
剪枝是深度神经网络 (DNN) 的主要压缩方法之一,从 DNN 模型中删除不太相关的参数以减少其内存占用。为了获得更好的最终精度,通常迭代地执行剪枝,在每一步中删除越来越多的参数,并对剩余的参数应用微调(即额外的训练周期),一直持续到达到目标压缩比。然而,这个过程可能非常耗时。若采取一次性剪枝(在一个步骤中修剪所有参数并进行一次微调)来缓解这个问题,又可能会带来较高的准确性损失。
因此,本文提出了 ICE-Pick,一种新的阈值引导微调方法,它冻结了不太敏感的层,并利用了一个定制的剪枝感知学习率调度器。
来源:ICML 2023
论文链接:https://openreview.net/pdf?id=fWYKVtf7lu
作者:Wenhao Hu, Perry Gibson, José Cano
内容整理:王妍
ICE-Pick 剪枝方法
方法概述
为了减少迭代剪枝中的微调时间,本文提出了 ICE-Pick,一种结合阈值引导微调和层冻结的技术。ICE-Pick 不是在每个修剪步骤上对整个模型进行微调,而是当准确率降低低于用户定义的阈值时,冻结不太敏感的层并跳过重新训练,图1 给出了 ICE-Pick 的具体步骤。



ICE-Pick 有两个主要阶段。在阶段 1,冻结模型不太敏感的层;在阶段 2,对每一层进行修剪(虚线是修剪部分的边缘)并对模型进行微调,动态调整学习率。如果精度损失很低,则停止对给定步骤的微调。图中 1、2、3 显示了ICE-Pick 是如何随着剪枝级别的增加而逐渐降低学习率的,而在 4 中,当精度损失低于阈值时,停止微调。
层冻结
微调并不是枝剪所独有的概念。在迁移学习中,微调也是使模型适应新数据的重要步骤。与剪枝类似,迁移学习中的微调也非常耗时。为了解决这个问题,一些方法使用层冻结来加速微调过程,其中一些层的参数被“冻结”,因此在训练期间无法更改。由于在这两个任务中微调的作用相似,本文将层冻结应用于模型剪枝,如图 1 的第 3 行所示。
在微调期间,有些层的梯度变化比其他层小,通常是模型早期的层。因此,可以跳过对它们的训练,减少微调成本。
剪枝和微调
图 1 的第 4-11 行显示了剪枝和微调步骤。对于每一层,包括冻结层,使用过滤器剪枝。如果精度下降高于或等于阈值(第 6 行),那么触发微调,否则跳过它。用户提供准确度阈值,其值根据学习任务和用户对准确度损失的容忍度而变化。
如果触发微调,ICE-Pick 希望通过更快地收敛到更高的精度来最小化训练时间。研究表明,更窄的模型(即更小的宽度,每层滤波器更少)具有更窄的损失范围,这可能需要更低的最大学习率。因此,本文设计了一个剪枝感知的学习率调度程序,其中最大学习率由剪枝的级别,即平均宽度决定。最大学习率定义为:
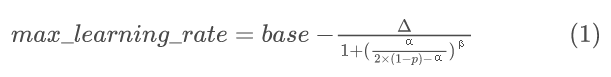
式中,α 为未修剪参数的比例,超参数为: base,初始学习率; ∆ ,剪枝过程中学习率的最大变化,取值范围为 (0,base) ; P,达到 ∆ 中点处的剪枝程度,取值范围为 (0,50%) ; β,控制曲线的形状,其范围为 (0,+∞)。通过调整这些超参数,可以灵活地制定不同类型的递减学习计划,以适应不同的情况。
实验评估
本文结合 CIFAR-10 数据集上定义的 ResNet-110 ,ResNet-152 和 MobileNetV2 三种模型,在 NVIDIA TITAN RTX GPU 上进行评估,每个实验取 10 次评估的平均值。采用 L1 范数评分的过滤器剪枝,并且在调度中每一步剪枝一个块,其中一个块是连续层的序列。对于微调,本文使用通过知识蒸馏增强的 SGD ,每一步最多一轮,动量为 0.9,权重衰减为 1e-4,训练和测试的批大小为 128。
层冻结验证
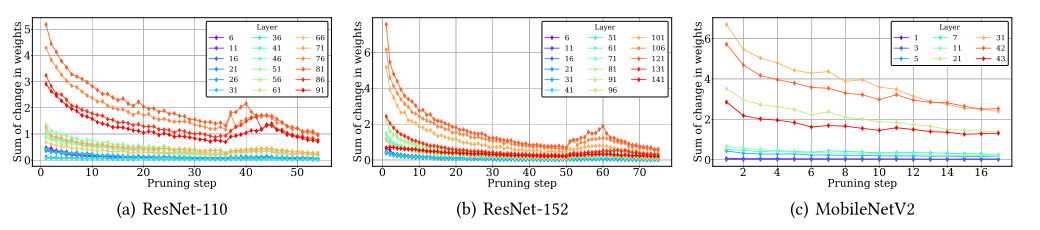
图 3 显示了不同层的权重如何随着微调量的增加而变化。在三个 DNN 模型中,较早的层倾向于看到较小的变化,并且层的顺序通常保持不变。这证明了冻结不太敏感的层(通过观察一个剪枝步骤的权重变化来确定)和只应用一次冻结步骤是合理的。
参数扰动
本文比较了不同的参数组合和剪枝比对准确率和总体剪枝时间的影响。对于基线,使用 0.001 的固定学习率进行修剪,并且不利用 ICE-Pick 的任何特征,例如冻结和准确性下降阈值。
不同冻结比
对于 ICE-Pick,使用不同的冻结比和 1.5% 的准确率下降阈值进行修剪。可以看到,较高的冻结率在总时间上有较高的减少。例如,在 40% 的剪枝水平下(图 4 a-c ),分别将 ResNet-110 、ResNet-152 和 MobileNetV2 所需的时间减少了 83.9% 、87.6% 和 74.0%。
对于更高的修剪比率,修剪时间的平均减少更低,因为更高的精度下降需要进行更多的微调。在 60% 的修剪比例下(图 4 d-f ),分别为 ResNet-110 、ResNet-152 和 MobileNetV2 节省了 71.4% 、76.9% 和 32.0%。
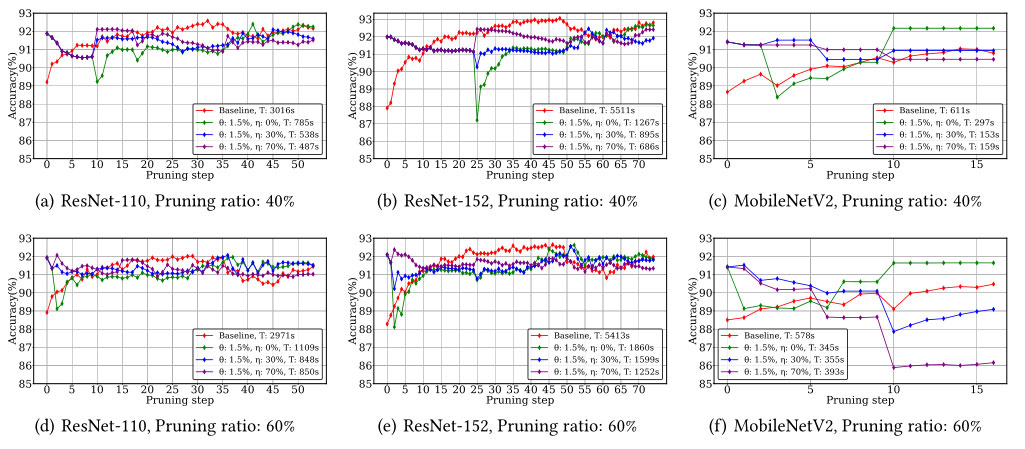
不同阈值
对 ICE-Pick 分别采用 0.5% 、1.5% 和 2.5% 的阈值,更高的阈值减少了所需的时间,同时仍然合理地保持了准确性。这表明即使精度下降阈值较大,ICE-Pick 也能保持最终精度。
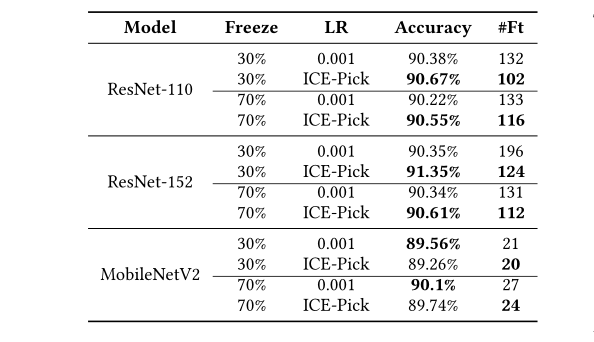
学习率调度器验证
为了验证 ICE-Pick 的学习率调度器,本文将其与固定学习率进行比较。这两种方法仍然使用层冻结和精度下降阈值来优化微调。在表 1 中,可以看到调度器对 3 个模型触发的微调明显减少。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。