
为了实现变形精度和拓扑灵活性,本文提出了一种生成纹理光栅化三平面的3D表示。所提出的表示在参数网格模板上学习生成神经纹理,然后通过光栅化将它们投影到三个正交的视图特征平面中,形成用于体绘制的三平面特征表示。这种方式结合了网格引导的显式变形的细粒度表达控制和隐式体积表示的灵活性,进一步提出了 3DMM 没有考虑的用于口腔内部建模的特定模块。作为 3D 先验,Next3D 的可动画化 3D 表示增强了多种应用程序,包括一次性面部化身和3D感知风格化。
文章来源:CVPR 2023
文章题目:Next3D: Generative Neural Texture Rasterization for 3D-Aware Head Avatars
项目链接:https://github.com/MrTornado24/Next3D
作者:Jingxiang Sun,Xuan Wang,Lizhen Wang,Xiaoyu Li等
内容整理:王睿妍
引入
动画肖像合成对于电影后期制作、视觉效果、增强现实 (AR) 和虚拟现实 (VR) 远程呈现应用程序至关重要。高效的可动画肖像生成器需要能在细粒度级别上全面控制刚性头部姿势、面部表情和凝视方向来合成不同的高保真肖像。该任务的主要挑战在于如何在生成设置中通过动画建模准确的变形并保留身份,即仅使用 2D 图像的非结构化语料库进行训练。
贡献
Next3D 提出了一种新的 3D GAN 框架,用于从非结构化 2D 图像中无监督学习生成、高质量和 3D 一致的面部化身。
- 提出了一个可动画的 3D 感知 GAN 框架,用于具有细粒度动画的逼真肖像合成,包括表情、眨眼、注视方向和全头部姿势。
- 提出了生成纹理光栅化三平面,这是一种高效的可变形 3D 表示。据我们所知,我们是第一个将神经纹理合并到可动画的 3D 感知合成中的方法。
- 学习的生成动画 3D 表示可以作为强大的 3D 先验,并促进 3D 感知的一次性面部化身的下游应用。
具体实现
Next3D 将整个头部分为动态部分和静态部分,并分别对它们进行建模。对于动态部分,结合网格引导显式变形的细粒度表达式控制和隐式提出了一种新的表示,即生成式纹理栅格化三平面,它通过参数模板网格顶部的生成神经纹理来学习面部变形,并通过标准栅格化将它们采样为三个正交视图和轴对齐的特征平面,形成三平面特征表示。这种纹理栅格化的三平面在体积表示中重新形成高维动态表面特征,以实现高效的体绘制,继承了网格驱动变形的精确控制和体积表示的表达能力。此外,通过另一个三平面分支表示静态部分(身体、头发、背景等),并通过 alpha 混合集成两者。
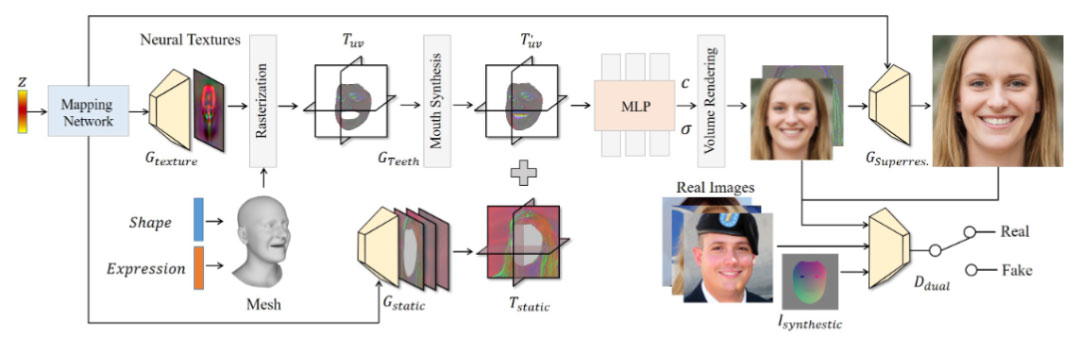

上图是 Next3D 的整体框架图,3D GAN 框架由两个三平面分支 Tuv 和 Tstatic 组成,用于建模动态和静态部分。Tuv 是由 StyleGAN 生成器 Gtexture 合成的正交栅格化生成神经纹理形成的,嘴部合成模块 Gteeth 用于完成嘴部内部细节的生成。混合三平面与由体绘制和超分辨率模块 Gsuperres 组成的混合神经渲染器相结合。对于判别器部分,合成的渲染视图 Isynthetic 被引入双判别器 Ddual。
生成纹理栅格化三平面
EG3D 缺乏对面部变形的控制,因此不能直接应用于动画任务。Next3D 利用神经纹理来表示可变形的面部部分。一般来说,神经纹理是一组学习的高维特征图,可以由神经渲染器解释。Next3D 将其扩展到生成设置,并通过 StyleGAN2 CNN 生成器 Gtexture 合成神经纹理。首先对潜在代码 z 进行采样,并通过映射网络将其映射到中间潜在空间。纹理生成器架构紧跟 StyleGAN2 主干,生成 256 × 256 × 32 的神经纹理映射 T。在给定预先设计的纹理映射函数的情况下,使用标准的图形管道将神经纹理从纹理空间光栅化到基于模板网格的屏幕空间。选择神经纹理作为变形方法有两个原因。首先,与高度依赖于精确底层几何体的其他显式变形相比,神经纹理嵌入了高维特征,这些特征可以补偿不完美的几何体,因此更适合模板网格不准确的设置。此外,与隐式变形方法不同,显式网格引导变形减轻了精细模仿学习的要求,同时获得了更好的表达式泛化。
生成纹理光栅化三平面 Tuv,将光栅化的纹理重塑为三平面表示,将这种表面变形调整为连续的体积。具体来说,Next3D 将基于模板网格的神经纹理光栅化为三个正交视图,并将它们放置在三个轴对齐的特征平面中。在实践中,考虑到左右对称性,光栅化应用于左视图和右视图,并且通过求和将光栅化特征连接到一个平面。
口腔合成模块

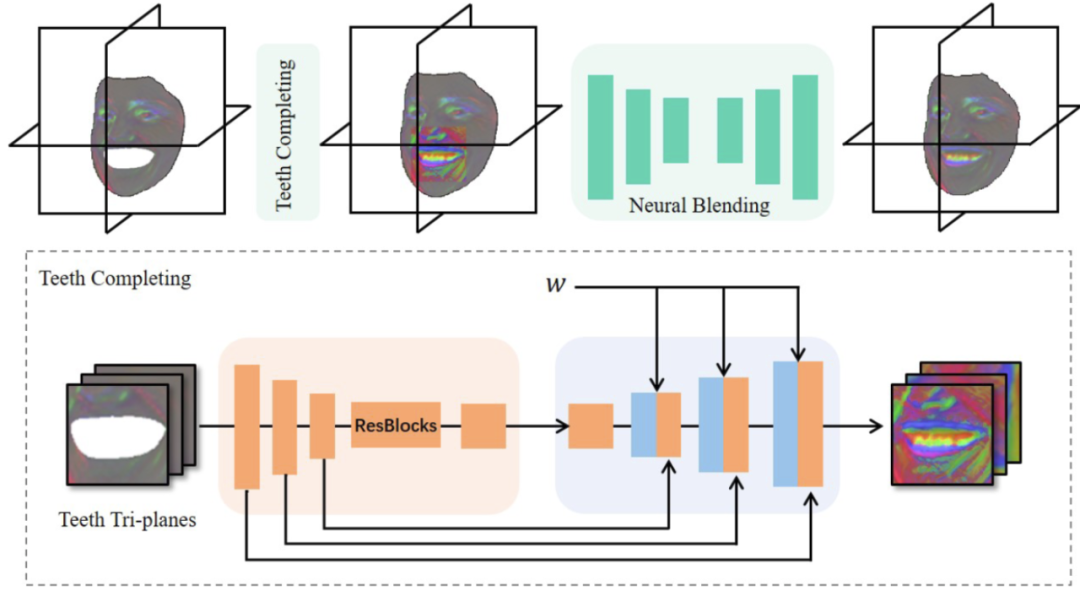
静态部分建模
生成纹理光栅化的三平面能够对不同表情和形状的动态人脸进行建模,然而合成 FLAME 模板中未包含的静态部分(如不同发型、背景和上身)是一项挑战。Next3D 通过另一个三平面分支 Tstatic 对这些部分进行建模,该分支由与 Gtexture 共享相同潜在代码的 StyleGAN2 CNN 生成器 Gstatic 生成。T’uv 和 Tstatic 的平面特征通过光栅化渲染的alpha遮罩在每个平面上混合。
神经渲染
给定混合的三个平面,对于 3D 空间中的任何点,我们将其投影到每个平面中,并对特征进行双线性采样。然后通过求和将采样的特征聚合,并通过轻量级解码器(具有softplus激活的单层MLP)将其解码为体积密度 σ 和特征 f。体绘制用于沿着投射通过每个像素的光线累积 σ 和 f,以计算 2D 特征图像 If。利用 2D 超分辨率模块 将特征图像变为具有更高分辨率的RGB图像 IRGB。超分辨率模块由三个 StyleGAN2 合成块组成,去除噪声输入以减轻纹理闪烁。If 和 IRGB 分别设置为 64×64 和 512×512。
训练约束
在训练过程中,我们使用R1正则化的GAN损失。此外,Next3D 采用了EG3D中提出的密度正则化。因此总的学习目标是:
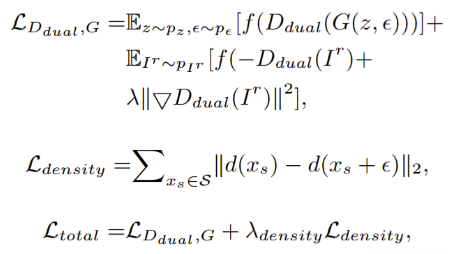
其中 Ir 是真实图像、模糊真实图像和相应的合成渲染的组合,它们是从具有分布 pI 的训练集中采样。
实验
Next3D 在 EG3D 的预训练模型的基础上训练模型,并在 4×3090 GPU 上继续训练大约 4 天。
数据集
Next3D 在 FFHQ 上训练和测试我们的方法。我们用水平翻转来增强 FFHQ,并使用离线姿态估计器来标记具有近似相机外部参数和常数内部的图像。为了支持全姿态动画,还考虑了平面内(滚动)旋转。此外,我们使用 DECA 来估计面部身份β∈ R100、下颌位姿 θ jaw∈ R3 和表达式 ψ∈R50 的 FLAME 参数。
定性比较

从上图中可以看出DiscoFaceGAN 在动画过程中存在身份不一致的问题。此外,它不能产生合理的口腔内部,例如拉伸的牙齿。3DFaceshop 和 AnifaceGAN 合成了 3D 一致的图像,然而仍然很难用驱动图像来建模一致的口腔内部。这是因为他们的隐式变形方法受到了约束,导致数据集的表情偏差过拟合。

从上图中可以看出不同模块的消融实验结果。
定量比较
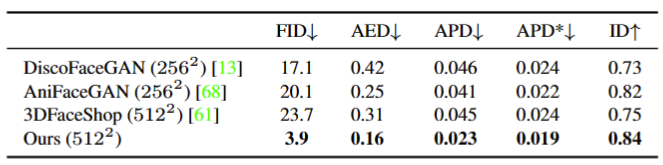
下表是 Next3D 与其他方法使用FID、平均表达距离(AED)、平均姿势距离(APD)和 FFHQ 的身份一致性(ID)进行定量比较。
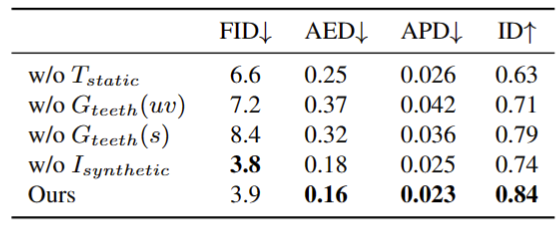
下表是不同模块消融实验的评估结果。
限制
尽管 Next3D 能够对一些罕见的表情(如眨眼、嘟嘴等)进行合理的推断,但很难对其他一些具有挑战性的表情进行完全一致的建模,如单侧嘴朝上、皱眉、吐舌头等,可以使用表情更丰富的高质量视频片段进行训练,也可以使用更强大的人脸模型进行更好的推断。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。