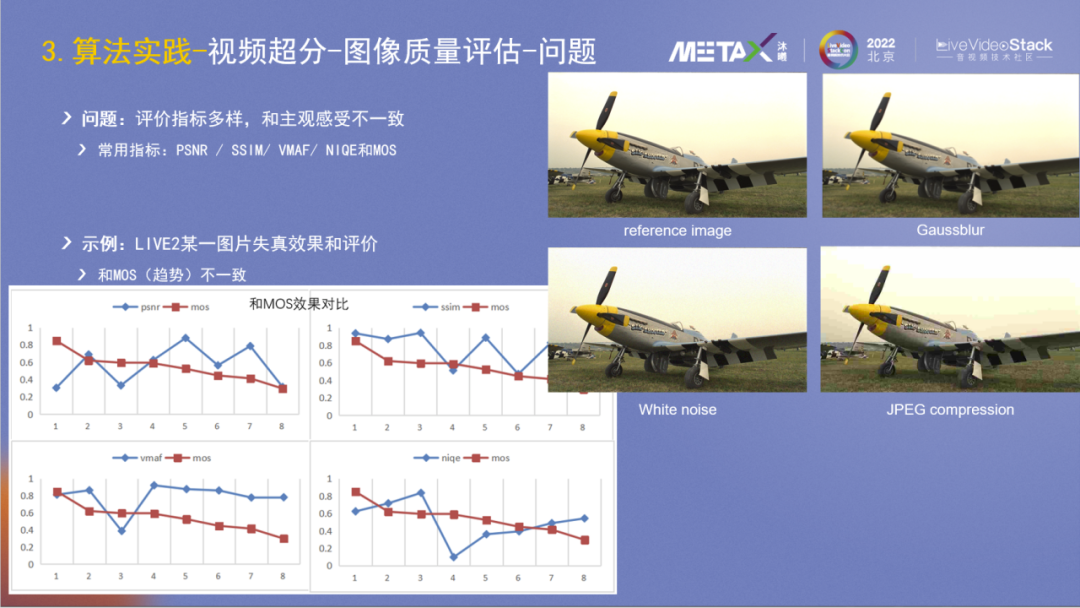
算法研发特别重要的是评价,在超分所属的图像质量评价领域,已有PSNR/SSIM/VMAF/NIQE等四个自动化的客观指标;也有MOS的主观评价,代表了人的主观感受,但它是人工的所以获取成本较高。在超分算法等研发过程中,时常会出现多个客观指标评价不一致的情况,那如何判断迭代中的算法效果是否正向呢?
右侧是LIVE2的图片示例,图1是reference image,图2做了Gaussblur,图3加了白噪声,图4加了JPEG压缩。主观看来图3和图1比较好,图2和图4看起来较差。
左下角是不同指标的对比结果,它包含了八种不同的失真方式,包括JPEG compression、JPEG-2000 compression、Gaussian blur、White noise、Bit error等。红色曲线是MOS的结果,可以看出其它4个客观指标与MOS的表征都不一样,或者说它们都不能很好地反应图片主观质量。

再来看一个具体案例,它们是使用了SwinIR-GAN和BasicVSR++的图片效果。右图的PSNR指标较好,但人的主观感受应该是左图较好。

针对指标不一致的问题,能否有更强表征能力的指标?我们设计了一个基于集成学习的更有MOS表征能力的指标stackMosScore。在数据集侧搭建了包含主观评价的数据集和其它影视剧的数据,然后使用当前的4个客观指标作为基础做集成学习,目标是拟合MOS。
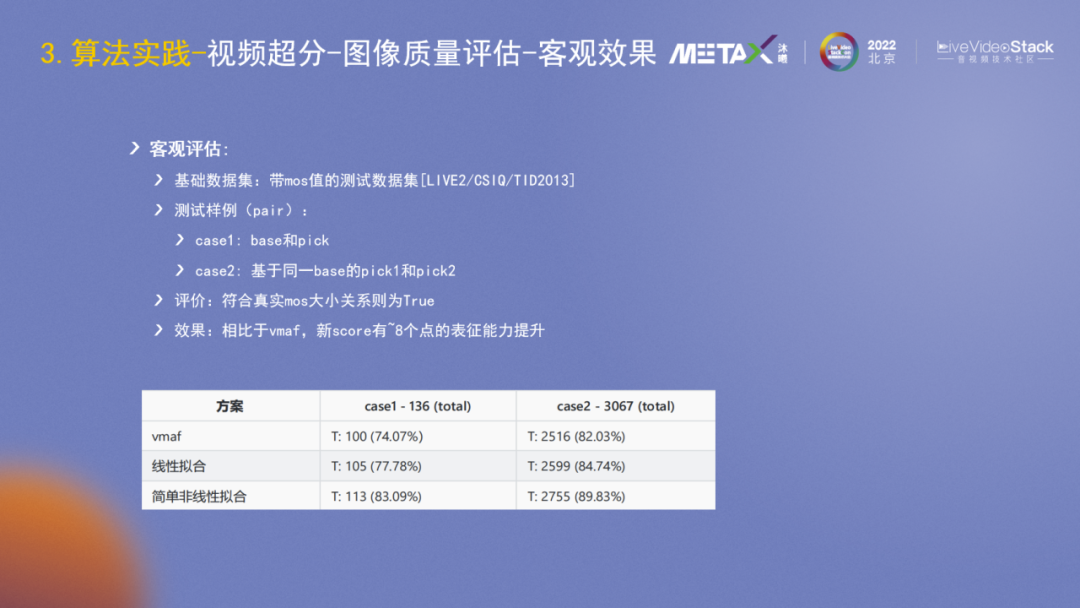
从评价数据集上看,它比原来最好的VMAF高出7个点,更好地表征了人的主观感受。

这里是一个图片示例,stackMosScore较好地表征了3张图片的质量好坏关系。
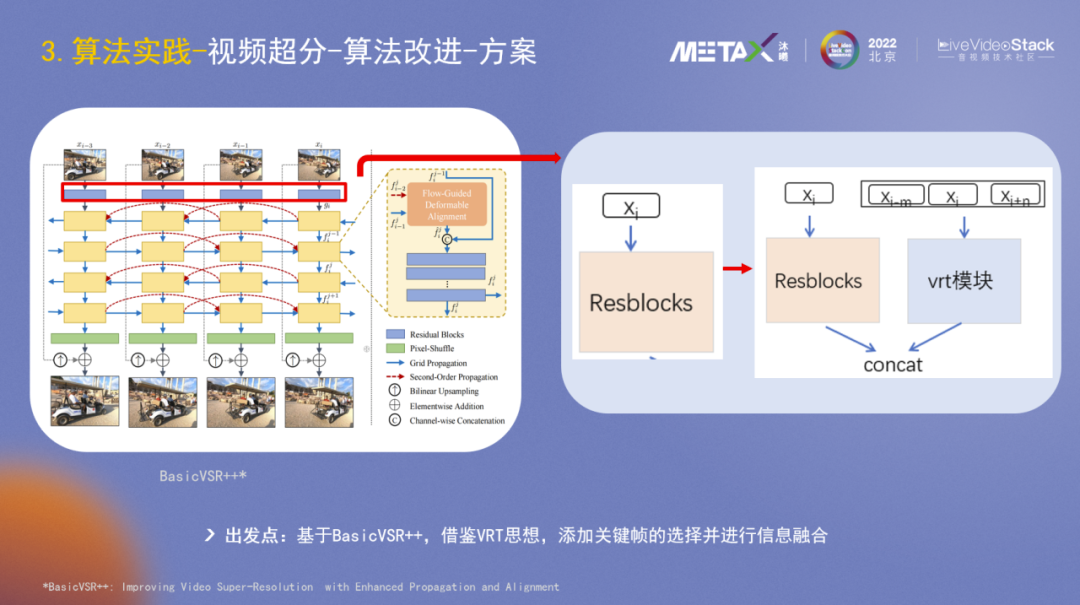
在算法模型层面我们也做了一些探索尝试,采用BasicVSR++的主体结构,借鉴VRT思想,添加了关键帧的选择并进行信息融合。

实际场景一般是两倍超分,在影视剧数据集的评测上,PSNR提升0.18db。
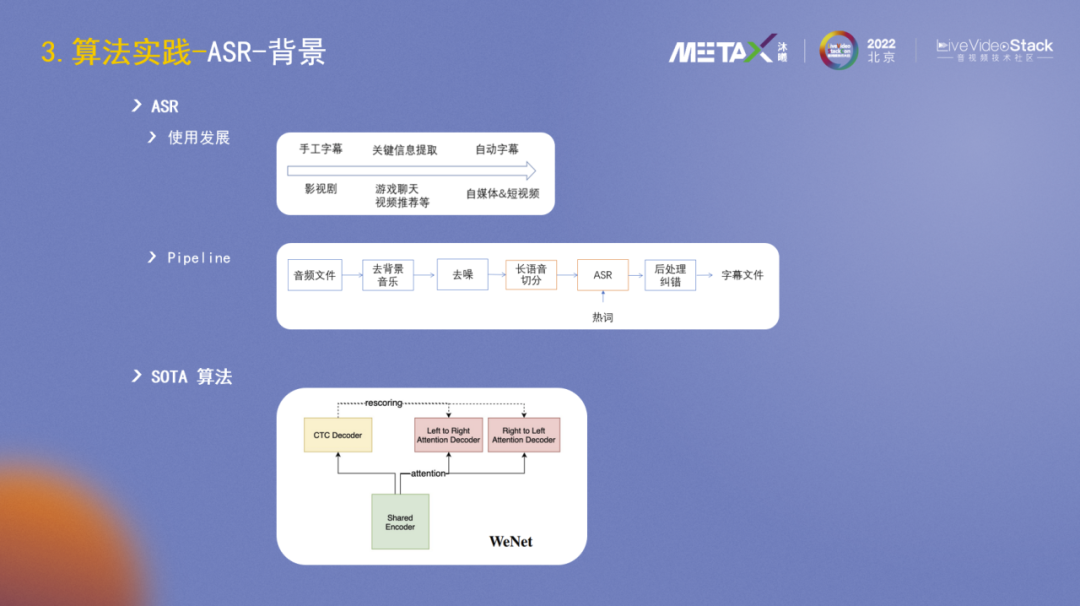
最后介绍下ASR方面的一些实践。ASR的一个重要应用场景是字幕。影视剧早期是手工字幕,随着互联网平台的发展壮大,ASR在内容审核侧会做一些关键词的提取,在自媒体时代,短视频和直播蓬勃发展,ASR被广泛用来自动生成字幕。
字幕生成的Pipeline大致可分为:去背景音乐、去噪、长语音切分、ASR识别、后处理纠错和输出字幕文件。
ASR的SOTA算法是WeNet(2),它很好地将实时语音识别和离线语音识别两个分支进行了统一。

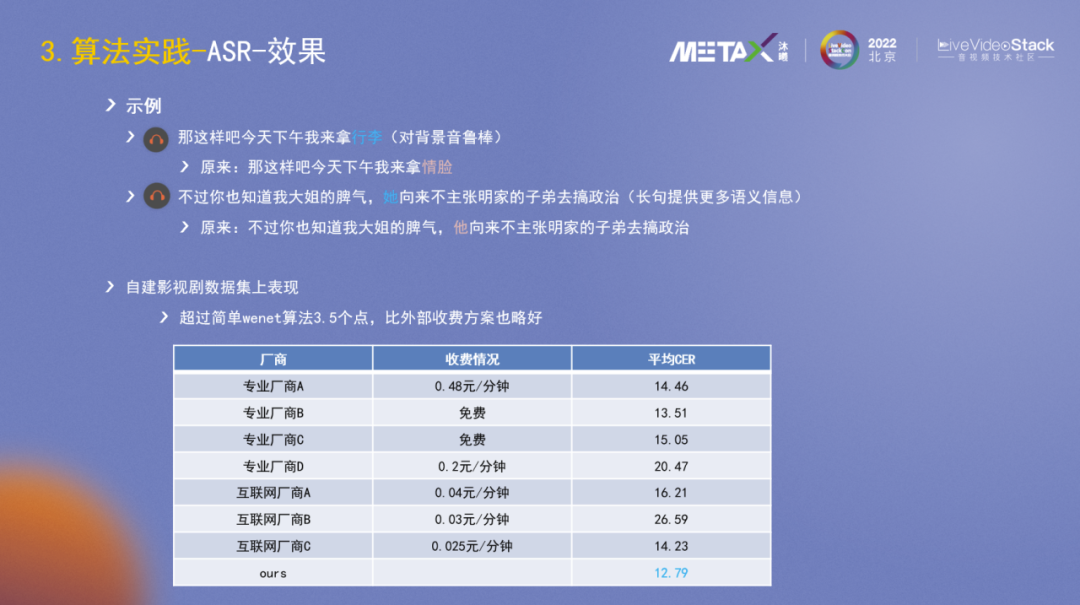
然后我们主要在长音频的切分和ASR算法上做了一些改进尝试,具体包括热词(来自演员表或手动设置),语音增强(去背景音,去噪),短音频合并成长音频优化(适当合并短音频成长音频,10-15s),WeNet模型加噪声以及背景音语料微调,解码参数微调(模型层面提升对噪声和背景音的鲁棒性)。
04-后续工作
后续工作,在算力方面,曦思®N100已进入小规模量产阶段,接下来会继续优化提升软件栈等来提升全局性能。在解决方案(算法)方面主要包括:
- 协同优化效果:在核心场景,譬如智能视频编码,在模块间更好地上下协同,提升效果;
- 系统性性能优化:结合N100芯片的特点,优化算法的网络结构乃至方案等;
- SDK化部署:整合智能编码、超分、ASR等的能力,提供基础的sdk能力作为第三方的基础解决方案。
以上是本次的分享,谢谢!
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。