
随着大型语言模型(LLM)开始承担越来越复杂的任务,它们的输入包含更长的上下文来解决需要领域知识或特定于用户的对话历史的问题。然而,使用长上下文对响应式LLM系统提出了挑战,因为在所有上下文都被获取到LLM并由LLM处理之前,不会生成任何内容。现有系统仅优化上下文处理中的计算延迟(例如,通过缓存文本上下文的中间键值特征),但通常会在上下文获取中导致更长的网络延迟(例如,键值特征消耗比文本大几个数量级的带宽)。本文作者提出了CacheGen,以最大程度地减少LLM获取和处理上下文的延迟。CacheGen通过新颖的编码器将KV特征压缩为更紧凑的比特流表示,减少了传输长上下文的键值(KV)特征所需的带宽。该编码器利用KV特征的分布特性,例如跨Token的局部性,将自适应量化与定制的算术编码器相结合。此外,CacheGen通过使用控制器确定何时将上下文加载为压缩KV特征或原始文本,并在加载为KV特征时选择适当的压缩级别,从而最大限度地减少获取和处理上下文的总延迟。作者在三个不同大小的模型和三个不同上下文长度的数据集上测试CacheGen。与近期处理长上下文的方法相比,CacheGen将带宽使用量减少了3.7-4.3倍,将获取和处理上下文的总延迟减少了2.7-3倍,同时在各种任务上保持与加载文本上下文类似的LLM性能。
题目:CacheGen:Fast Context Loading for Language Model Applications
作者:Yuhan Liu, Hanchen Li, Kuntai Du, Jiayi Yao, Yihua Cheng, Yuyang Huang, Shan Lu
文章地址:https://doi.org/10.48550/arXiv.2310.07240
内容整理:张俸玺
引言
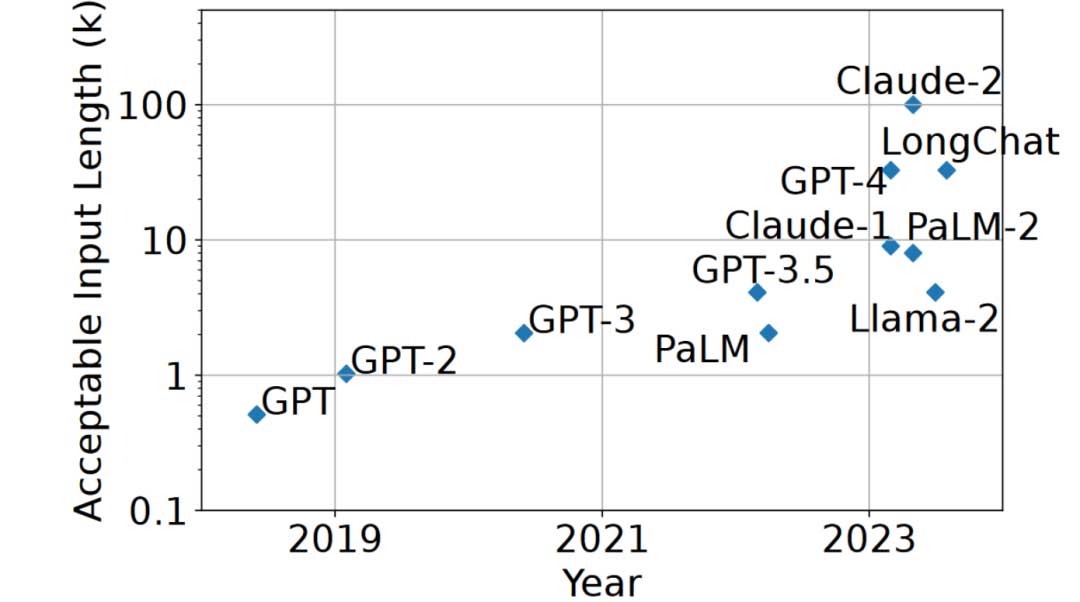
凭借其令人印象深刻的生成能力,大语言模型(LLM)被广泛应用于各个领域。公共LLM的API(例如GPT-4)和应用框架(例如Langchain)的广泛使用,结合开源的满足工业应用质量要求的LLM(例如Llama),进一步提高了LLM的受欢迎程度。随着LLM越来越多地被用于复杂任务,许多应用程序通过使用包含至少数千个标记的长上下文LLM来增强它们的输入(即提示)。例如,某些上下文用领域知识文本补充用户提示,以便LLM可以使用LLM本身嵌入的信息之外的领域知识来生成响应。另一个例子是,一些上下文利用用户和LLM之间交互过程中积累的对话历史来补充用户提示。这种长上下文的趋势很好地反映在最近训练接受更长上下文输入的LLM的竞赛中,从ChatGPT中的2K Tokens到Claude中的100K(见图1)。虽然较短上下文输入能力的LLM仍然有用,但许多研究表明,较长的上下文输入通常有助于提高模型响应的质量和一致性。

尽管提高了模型的响应生成质量,但使用长上下文对响应生成延迟提出了挑战,因为模型在加载和处理所有上下文之前无法生成响应。为了解决这一延迟挑战,之前的工作通过缓存中间处理结果:键值(KV)特征来减少上下文处理的计算延迟。这样,LLM系统可以直接使用KV特征并跳过冗余计算,而不是在文本上下文上重复自注意力计算,其复杂度与文本长度呈超线性。然而,之前的工作实质上是以增加通信延迟为代价减少了计算延迟,因为KV特征是浮点数的多维张量,并且可能比其相应的文本上下文大几个数量级。
加载KV特征的成本尤其令人担忧,因为在实践中,它们通常需要从另一台机器远程获取。例如,上下文文档的数据库可能驻留在单独的服务器中,而辅助LLM推理的补充文档只需在收到相关查询时选择并获取到LLM。类似地,由于用户的提示可能会在空间(例如,来自不同位置)和时间(例如,两个查询可能相隔几天)中传播,因此它们可以由不同的机器处理,因此对话历史记录(即上下文)必须即时加载到服务当前请求的GPU上。在KV特征加载到GPU内存后,一些紧急机制会缩短上下文,例如删除张量。然而,丢失的张量信息不可避免地会损害LLM的响应质量,并且由此产生的大张量形式的KV特征仍然需要高带宽来传输。因此,仅仅优化计算延迟不足以生成长上下文响应,甚至可能降低端到端性能,因为加载KV特征会增加网络延迟。相反,LLM系统不仅必须优化计算延迟,还必须优化处理长上下文时的通信(网络)延迟。
本文介绍了CacheGen,这是一种用于LLM系统的快速上下文加载模块,旨在(1)减少传输上下文的KV特征所需的带宽,以及(2)最大限度地减少获取和处理上下文的总延迟,而不是单独地减少每个延迟。
CacheGen使用新的KV编码器将这些特征张量压缩(而不是丢弃或重写)为更紧凑的比特流,从而减少了传输长上下文的 KV 特征所需的带宽。本文提出的KV编码器的设计利用了跨Token和层的KV特征的独特属性,以实现高度的尺寸减小和很少的信息丢失。凭借其KV编码器,CacheGen可以灵活地以不同形式传输上下文,包括多个比特流表示形式的KV特征(每个比特流表示形式具有不同的压缩率)和原始文本,这会产生更多的LLM处理成本,但不会产生解压缩成本或信息丢失。在传输上下文之前,CacheGen使用控制器来决定使用哪种形式,灵活地在LLM生成质量、传输带宽和解压缩成本之间进行权衡。它选择能够优化传输和解压缩的组合成本的上下文形式,或者适合给定时间预算且信息损失最少的形式。
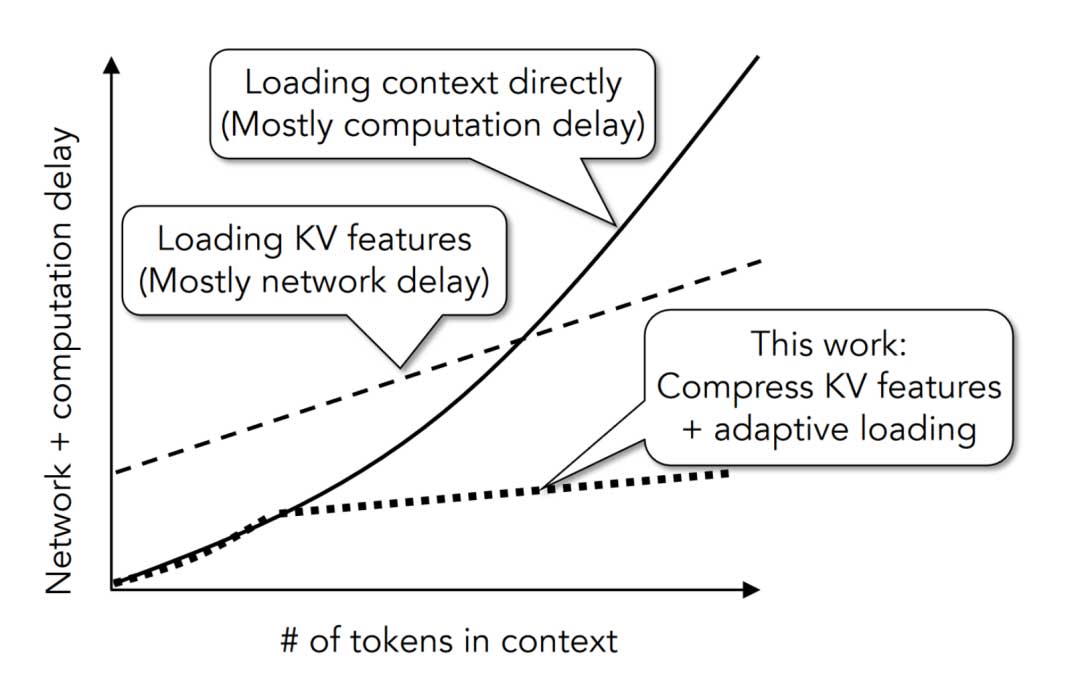
图2说明了CacheGen的优势。通过将KV特征压缩为更紧凑的比特流,CacheGen显著降低了长上下文中KV特征传输的带宽使用量,从而优于直接获取KV特征的基线以及在没有KV缓存的情况下加载文本上下文的基线。对于较短的上下文,CacheGen直接自动选择加载文本上下文,而不是其KV特征。
加载上下文的隐藏网络延迟
当前的LLM系统通常假设KV缓存已经存储在GPU内存中(或在同一台机器上),因此它们专注于减少计算延迟。但实际上,KV 缓存并不总是位于运行LLM推理的GPU的内存中。相反,LLM输入的上下文通常需要从另一台机器远程获取。
在基于检索的应用程序中,上下文文档可以托管在与LLM不同的服务器上。原因之一是上下文文档可能太大(即使是原始文本),无法本地存储在运行LLM推理的GPU服务器上。此外,出于特殊的考虑,后台数据库可能由与LLM服务不同的服务器管理。在聊天应用程序中,用户可以在上次交互后几天后恢复与LLM的对话。在这些情况下,她的对话历史记录的KV缓存可能需要从GPU内存中换出,以便为其他活动对话会话节省空间。此外,用户可以从不同地点、不同时间向LLM发出提示。由于这些提示可以由不同的机器处理,因此必须远程获取上下文。
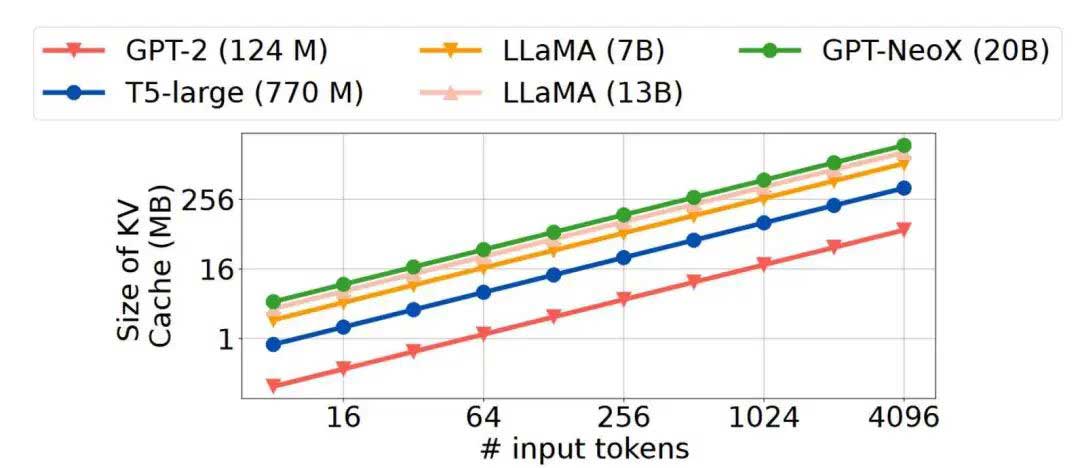
由于KV特征需要按需获取到运行LLM推理的GPU中,因此传输它们的延迟必须添加到加载和处理上下文的端到端延迟中。然而,上下文的KV缓存的大小可能比上下文本身大几个数量级,这使得网络带宽成为潜在的瓶颈。客观地说,对于5K个token的上下文,以int-8表示形式存储每个token需要5KB。相比之下,Llama-7B模型产生的KV特征是两个张量,每个张量的大小为5K(Token)×4096(通道)×32(层),并且torch.save序列化的KV特征的大小为1.3 GB。以1Gbps的网络带宽为例,KV特性在网络带宽上的传输延迟需要10秒以上。相比之下,在英伟达A40 GPU上,通过转换器处理文本上下文只需 5 秒。简而言之,远程获取大型KV特征的需求抵消了KV缓存在节省计算延迟方面的优势。这一网络瓶颈不仅仅影响一种模型。如图3所示,当前流行的LLM的KV特征大小都随着输入token的长度的增加而增长。
CacheGen设计
CacheGen是一个用于LLM推理系统的快速上下文加载模块。CacheGen最大限度地减少了加载和处理给定上下文的总体延迟,同时保留了LLM的性能。
具体来说,作者将总体延迟定义为获取输入(提示和上下文)与生成(解码)第一个Token之间的时间。作者将其称为首次Token时间 (TTFT),因为它测量用户何时可以使用第一个Token。正如之前的研究所示,用户体验可能会受到TTFT的极大影响,因为它展示了应用程序的响应能力。重要的是,TTFT既包括远程获取上下文或其KV特征的网络延迟,也包括处理上下文或其KV特征的计算延迟以及解码第一个Token之前的提示。为了关注长上下文的影响,TTFT排除了两个延迟。首先,TTFT排除了逐一解码生成标记的时间。它随着响应长度的增加而增加,因此作者选择排除它,以便更好地专注于加快输入中上下文的加载和处理。其次,TTFT排除了基于提示选择相关文档的延迟。原因有二:(1)这个过程是由另一个独立的DNN或其他算法处理的,而不是LLM本身。因此这不是这一研究讨论的重点。(2)这种延迟最近已经通过基于检索的途径进行了优化,并且与TTFT相比效果相对较小。
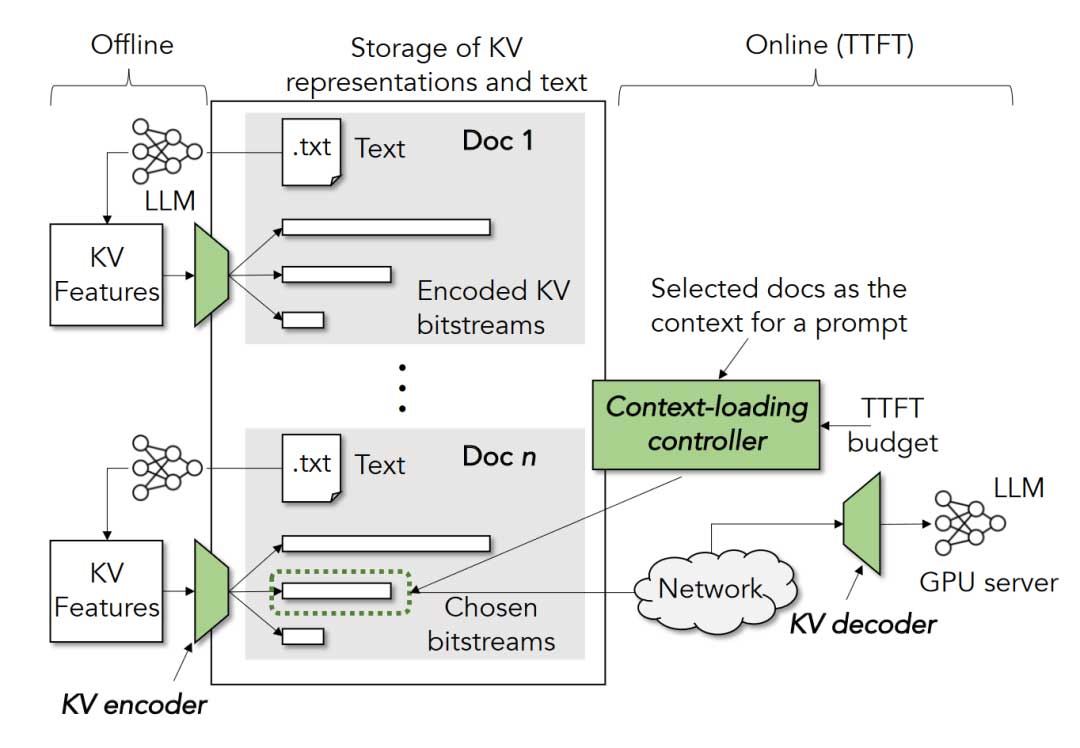
为了平衡给定上下文中的总体延迟和LLM性能,CacheGen采用了KV编码器/解码器和加载控制器,如图4所示。
给定上下文的缓存KV特征,CacheGen的KV编码器首先将KV特征压缩为比特流表示。
虽然最近的一些方案提出缩短上下文或其KV特征,但它们是通过丢弃Token来实现的,这不可避免地导致信息丢失。此外,由于缩短的KV特征在GPU内存中仍然以大张量的形式存在并直接被LLM消耗,因此它们首先仍然需要高带宽来加载。相比之下,本文提出的编码器旨在压缩KV特征,压缩后的特征是比特流,在被LLM使用之前将被解压缩。该比特流不再采用KV张量的形式,可以采用更紧凑的表示形式,同时信息损失最小。
为了灵活地权衡TTFT和生成性能之间的关系,CacheGen在用户查询到达之前提前以不同的压缩级别和多种比特流表示形式压缩上下文的KV缓存。通过新的提示和选定的上下文,CacheGen的加载控制器根据TTFT预算选择上下文的压缩级别,通过网络获取和解压缩它,并将其提供给LLM。值得注意的是,根据上下文的长度,当加载和解压缩KV特征的估计时间长于直接加载和处理文本的时间时,控制器可能会选择加载上下文的原始文本。当上下文相对较短或获取上下文的可用带宽相对较低时,通常会发生这种情况。
从CacheGen的设计角度来看,它的每个组件(自适应压缩和KV缓存)可能之前已经被研究过。尽管如此,CacheGen中这些组件的精确设计包含了有关KV特征的特定领域见解,并集成到一个端到端系统中,该系统首次明确最小化了LLM的网络和上下文相关的计算延迟。
实验

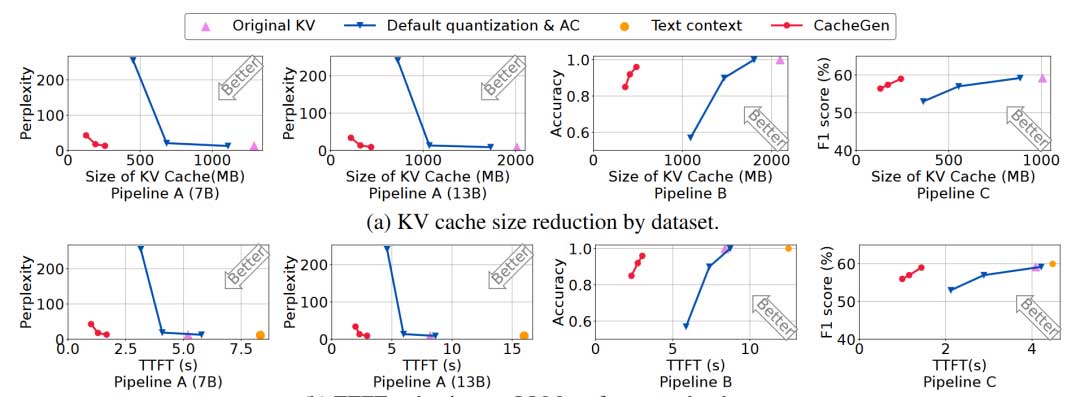
作者在三个不同容量的模型和使用不同长度上下文的不同任务的三个数据集上评估了CacheGen,如表1所示。与不考虑KV分布特性的基线量化和算术编码方案相比,CacheGen可以节省3.7-4.3倍传输KV特征的带宽占用,以及2.7-3倍传输和处理KV特征的延迟。在各种任务上保持更高的LLM性能表现,通过任务特定的指标(例如困惑度和准确性)来衡量。与加载文本上下文的基线相比,CacheGen将处理KV特征的延迟减少了2.8-4.5倍,F1分数下降了不到1%,困惑度分数增加了0.5。此外,在相似的任务性能下,与修改上下文或重新训练模型以缩短上下文的更复杂的基线相比,CacheGen还具有更低的总获取、处理延迟和更高的LLM表现性能。
结论
作者提出了CacheGen,这是一个上下文加载模块,可以最大限度地减少LLM获取和处理上下文的总体延迟。CacheGen通过专门用于将KV特征压缩为紧凑比特流的编码器,减少了传输长上下文的KV缓存所需的带宽。对不同容量的三个模型和具有不同上下文长度的三个数据集的实验表明,CacheGen可以在保持高任务性能的同时减少总体延迟。
局限性
由于GPU内存的限制,作者没有在OPT-175B等超大型模型上评估这一方法。作者也没有广泛评估CacheGen在“自由文本生成”方面的性能。作者的评估使用简单的传输延迟网络模型,该模型在高带宽变化下不起作用。最后,并不是所有的应用程序都能自然地缓存KV特征。基于搜索的应用程序(例如Google和Bing)使用实时搜索结果作为上下文,除非非常受欢迎的搜索结果,否则它们的不稳定上下文不太可能被重用。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。