
本次演讲主要介绍了两种使用机器学习技术来优化实时编码器的方法,包括利用机器学习进行preset自动配置,以及使用机器学习来进行实时的CU划分技术。这两种方法可以有效利用硬件资源,降低部署成本以及提高压缩效率。
来源:MHV 2022
主讲人:Nelson Francisco
内容整理:张一炜
视频编码技术的发展
视频编解码器的发展使得压缩效率每10年就能提高一倍。其效率的提高主要来自于可用编码工具的增加,包括更多的预测模式,更丰富的块大小,更灵活的GOP结构和参考,以及更高的运动估计精度。编码工具的数量和复杂度的增加直接导致了编码器计算成本的增加。而在实时场景中,还需要考虑硬件资源的限制,不能接受太高的复杂度。
在x264以及x265的实现中, 定义了不同的CPU presets,以提高能够权衡压缩效率与计算消耗的功能。在快到慢的presets中,编码工具的使用逐渐受到限制以减小计算复杂度的要求。
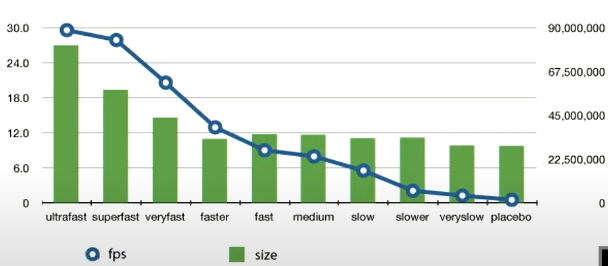

然而其中存在问题在于,preset的个数有限,只能提供粗粒度的控制。另外,preset的设计主要是针对的一般的内容,并不能保证对于所有的内容都能适用,不同的内容所倾向适用的工具是不同的。
在这方面,过去许多使用AI的方法往往需要大量的计算,并且这些方法能够带来的性能提升都是在参考编码器中进行评估的,并没有完全为实时运行进行优化,隐藏了真正的计算成本。使用机器学习能够以更少的成本获得相同的效率。所以,演讲者提出了使用机器学习来实现压缩性能与计算复杂度之间更灵活的权衡,并最大化利用有限的硬件资源。
方法介绍
preset自动配置
通常来说,不同的内容会呈现出不同的特性,因此在压缩性能上可能会受益于不同的编码工具。例如,计算机生成的卡通图画更关注其中的纹理细节,对于运动估计的准确性要求不高,而对于体育相关的视频,由于时域掩蔽的存在,对于细节信息就不需要太多的关注,而是应当更加关注于准确的运动估计。因此,演讲者对不同内容视频在压缩过程中,不同工具的硬件资源消耗进行了统计,

对于不同的类型的视频,如果使用相同的preset来控制压缩效率和复杂度的权衡可能不是最优的。因此,需要能够根据视频内容的不同,在压缩效率和复杂度的权衡中给予不同工具一个根据内容变化的重要性参数。
具体来说,演讲者提出了一个preset manager来实现上述功能。如下图所示。这个管理器中,需要输入一部分的先验信息,包括当前CPU的计算能力,目标编码时间与码率,以及编码格式等,并结合 look ahead 编码中的信息,来获得对输入内容的描述信息。根据这些信息,编码器可以了解到编码当前内容时主要的复杂度消耗在具体的哪一个编码工具上。
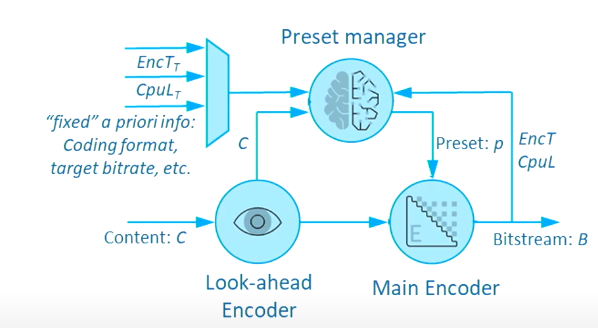
在图中,编码器到 preset manager之间还存在一个反馈连接,用于提供给 preset manager 当前 CPU 的负载情况以及剩余的编码时间。preset manager以此来对当前的preset设置进行动态的调整,以确保所有的硬件资源都能够得到充分的利用。
性能对比
对于传统的preset设置来说,大部分情况下硬件资源都没有得到充分的利用,只有在处理体育比赛视频这类比较复杂的视频时,硬件的利用率才会较高。而在使用上述的基于机器学习的自适应preset配置时,可以根据内容的不同,给予对性能影响最大的工具更多的计算资源,以实现硬件资源的充分利用以及视频质量的提升。传统的preset与自适应preset对硬件资源利用的对比如下图所示。
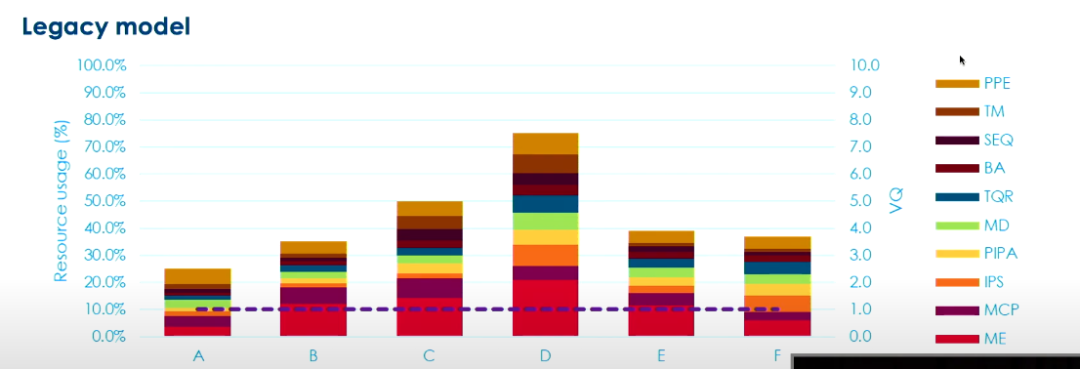
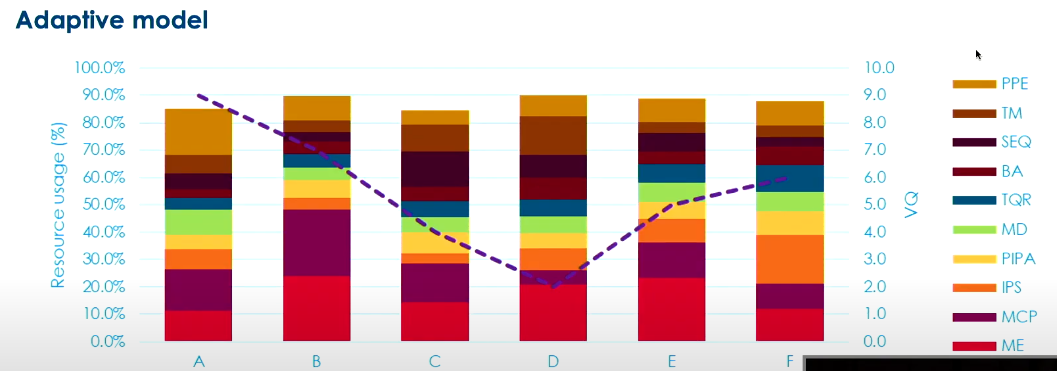
使用这种自适应配置的好处在于,在编码配置的设计时不需要考虑最坏的情况,自适应的preset配置可以拟合不同内容需要的复杂度分配方式,并以不同的控制方式来处理不同的内容。这使得在编码时不会出现因为内容过于复杂而不得不导致质量大幅下降以及丢弃帧的问题。
并且,传统的preset能够调整的点有限,不能够充分利用硬件资源是经常会发生的事情。而在使用上述自适应的配置后,能够根据计算资源以及编码时间的反馈动态调整preset的设置,继而实现对计算资源的充分利用。
该技术也可以降低运营成本,通过自动激活编解码器的算法和工具,以提高视频质量,不需要预先定义质量预设。以一个OTT频道为例。与固定的预设模式相比,1080p分辨率下利用该技术,可以为相同数量的vCPU,定义运行固定预设的配置。实验结果表明在相同的视频质量(SSIM)下可以带来平均19%的增益,最高可以达到40%,且具有内容普适性。
基于AI的实时HEVC CU划分
另一方面,演讲者也介绍了他们将AI技术用于底层的编码策略上的方法。一般来说,在高码率低QP的操作点下,编码器更倾向于使用更精细的CU划分方式,如下图所示。但在高码率下仍然可以看到一些CU不需要划分的过于细致,例如包含草地的图像块。
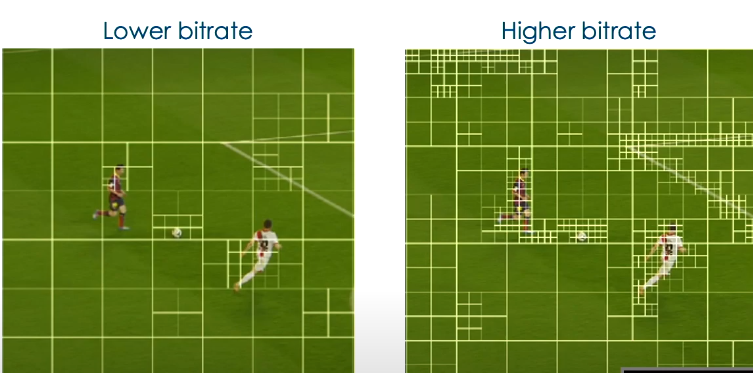
在具体的方法中,首先使用编码器生成一个离线数据集,数据集中包含了多种不同的内容,多个不同的QP点以及多种不同的编码配置。通过编码器使用完全的RDO来得到最优的划分方法。并且由于是考虑实时场景下的应用,因此在RDO时就对帧内以及帧间编码的复杂度考虑,从预测的残差、图像块的梯度以及MV的编码消耗等进行计算。
随后,将离线获得的完全RDO的最优结果作为Groud Truth来进行训练。具体使用的方法与训练方式可以不同。最后,则将训练好的模型部署在编码器,利用look ahead编码的结果进行轻量的推理得到最优的CTU划分结果。
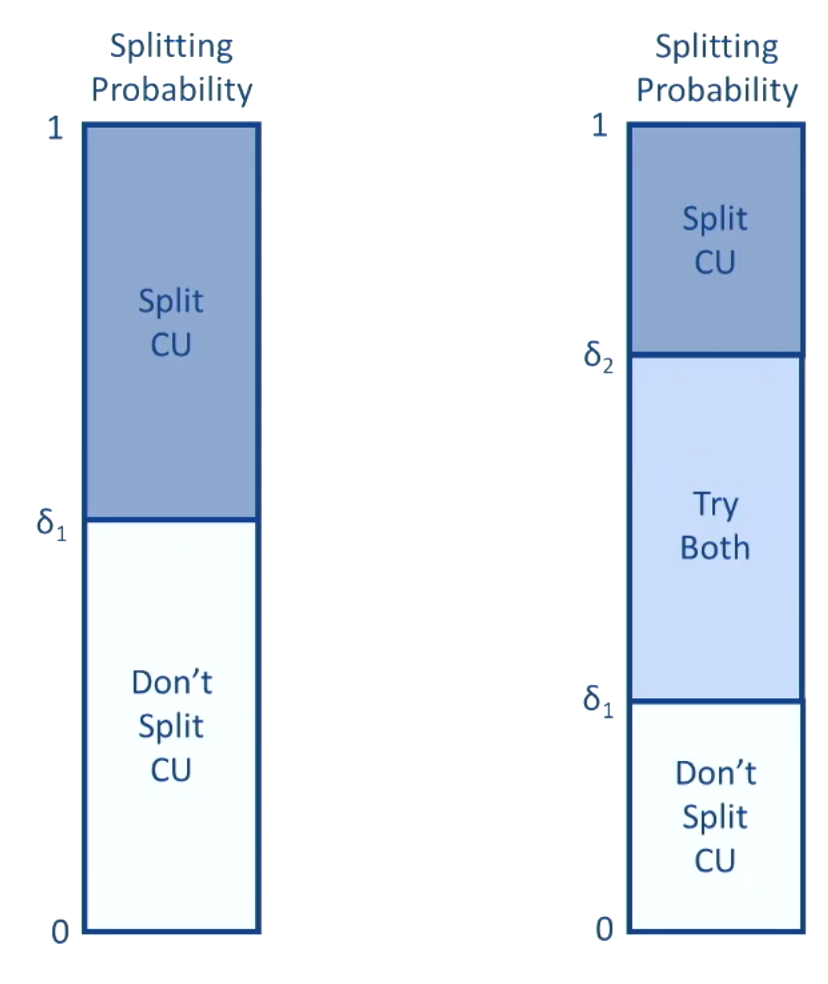
通常来说,机器学习中输出的是不同划分模式的概率大小,因此可以设计使用不同的决策方法而不是简单的单一决策,单一决策阈值与双决策阈值的区别如下图所示。如果概率大于一定值则使用该划分方式,小于一定值则不使用。而当概率在一定阈值之间时,则会分别计算划分与不划分的代价来决定最优的模式。
并且,该方法也可以和上述的自动配置方法结合在一起。当自动配置中决定可以使用更复杂的编码模式时,可以加大中间两种划分模式都尝试的阈值区间来实现更好的压缩性能。
在测试结果上,该方法可以在4k@60fps的实时编码中,在SSIM作为评价指标下,可以带来大约10%的压缩性能增益,并且复杂度方面相比于参考编码器,从低码率到高码率只需要82.5%~97.5%的复杂度。
总结
- 类似的基于机器学习的方法也可以用在其他的底层编码决策上。例如估计预测模式的似然,减小帧内编码的方向个数,以及skip mode预测。
- 基于机器学习的技术可以利用标准CPU的SIMD指令集来实现高效推理,实现实时编码,并且不需要专用硬件来实现,避免额外的硬件上的开销。基于AI的技术也可以有效优化视频质量和硬件资源使用率,减小部署成本。
- 机器学习技术在复杂的数据模式下以及同时包含high-level和low-level数据的决策中,可以表现的更好。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。