
对于沉浸式体验,生成多通道扬声器驱动信号的空间音频渲染对于提升真实感而言非常重要。例如,一个声音信号可以通过电子处理来产生一个虚拟的点源,并呈现为从听者的右边或左边的给定位置发出,而不是从正前方或各个方向均匀地发出。这种声音是由驱动多声道扬声器设置的空间音频渲染算法产生。
在名为“Splitting a voice signal into multiple point sources”的专利申请中,苹果就介绍了一种相关的方法。
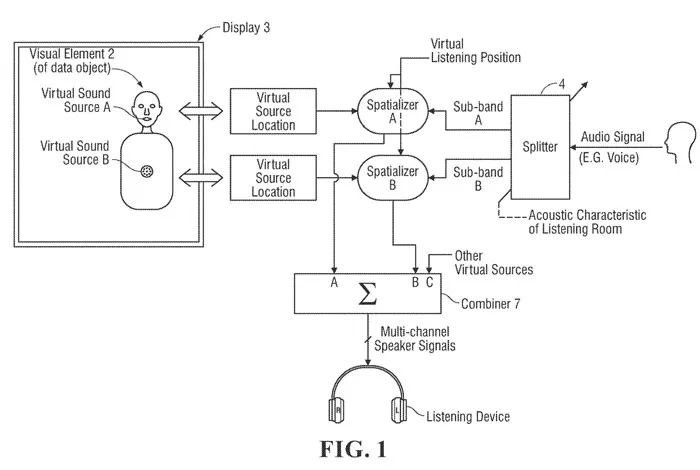

图1是音频系统的框图,所述音频系统将与数据对象的视觉元素相关联的输入音频信号分割为至少两个虚拟声源,并分别对每个声源进行空间化。相关方法操作由系统的数据处理器执行,并用于对数据对象的声音进行空间化。数据处理器可以由软件配置,例如模拟现实XR应用。
输入音频信号由视觉元素表示的数据对象的声音相关联或表示,例如在XR应用程序中。数据对象的可视元素在由视频引擎渲染后出现在显示器。可视元素可以是数据对象的图形对象区域,或者可以是图形对象体积。
所述数据对象可以是例如人,并且所述视觉元素是所述人的Avatar,其在图1中描述为具有头部和躯干。音频信号表示数据对象的声音,在人的示例中是人的声音。
音频系统将单个输入音频信号呈现为两个或多个虚拟声源或点源。分频器将所述音频信号分成两个或多个子频带音频信号,包括第一子频带(子频带A)和第二子频带(子频带B)。分频器可以作为滤波器组来实现。子频带A在人可听范围内的频率范围可能高于子频带B。例如,低频(子频带B)可能在50hz – 200hz之间。例如,低频段为100hz ~ 300hz。
将子频段A分配给视觉元素中的第一位置,而将第二子频段分配给视觉元素中的第二位置。如图所示,子频段A空间化为虚拟声源A或位于头部或嘴巴的点源,而子频段B空间化为躯干的虚拟声源B。
所述系统通过处理所述两个子频带音频信号及其相关的元数据,产生一组多声道扬声器驱动信号,并且驱动听音设备产生所述数据对象的声音,从而使得子频带A的声音从与子频带B的声音不同的位置发出。
在图1的示例中,子频带A、B分别空间化,由两个空间化模块A、B来描述,这两个空间化模块A、B作为输入接收相同的虚拟接听位置但不同的虚拟源位置和不同的音频信号。
图1同时说明了分频器由房间的声学特性控制。这个房间可以是一个虚拟的房间,其中数据对象呈现在显示器。或者,所述房间可以是一个真实的房间。在这种情况下,设备可能是听者佩戴的耳机,听者可以通过光学头戴式显示器看到真实的房间,而数据对象的视觉元素则呈现在显示器中。
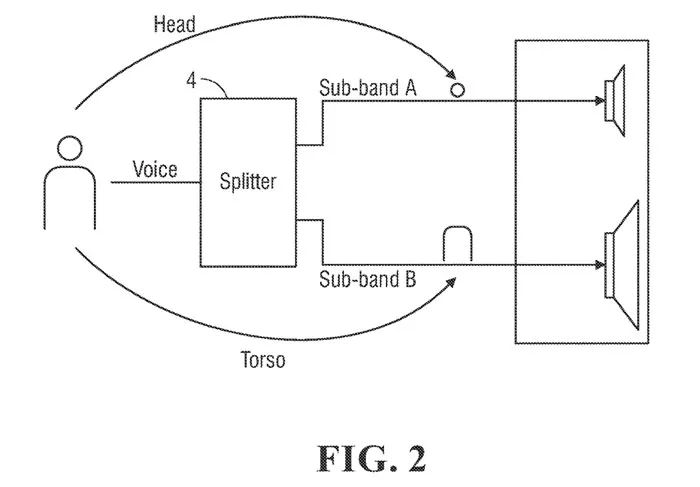
图2是一个示例计算机系统的框图。语音信号是一种音频信号,其内容主要或主要是人的讲话,例如。因此,语音信号不包含音乐或效果。
如图1所示,数据处理器配置为充当分频器,其将语音信号分为至少两个component,即第一子频带A中的第一子频带信号和第二子频带B中的第二子频带带信号,然后生成多个扬声器驱动信号。
这在本例中为高音喇叭信号和一个低音信号。高音和低音形成一个双向扬声器系统。因此,图2中的处理器不是作为将两个子频带分别空间化的空间化模块,而是使第一子频带A中的声音从设备的高音发出,并且使第二子频带B中的声音从低音发出。第一子频带A为高频段,第二子频带B为低频段。
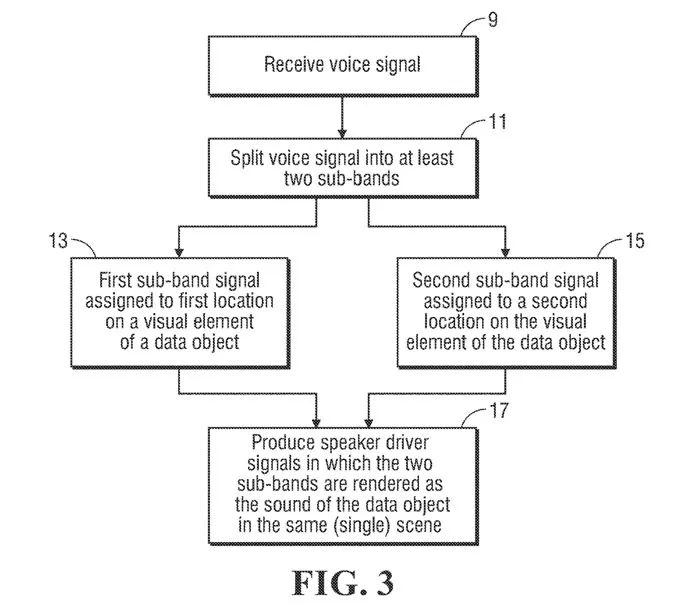
在图3中的流程图中,通过将语音信号分割成用于单独点源的至少两个子频带来再现数据对象的语音,而所述方法可由数据处理器执行。
在一个实施例中,所述方法首先接收数据对象的语音信号(操作9),并将语音信号分割为第一子频带中的第一子频带信号和第二子频带中的第二子频带信号(操作11)。
在一方面,处理器同时将第一子频带信号分配给数据对象的视觉元素的第一位置(操作13),并将第二子频带信号分配给视觉元素的第二位置(操作15)。
它生成多个扬声器驱动信号,以在单个场景中再现数据对象的声音(操作17)。在一个实施例中,空间化处理产生扬声器驱动信号,使得第一子频带信号的声音从第一虚拟位置发出,第二子频带信号的声音从不同于第一位置的第二虚拟位置发出。
在另一实施例中,不将数据对象的声音空间化,第一子频带信号的声音由高频扬声器驱动器产生,而第二子频带信号的声音由低频扬声器驱动器。
在另一方面,将音频处理效果添加到正在对子频带A音频信号执行的信号处理链中。在图1中,所述处理效果可能是空间话模块A的一部分。当听者在声源周围移动时,这一添加将影响声音的均衡性,
例如,当听者在角色说话时在角色后面或在角色前面时。在高频波段处理中加入频率相关的指向性效应可以令特定音素的呈现更加真实。通过将增益相关的指向性添加到高频波段处理中,可以更真实地呈现不同级别的语音产生。
名为“Splitting a voice signal into multiple point sources”的苹果专利申请最初在 提交,并在日前由美国专利商标局公布。
—
原文链接:https://news.nweon.com/110838
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。