
本工作提出了一种基于扩散的3D-aware生成式新视角合成模型,即使只有一张输入图像,本模型也能够从可能的渲染分布中采样,生成与输入一致的多样化且真实的新视角。本方法利用现有的2D扩散网络,将几何先验以3D特征volume的形式融入其中。除了生成新视角,本方法还能够自回归地合成3D一致的视频序列。
来源:Arxiv
项目链接:https://arxiv.org/abs/2304.02602
作者:Eric R. Chan et al.
内容整理:陈梓煜
介绍


本工作旨在解决小样本新视角合成任务(Novel View Synthesis,NVS)中的多个开放问题:设计一个NVS框架能(1)以单张图像作为输入,(2)能够生成远离输入视角的新视角序列,(3)并且能够处理单个对象和复杂场景(见图1)。尽管现有的稀疏新视角合成方法,通过训练具有回归目标的对象类别,能够生成几何一致的渲染,即序列的帧共享一致的场景结构,但它们在处理新视角和无界场景时效果不佳(见图2)。处理长新视角序列需要使用生成式先验来处理在输入中未观察到的场景部分所固有的不确定性。在本工作中,我们提出了一种基于扩散的少样本NVS框架,可以生成合理且在几何上一致的渲染,将NVS的边界推向可以在广泛的挑战性现实世界数据中运行的解决方案。
之前的少样本新视角合成方法可以大致分为两类。基于几何先验的方法借鉴了场景表示和神经渲染的相关工作。尽管它们在生成输入视角的附近新视角取得了不错的结果,但大多数方法仅通过回归目标进行训练,在处理不确定性或较长程的新视角合成时效果不佳。当面临从稀疏输入进行新视角合成的任务时,它们只能处理轻度模糊的情况,即新渲染的条件分布在估计该分布的均值估计时近似为该分布的均值,通过最小化像素均方差L1或L2损失得到。然而,在高度模糊的情况下,例如当场景的某些部分在所有给定的视角中都被遮挡时,基于回归的方法仅限于对以对象为中心的场景进行短程视角插值,而在非约束场景的长程新视角合成方面遇到困难。

相比之下,生成方法依赖于生成先验,并通过从这个条件分布中生成随机合理样本来解决新视角合成问题。现有的用于视角合成的生成模型通过少量或没有几何先验来自回归地新视角合成一个或多个输入图像。因此,这些方法中的大部分在生成几何一致序列时遇到困难,渲染在帧之间仅近似一致,并缺乏一致的刚性场景结构。在本工作中,我们提出了一种NVS方法,它填补了几何和生成视角合成方法之间的差距,用于生成既具有几何一致性又具有生成性质的渲染。
我们的方法借鉴了扩散模型的最新进展。具体来说,条件扩散模型可以直接应用于NVS任务。在输入图像的条件下,这些模型可以从输出渲染的条件分布中进行采样。作为生成模型,它们自然地处理不确定性,并适用于持续的合理新视角合成。然而,仅凭图像扩散框架很难合成3D一致的视角。
在处理复杂场景时,几何先验仍然很有价值,而像素对齐的特征 已经被证明对于将场景表示是成功的。我们将这些思想与我们的基于扩散的NVS模型的架构相结合,加入了一个3D特征场和神经特征渲染。与先前包含神经场的视角合成工作不同,我们的特征场捕获了场景表示的分布,而不是特定场景的表示。通过扩散采样在推理过程中,这个潜在场景的渲染被提炼成一个特定场景实现的渲染。这种新颖的形式既可以处理长程新视角合成引起的不确定性,又可以生成几何一致的序列。
总之,我们的工作的贡献包括:
- 我们提出了一种新的视角合成方法,将2D扩散模型扩展为3D-aware,通过对来自输入图像的3D神经特征进行条件化。
- 我们的3D特征条件扩散模型可以在多个数据集上生成真实的新视角,只需一个单独的输入图像,包括单物体级别、房间级别和复杂的真实世界数据。
- 我们展示了通过我们提出的方法和采样策略,我们的方法可以生成逼真的、多视角一致的长序列新视角。
方法
我们在这里描述了我们的NVS(novel view synthesis,新视角合成)模型的整体结构,包括单视角和多视角条件下的情况,以及我们的训练和推理方法。
在新视角合成中,我们给定一组输入图像 xinputs 和相机参数 Pinputs,这些参数与姿态和内参有关,我们的任务是在给定一组查询相机参数的情况下,为查询视角生成预测。我们的目标是从相应的条件分布中采样新视角:
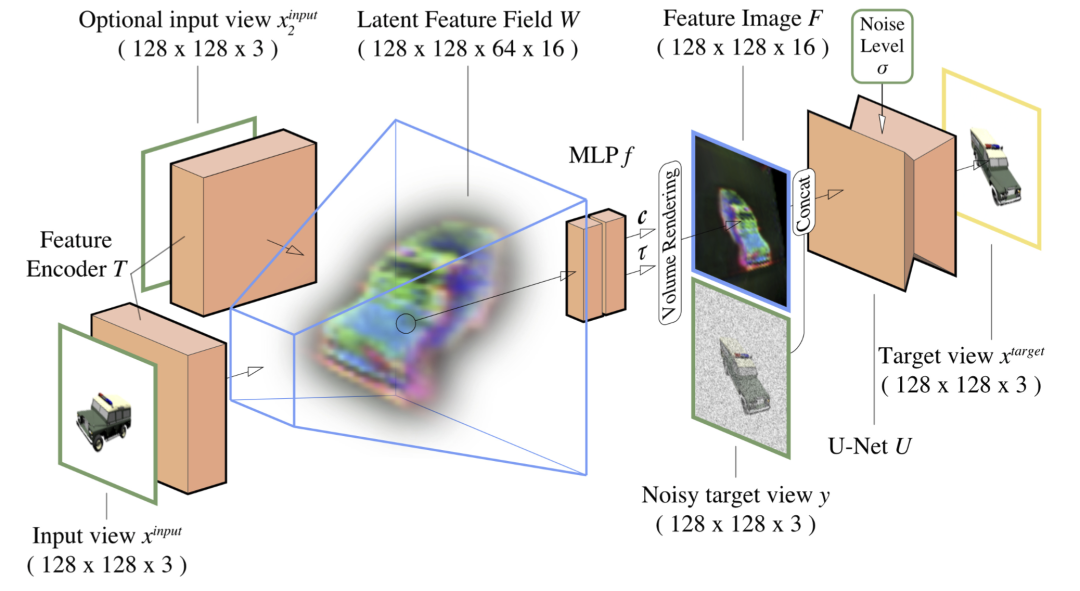
3D-Aware扩散模型架构

在本工作中,我们直接重用2D扩散模型来建模分布。这一想法是,生成新视角合成与任何其他条件图像生成任务相同,我们只需要将2D图像扩散模型以输入图像和相对相机姿态为条件进行条件化。然而,尽管有许多方法可以应用这种条件化,但其中一些可能比其他方法更有效。通过将几何先验纳入到3D特征场和神经渲染中,我们为我们的架构提供了强烈的几何一致性归纳偏差。
图3总结了我们的基于条件去噪器的流程 D 的设计,该流程接收一个带噪声的目标视角 y,条件信息 (xinputs , Pinputs,Ptarget) 和噪声 σ。我们的策略基于像素对齐的隐式函数和神经渲染。根据图3,给定一个从输入视角相机 P 拍摄的单个输入图像 x,我们使用图像到图像特征提取网络 T 来预测具有 c x d 个通道的特征图,并将其重新塑造为覆盖源相机视锥体的特征体积 W。
这里 d 对应于体积的深度维度,c 对应于体积中每个单元格中的通道数(通常,c = 16 和 d = 64)。给定查询相机 Ptarget,我们在三维空间中投射射线。继续图3,对于射线上的任何点 r,我们用三线性插值对体积 W 进行采样,并使用小型多层感知器(MLP)f 对获取的特征 w = W(r) 进行解码,以获得密度 τ 和特征向量 c 。
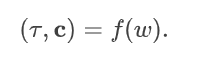
通过使用体积渲染将这个特征场投影到目标视角中,我们得到图3中的特征图 F:
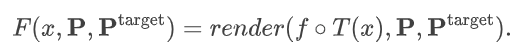

整合多视角信息
多视角输入信息的附加信息能够减少不确定性,并使得我们的模型能够从更窄的分布中采样渲染结果。当有多个条件视角可用时,我们将每个输入图像单独处理为一个单独的特征体积。
如果推广到 n 个条件视角,通过对每个输入图像 xj 获得的特征:
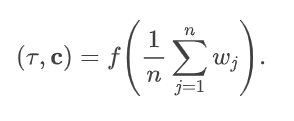
为了在推理期间利用此策略,我们通过多个(可变数量的)输入图像来训练我们的模型。在查询时,使用多个条件视角可以确保平滑的、循环一致的视频合成。尽管仅在前一帧上进行条件化对于小视角变化的视图一致性是足够的,但这并不能保证闭环一致性。在实践中,我们发现在以前生成的一部分视图上进行条件化有助于确保正确的闭环一致性,同时保持合理的视图之间一致性。
训练
在训练的每个迭代中,我们随机采样一个批次的目标图像、输入图像和它们的相机姿态,其中目标和输入必须来自同一场景。我们的模型从头开始进行端到端训练,以最小化以下目标:
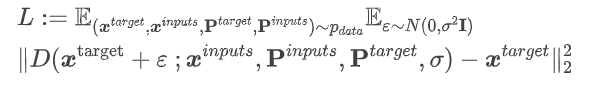
其中σ在训练过程中根据EDM的策略进行采样。在每次迭代时,对于一个查询,条件视角的数量从集合{1, 2, 3}中均匀地抽取。在训练期间,我们对U应用非泄露增强,并对输入图像进行少量随机噪声增强。
推理中的生成新视角
使用我们的方法生成图像与使用条件性扩散模型生成图像是相同的。具体的图像更新规则取决于采样器的选择。在我们的实验中,我们使用确定性的二阶采样策略,每次进行25次或更少次数的去噪步骤。
为了提高推理效率,我们对Γ和U进行解耦。在采样循环的每一步中,不需要同时运行Γ和U。我们先预处理地渲染特征图F,并在采样循环的每次迭代中重复使用它——虽然U在推理过程中的每一步都必须运行,但 Γ 只需运行一次。
自回归生成
为了生成一致的序列,我们采用了自回归方法来合成顺序帧。我们不是仅在输入图像的条件下独立地生成每一帧,从而导致帧间差异较大,而是在输入以及先前生成的一部分帧的条件下生成每一帧。虽然在长自回归序列中可能会出现错误和伪影,但在实践中我们发现我们的模型有效地抑制了这些错误,使其适用于扩展序列生成。
实验
Baselines
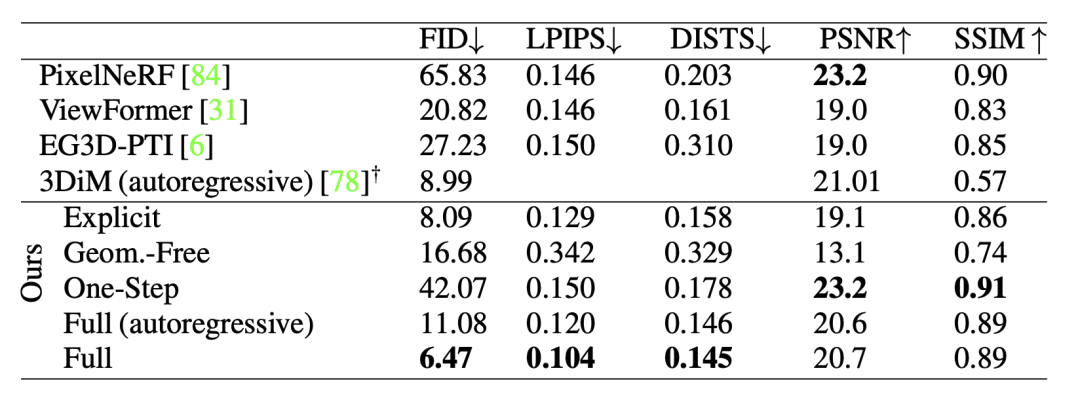
我们将我们的方法与PixelNeRF进行了比较,PixelNeRF是一种用于NVS的基于NeRF的现有技术,以及ViewFormer,一种基于transformer的无几何信息方法。对于ShapeNet,我们还与EG3D-PTI进行了比较,该方法基于用于对象尺度场景的最先进的3D GAN,并与3DiM进行了数值比较,3DiM是一种用于NVS的最新的无几何信息扩散方法。
评价指标
我们从三个维度评估新视角合成的任务能力 (1)重新创建地面真实数据集的图像质量和多样性 (2)生成与地面真实数据一致的新视角 (3)生成几何一致的序列。对于(1),我们使用分布比较指标FID和KID,这些指标通常用于评估图像合成的生成模型。对于(2),我们使用感知度量LPIPS和DISTS,这些指标衡量合成的新视角与地面真实新视角之间的结构和纹理相似性。对于(3),我们提供了生成视频序列的COLMAP重建,这是评估3D GANs几何一致性的标准方法。密集、明确定义的点云是几何一致帧的指示。我们计算地面真实图像重建和生成序列重建之间的Chamfer距离,以定量评估几何一致性。
ShapeNet
在ShapeNet数据集上,我们的方法在单视角新视角合成任务上表现优越。相比于传统的回归方法,我们的生成模型能够生成更锐利、多样化的图像,与真实图像更接近。

在多项指标上,我们的方法在结构和纹理相似性方面优于基线方法。同时,我们的方法结合了自回归生成的技术,能够实现高度的几何一致性。总的来说,我们的方法在ShapeNet数据集上取得了显著的性能改进。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。