
今天,Meta的首席AI科学家Yann LeCun在推特上宣布了MetaAI的最新研究成果:MMS,一个支持1107种语言的自动语音识别模型和语音合成模型,该模型自动语音识别的单词错误率只有OpenAI开源的Whisper的一半!但是支持的语言却有1107种,是Whisper的11倍!代码与预训练结果已开源,不过不可以商用哦~
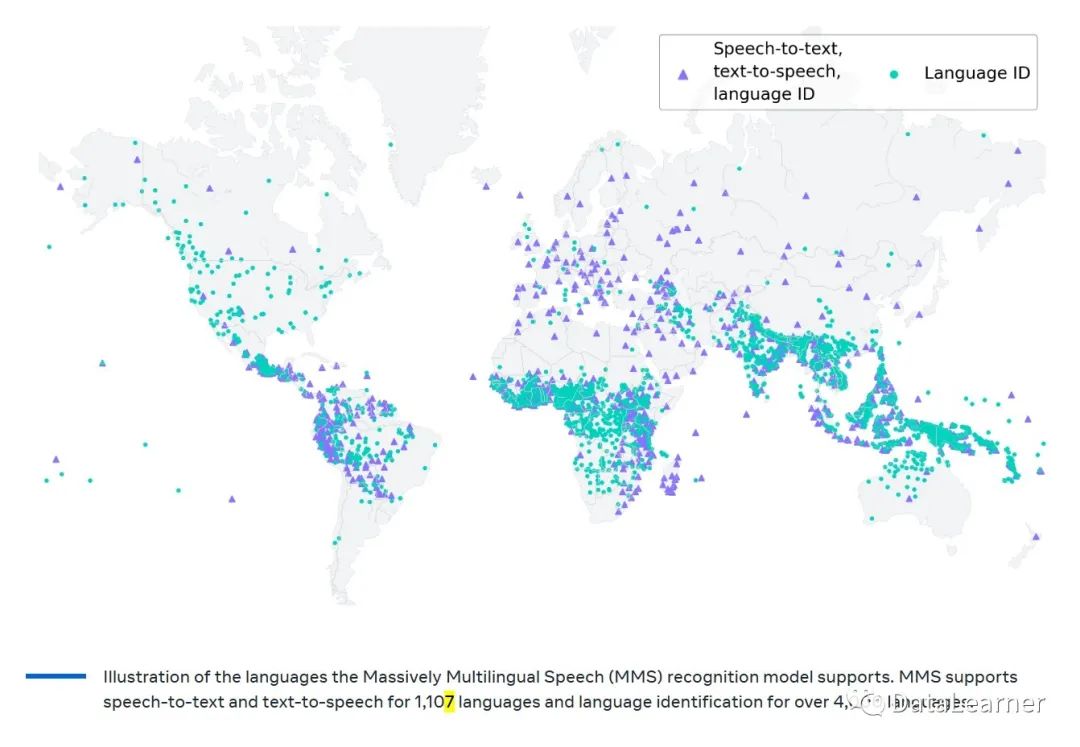

本文将介绍MMS的原理,主要说明在缺少大规模标注数据集的情况下,MetaAI是如何实现支持这么多语言的模型的。MMS模型卡信息:https://www.datalearner.com/ai-models/pretrained-models/MMS
MMS模型简介
MMS模型全称Massively Multilingual Speech,是MetaAI发布的一种语音模型,该模型支持自动语音识别(Auto Speech Recognition,ASR)和语音合成(Text-to-Speech,TTS)两种任务。
目前全球共有7000多种语言,但是现有的语音相关的模型只能覆盖其中的一百多种。由于缺少数据的支持,大部分语言的语音识别和合成都十分困难。
而MetaAI想到了一个好方法,就是利用宗教文本的录音数据,如圣经。这些文本已经被翻译成许多不同的语言,并且这些翻译的音频录音是公开可用的。这种方法使得MMS模型能够覆盖超过4000种语言。
MMS模型的原理和技术方案
MMS(Massively Multilingual Speech)模型是的目标是将语音技术从大约100种语言扩展到超过1000种语言。为了实现这个目标,MMS模型采用了一种新的数据集和wav2vec 2.0模型的结合。
wav2vec 2.0是Facebook AI的一个自我监督学习的先驱工作,它可以在无标签数据上进行训练。在wav2vec 2.0的帮助下,MMS模型能够利用大量的无标签音频数据进行训练。
在训练过程中,MMS模型会学习如何正确地识别和“理解”音频数据,从而能够识别出超过4000种语言,并能够以1100多种语言进行语音合成(文本转语音)。
MMS创建的语音识别和语音合成相关的数据集
在这项工作中,MetaAI创建了好几个数据,主要包括MMS-lab、MMS-lab-U以及MMS-unlab。
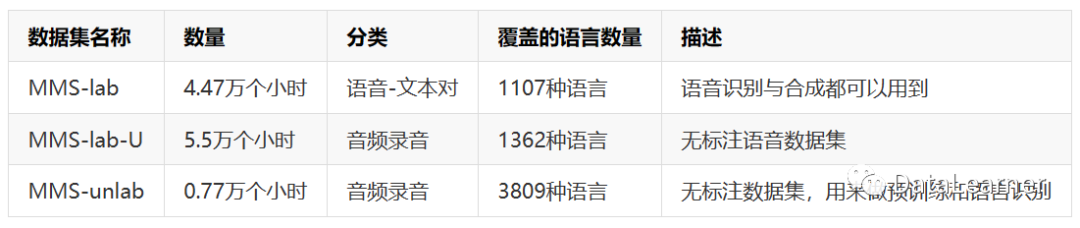
这些数据集与现有的语音类的数据集比较如下:

可以看到,不论是支持的语言数量和语音数据集的时长,MetaAI的MMS相关数据集都是很有优势的。
MMS模型的实验测试结果
MMS在自动语音识别(ASR)任务测试结果
首先,在自动语音识别(ASR)任务上,MMS与OpenAI的Whisper做了对比,结果如下:
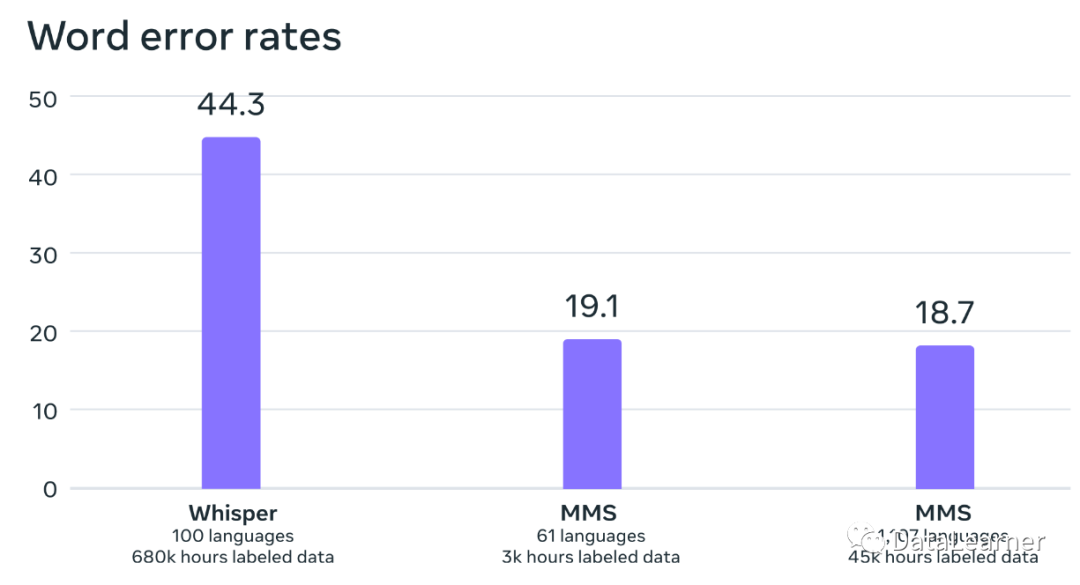
可以看到,MMS支持的语言是Whisper的11倍,但是其单词错误率只有它的一半。使用的数据集也比Whisper少很多。
MMS在语言识别( language identification (LID))任务测试结果
接下来,MetaAI训练了一个语言识别的模型,对比了业界的开源模型SpeechBrain和AmberLet:
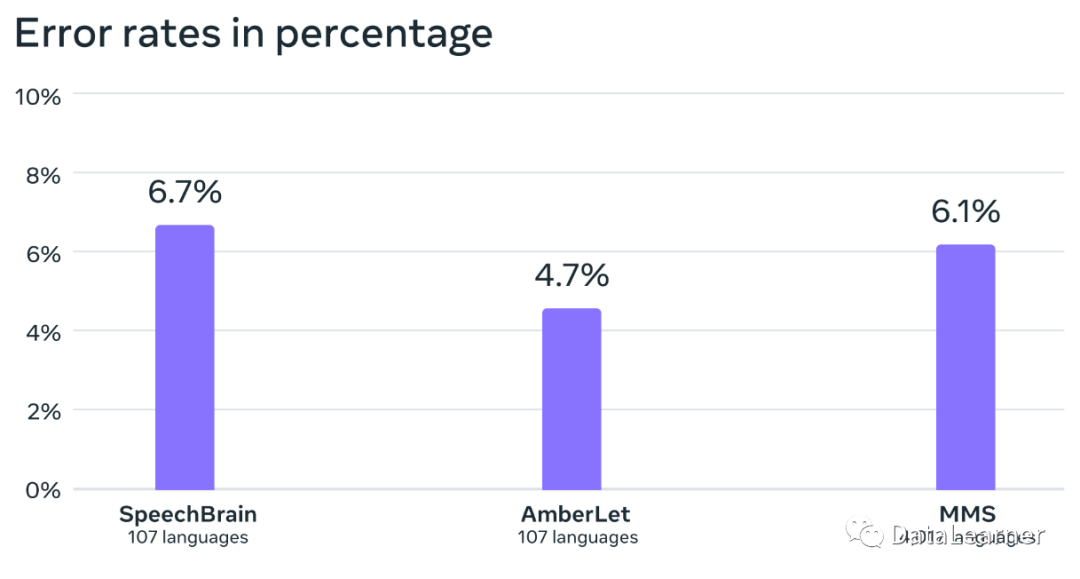
可以看到,虽然MMS的模型效果不是最优的,但是它可识别的语言数量是其它模型的40倍。不过这也是因为在部分语言上的效果不太好拉低的。
MMS在语音合成(TTS)任务上的效果
MetaAI也在语音合成任务上做了比较
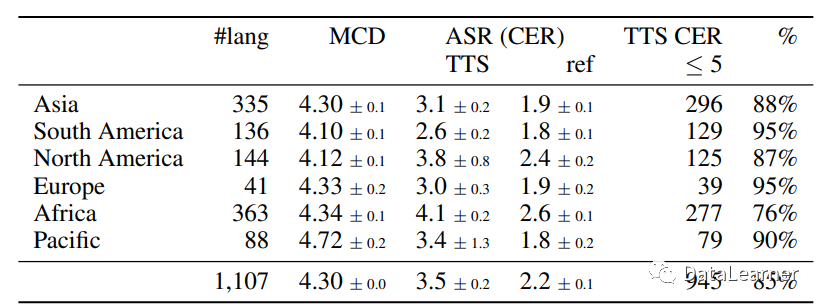
从TTS和人类话语之间的CER的微小差异可以看出,MMS系统保留了大部分原始内容。
MOS分数也表明,与人类话语相比,MMS的系统声音质量较低,但在领域内数据上的差异并不是很大。不幸的是,正如前面提到的,由于FLEURS音频中的嘈杂语音,领域外的MOS分数受到了影响。因此,MetaAI得出结论,基于MMS-lab数据训练的TTS模型在领域外表现良好。
MMS模型的开源资源
一如既往的,作为AI开源领域的优秀课代表,本次MetaAI发布的MMS模型依然是开源的。并且开源资源相当丰富,包括模型的数据集、基础模型、ASR模型、语言识别模型预训练结果都有开源。但是,开源协议为CC-BY-NC 4.0 license,不可商用!
MMS模型开源的资源包括预训练模型checkpoints、微调模型checkpoints、语言识别模型checkpoints、TTS模型checkpoints、ASR模型checkpoints,以及相关的数据集。
MMS模型总结
MetaAI发布的MMS模型优点明显,吸引力很多的关注和讨论,尽管有些人测试说结果没有他们说得好,但这也需要大家自己验证。总结一下MMS的信息:
- MMS模型是一个大规模多语言语音(Massively Multilingual Speech)项目,它能够识别超过4000种语言,并能够以1100多种语言进行语音合成(文本转语音)。
- MMS模型的创建是为了解决现有的语音识别模型只覆盖大约100种语言的问题。MMS模型通过结合wav2vec 2.0(自我监督学习的先驱工作)和一个新的数据集,这个数据集为1100多种语言提供了标签数据,为近4000种语言提供了无标签数据。
- MMS模型的训练数据来源于宗教文本的音频录音,例如圣经。这些文本已经被翻译成许多不同的语言,并且这些翻译的音频录音是公开可用的。
- MMS模型的性能超过了现有的模型,并且覆盖的语言数量是现有模型的10倍。与OpenAI的Whisper模型相比,使用MMS数据训练的模型的词错误率只有Whisper的一半,但MMS覆盖的语言数量是Whisper的11倍。
- MMS模型的代码和模型已经公开,以便研究社区可以在此基础上进行构建。
作者:DataLearner
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。