
本文是对 ELECARD Video Compression Book 第一章的翻译。本章节包括视频压缩技术的基本信息:简要历史、视频编码的阶段、AVC/H.264和HEVC/H.265标准的主要算法。
标题:Video encoding in simple terms
链接:https://www.elecard.com/page/video_encoding_in_simple_terms整理人:陈予诺
简短的历史概述
第一个被广泛接受的视频压缩标准MPEG-2于1996年被采纳,随后数字卫星电视得到了快速发展。下一个标准是MPEG-4 part 10(H.264/AVC),它提供了两倍的视频数据压缩率。它于2003年被采纳,导致了DVB-T/ C systems、互联网电视的发展以及各种视频共享和视频通信服务的出现。从2010年到2013年,联合视频编码联合协作小组(JCT-VC)积极致力于创建下一个视频压缩标准,开发者称之为高效视频编码(HEVC);它实现了数字视频数据压缩率的两倍增长。这一标准于2013年获得批准。同年,由谷歌开发的VP9标准被采纳,据称在视频数据压缩率上不逊于HEVC。
视频编码的基本阶段
视频数据压缩算法的核心有一些简单的概念。如果我们取图像的某个部分(在MPEG-2和AVC标准中,这部分被称为宏块),那么很可能在这一帧或相邻帧中,会有一个包含类似图像的部分,其像素强度值相差不大。因此,为了传输有关当前部分图像的信息,只需传输它与先前编码的类似部分的差异即可。在先前编码的图像中寻找类似部分的过程称为预测。确定当前部分与找到的预测之间差异的一组差值被称为残差。在这里,我们可以区分两种主要类型的预测。第一种类型的预测中,预测值代表当前图像块左侧和顶部相邻像素的线性组合。这种类型的预测称为Intra Prediction。第二种类型的预测中,使用先前编码帧中类似图像块像素的线性组合作为预测(这些帧称为参考帧)。这种类型的预测称为Inter Prediction。在解码时,为了恢复使用Inter Prediction编码的当前图像块,需要有关于残差以及相似部分所在的帧编号和该部分的坐标信息。
显然,在预测过程中得到的残差值平均含有比原始图像更少的信息,因此在图像传输中需要更少的比特。为了进一步增加视频编码系统中视频数据的压缩程度,通常会使用一些频谱变换。通常情况下,使用傅里叶余弦变换。这种变换使我们能够选择二维残差信号中的基本谐波。在编码的下一个阶段 – 量化中进行了这种选择。量化后的谱系数序列包含少量主要的大值,其余的值很可能是零。因此,量化后的谱系数所包含的信息量明显(几十倍)低于原始图像。
在编码的下一个阶段,得到的一组量化的谱系数连同解码时执行预测所需的信息,将被进行熵编码。这里的关键是将编码流中最常见的值与最短的码字(包含最少的比特数)对齐。在这个阶段(接近理论可实现的)最佳的压缩比的算法是算术编码算法,其主要用于现代视频压缩系统中。
从上面可以看出,影响特定视频压缩系统效率的主要因素如下。首先是决定Intra和Inter Predictions效率的因素。第二组因素与正交变换和量化有关,它选择了残差信号中的基本谐波。第三组因素由伴随残差的附加信息的量和紧凑性、以及解码器中用于进行预测计算的必要信息的表示量决定。最后,第四组因素主要关于熵编码的效率。
让我们以H.264/AVC和HEVC为例,说明上述编码阶段的一些可选项(远非全部)。
AVC标准
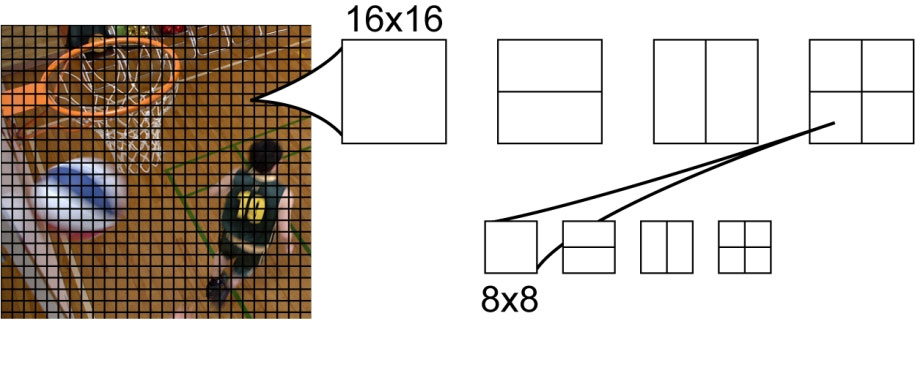
在AVC标准中,图像的基本结构单元是宏块 – 一个16×16像素的正方形区域(图1)。在寻找最佳预测时,编码器可以选择多种分割每个宏块的选项。在Intra预测中,有三个选项:对整个块进行预测,将宏块分成4个8×8大小的正方形块,或者分成16个4×4像素大小的块,并分别对每个块进行独立预测。在Inter预测下,宏块分割的可能选项更加丰富(图1),这样可以根据视频帧中移动的物体边界的位置和形状,调整预测块的大小和位置。

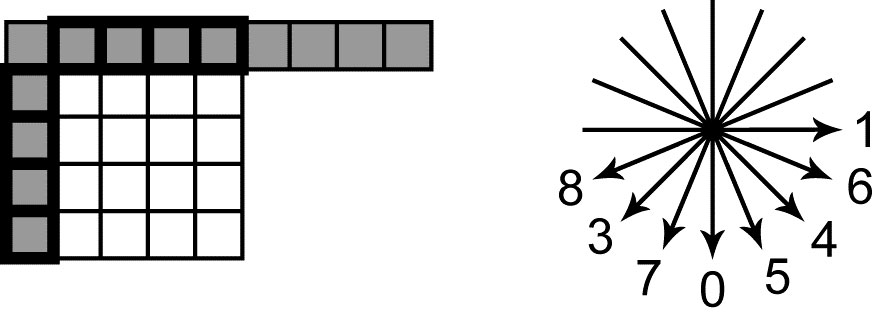
在AVC中,用于Intra预测的是预测块左侧列的像素值以及其上方的像素行(图2)。对于4×4和8×8大小的块,使用了9种预测方法。在一种名为DC的预测中,所有计算出的像素都具有与图2中加粗线标识的“邻近像素”的算术平均值相等的单个值。在其他模式中,执行“角度”预测。在这种情况下,“邻近像素”的值按照图2中指示的方向放置在预测块内。
如果预测的像素位于“邻近像素”之间,在朝特定方向移动时,预测时会使用插值。对于大小为16×16像素的块,使用了4种预测方法。其中之一是DC预测。另外两种对应于“角度”方法,具有预测方向0和1。最后,第四种是Plane预测:预测像素的值由平面方程确定。方程的角系数由“邻近像素”的值确定。
在AVC中,Inter-Prediction可以以两种方式之一实现。这两种选项中的每一种都确定了宏块的类型(P或B)。作为P块(预测块)中像素值的预测,使用了位于先前编码(参考)图像上的区域的像素值。只要它们用于Inter-Prediction,参考图像就不会从包含解码帧的RAM缓冲区(解码图像缓冲区,或DPB)中删除。
编码器向解码器发出关于参考图像在列表中的编号以及关于用于预测的区域相对于预测块位置的偏移信号(这种偏移被称为运动矢量)。偏移可以以1/4像素的精度确定。在进行非整数偏移的预测时,执行插值。同一图像中的不同块可以由位于不同参考图像上的区域进行预测。
在Inter Prediction的第二种选项中,预测B块像素值(双向预测块)时,使用了两个参考图像;它们的索引被放置在DPB中的两个列表(list0和list1)中。参考图像在列表中的两个索引以及确定参考区域位置的两个偏移被传输到解码器,B块像素值被计算为来自参考区域的像素值的线性组合。对于非整数偏移,使用参考图像的插值。
如前面提到的,预测编码块的值并计算残差信号之后,下一个编码步骤是谱变换。在AVC中,对残差信号进行正交变换有几种选项。当实现大小为16×16的整个宏块的Intra预测时,残差信号被分成4×4像素块;每个块都经过一个整数模拟的二维离散4×4余弦傅里叶变换。
然后,对应于每个块中零频率(DC)的结果谱分量被进一步进行正交的Walsh-Hadamard变换。对于Inter-Prediction,残差信号被分成4×4像素或8×8像素的块。然后,每个块都经过一个4×4或8×8(分别)的二维离散余弦傅里叶变换(DCT,即离散余弦变换)。
在接下来的步骤中,谱系数被进行了量化过程。这使得表示谱样本值的数字的位容量的减少,并且使得具有零值的样本数量的显著增加,这减少了表示编码图像的数字的数量和位容量。量化的负面效果是编码图像的失真,很明显,量化步长越大,压缩比就越大,但失真也越大。
AVC中编码的最后阶段是熵编码,由上下文自适应二进制算术编码的算法实现。这一阶段提供了视频数据的额外压缩,而不会在编码图像中引起失真。
十年后,HEVC标准有什么新内容?
新的H.265/HEVC标准是对嵌入在H.264/AVC中的视频数据压缩方法和算法的发展。让我们简要回顾一下主要的区别。
在HEVC中,宏块的类似物是编码单元(CU)。在每个块内,选择用于预测计算的区域-预测单元(PU)。每个CU还指定了离散正交变换计算区域的范围,这些区域称为变换单元(TU)。
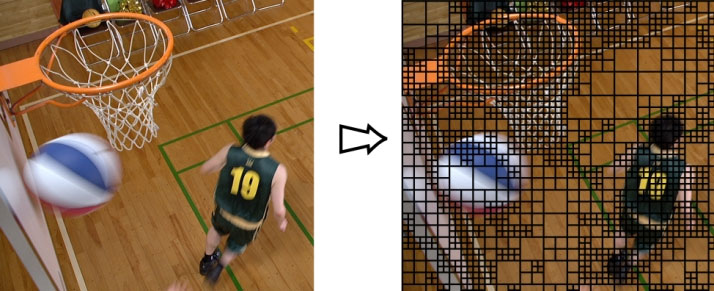
HEVC的主要区别特征在于视频帧的分割是自适应进行的,因此可以将CU边界调整到图像上的对象边界(图3)。这种适应性可以实现异常高质量的预测,从而得到低水平的残差信号。
这种自适应方法对帧分割的无疑优势还在于分区结构的极其紧凑的描述。对于整个视频序列,设置了最大和最小可能的CU尺寸(例如,64×64是最大可能的CU,8×8是最小的)。整个帧被最大可能的CU覆盖,从左到右,从上到下。
显然,对于这种覆盖,不需要传输任何信息。如果在任何CU内需要分区,则通过单个标志(分割标志)指示这一点。如果将该标志设置为1,则此CU被分成4个CU(在最大CU尺寸为64×64的情况下,分割后我们得到4个尺寸为32×32的CU)。
对于接收到的每个CU,也可以传输0或1的分割标志值。在后一种情况下,此CU再次分成4个尺寸较小的CU。此过程递归地继续,直到所有接收到的CU的分割标志等于0,或者直到达到最小可能的CU尺寸,插入的CU因此形成一个四叉树(编码树单元,CTU)。
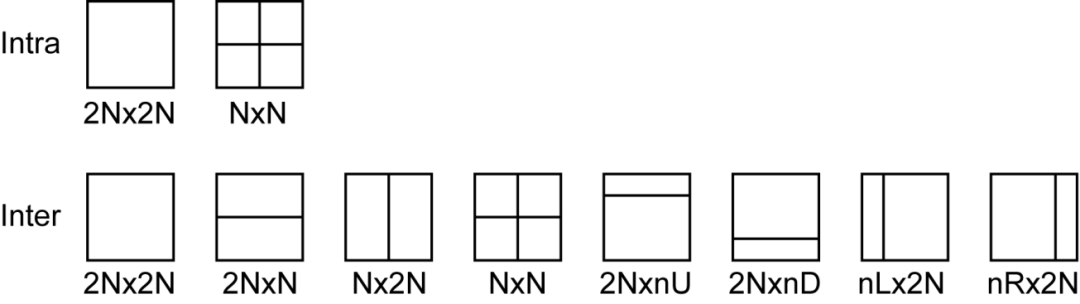
如前所述,在每个CU内,选择用于计算预测的区域-预测单元(PU)。对于Intra Prediction,CU区域可以与PU重合(2Nx2N模式),或者可以分成4个两倍较小尺寸的正方形PU(NxN模式,仅适用于最小尺寸的CU)。对于Inter Prediction,每个CU分割为PU有八种可能的选项(图3)。
在HEVC中,空间预测的概念与AVC中的相同。相邻像素值的线性组合,左侧和上方的块旁边的像素值被用作PU块中的预测样本值。然而,在HEVC中,空间预测的方法集变得更加丰富。除了平面(类似于AVC中的Plane)和DC方法外,每个PU可以通过33种“角度”预测方法之一进行预测。也就是说,“邻居”像素计算值的方式增加了4倍。
我们可以指出HEVC和AVC之间Inter-预测的两个主要区别。首先,HEVC在计算具有非整数偏移的参考图像时使用更好的插值滤波器(脉冲响应更长)。第二个区别涉及解码器执行预测所需的参考区域信息的呈现方式。在HEVC中,引入了“合并模式”,其中不同的PU与相同的参考区域偏移被合并。对于整个合并区域,关于运动的信息(运动矢量)只需在流中传输一次,这大大减少了传输的信息量。
在HEVC中,Residual信号经历的离散二维变换的大小由称为变换单元(TU)的正方形区域的大小确定。每个CU都是TU四叉树的根。因此,上一级的TU与CU重合。根TU可以分成四个一半大小的部分,每个部分又是一个TU,可以进一步分割。
离散变换的大小由较低级别的TU大小确定。在HEVC中,定义了四种变换块大小:4×4、8×8、16×16和32×32。这些变换是相应大小的离散二维傅里叶余弦变换。对于带有Intra-预测的4×4块,还可以使用另一种离散变换 – 正弦傅里叶变换。
在AVC和HEVC中,对Residual信号的谱系数进行量化和熵编码的过程几乎是相同的。
让我们指出一个之前未提到的重点。在Inter-预测解码图像放入DPB之前,经过的后滤波显著影响解码图像的质量和视频数据的压缩程度。
在AVC中,有一种滤波器 – 去块效应滤波器。应用此滤波器可以减少正交变换Residual信号的谱系数量化产生的块效应。
在HEVC中,使用了类似的去块效应滤波器。此外,还存在一种称为样本自适应偏移(SAO)的额外非线性滤波过程。基于编码期间像素值分布的分析,确定了在解码期间添加到部分CU像素值的修正偏移表。
结果是什么?
图4-7显示了两个编码器对几个高清(HD)视频序列进行编码的结果。其中一个编码器使用H.265/HEVC标准对视频数据进行压缩(在所有图表中标记为HM),而另一个编码器使用H.264/AVC标准。

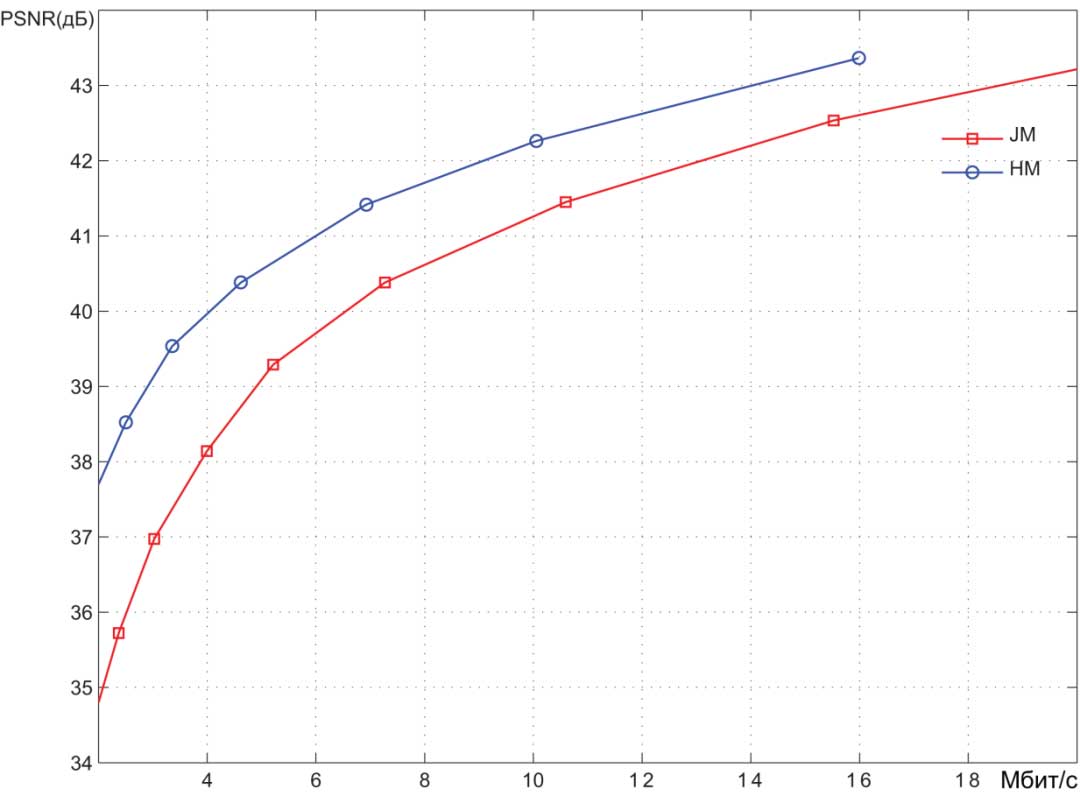

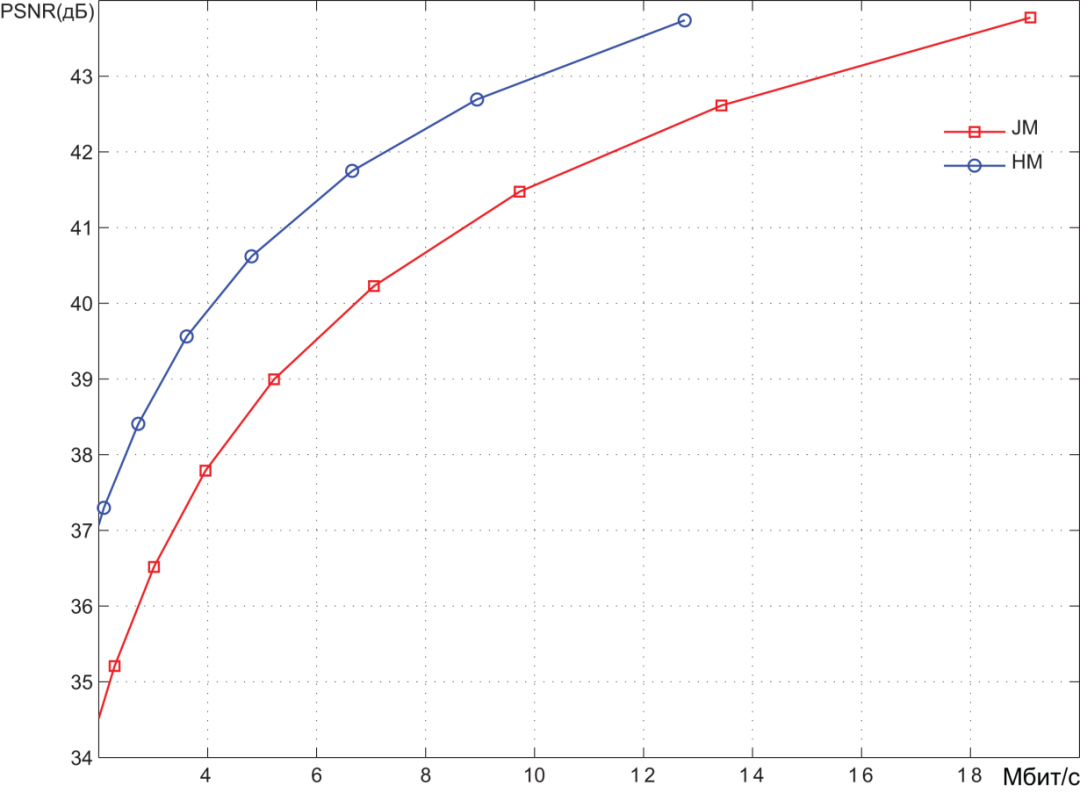
编码是在不同的频谱系数量化值下进行的,因此产生了不同程度的视频图像失真。结果以比特率(Mbps)- 峰值信噪比(PSNR)曲线呈现。PSNR值表征了失真程度。
一般来说,可以认为低于36 dB的PSNR范围对应高度失真,即低质量视频图像。36到40 dB的范围对应平均质量。而40 dB以上的PSNR值可以称为高质量视频。
我们可以粗略估计编码系统提供的压缩比。在中等质量区域,HEVC编码器的比特率比AVC编码器少1.5倍。未压缩视频流的比特率可以确定为每个视频帧的像素数(1920 x 1080)乘以表示每个像素所需的位数(8 + 2 + 2 = 12),再乘以每秒的帧数(30)。
因此,我们得到约750 Mbps。从图表中可以看出,在平均质量区域,AVC编码器提供约10-12 Mbit/s的比特率。因此,视频信息的压缩程度约为60-75倍。正如前面提到的,HEVC编码器提供的压缩比高出1.5倍。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。