
深度伪造(Deepfake)是深度学习(deep learning)与伪造(fake)二者的组合词,可实现图像、音频、视频的伪造生成。近年来人工智能技术发展迅速,语音深度伪造技术也日趋成熟,与之有关的一些网络安全问题也随之出现。例如2019年,有诈骗分子利用AI语音合成软件冒充英国某公司CEO的声音,通过电话诈骗了24.3万多美元,至今仍未找到幕后的罪犯。针对Deepfake语音检测的研究正在引起研究人员的广泛关注,ASVspoofing系列挑战赛也持续引领了伪造语音检测领域的发展。
音频伪造主要有三种类型,分别是录音重放、语音转换(VC)和语音合成(TTS)。录音重放是指对目标说话人的语音通过设备录制后进行编辑和回放以产生高度逼真的目标说话人语音。相比于deepfake技术,重放攻击容易实施,无需特定的专业知识和复杂的设备,因此常用于攻击ASV系统。重放语音与目标说话人的声学特征高度相似,但语音内容的可控性弱。
语音转换是指将源说话人的声音变换成目标说话人的声音,同时保持说话内容信息不变的技术。针对所需训练数据形式和数据对齐任务的不同,语音转换可分为平行语料和非平行语料的语音转换两类。平行语料即源说话人和目标说话人的训练数据成对且语音内容相同,非平行语料则内容不同。
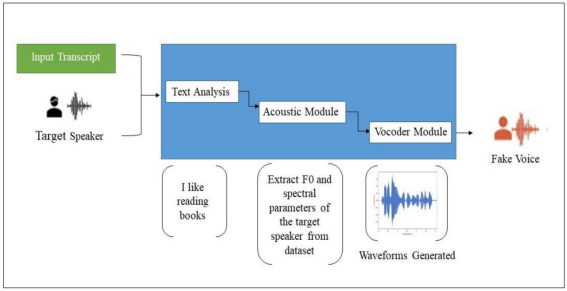
语音合成旨在将文本实时转换为可接受的自然语音,主要包括管道式(Pipeline)语音合成和端到端式语音合成两类。管道式语音合成通常包含文本分析模型,声学模型和声码器三个模块。管道式语音合成的过程如图所示,文本分析模块根据输入文本进行韵律预测和每个音素的时长预测;声学模型建立文本特征和声学特征之间的联系,根据文本分析的输出经由DNN映射到声学特征;声码器模块实现声学参数到语音波形的转换。端到端式语音合成系统直接把文本或者注音字符转换成音频波形,极大程度地降低了语音合成系统构建的复杂度,减少了合成过程中的人工干预和对语言学相关背景知识的需求。Tactoran 2、Deep Voice 3 和 FastSpeech 2是能够生成高质量自然语音的代表性模型,Tactoran 2使用改进的WaveNet声码器创建梅尔语谱图,基于注意力机制的 Deep Voice 3使用自回归解码器生成梅尔语谱图,同时引入非自回归的后处理转换网络,提高了语音合成的速度,FastSpeech 2 进一步提升了语音音质和生成速度。

语音伪造检测技术的基本思路是寻找伪造语音与真实语音之间的特征差异。典型的伪造语音检测系统一般由前端和后端两部分组成,前端通过分析语音信号提取具有区分性的特征,后端通过神经网络模型进行判定。伪造音频检测的方法一般可分为两大类:机器学习(ML)和深度学习(DL)方法。经典的ML模型已被广泛应用于伪造音频检测中,ML模型中的特征需要手动提取,并且在训练之前需要进行大量的预处理以确保良好的性能。然而,这是一项耗时且容易导致不一致性的工作,这促进了DL方法的研究。
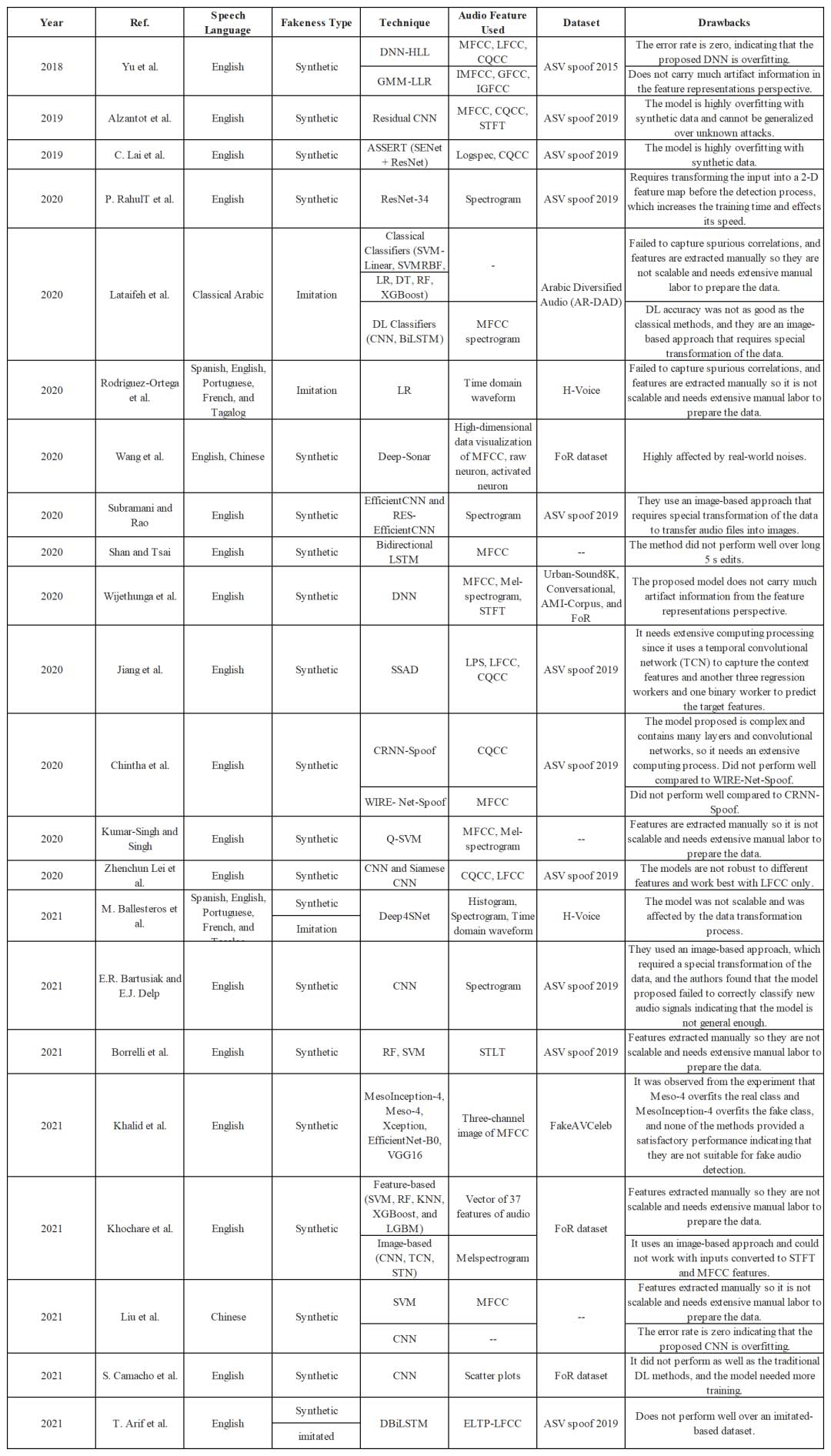
近年来基于深度学习的系统逐渐成为主流,系统前端提取输入神经网络的语音特征,后端则通过神经网络学习特征的高级表示,然后进行分类判决。尽管DL方法避免了手动特征提取和过度训练,但它们仍然需要对音频数据进行特殊转换。因此,引入了自监督深度学习方法进行检测,Jiang等人提出了一种自我监督伪造音频检测(SSAD)模型,该模型依赖于多层卷积块从音频流中提取上下文特征,EER为5.31% 。虽然SSAD在效率和可扩展性方面表现良好,但其性能不如其他DL方法。相关文献如下表所示,可以看出方法类型对检测性能的影响大于所使用的特征。很明显,无论使用何种特征,ML方法的准确性都高于DL方法。然而,由于训练过程繁琐且需要手动提取特征,ML方法的可扩展性尚未得到确认,特别是在处理大量音频文件时。
目前已经有部分端到端系统出现,可以直接将原始音频波形作为网络输入,学习高级特征表示后判决。然而,现有伪造语音检测方法大多依赖于特定的数据集或特定的伪造方法,训练数据种类单一且同分布,因此泛化能力较弱,该问题目前仍是伪造检测领域研究的核心难点,伪造音频检测仍需要进一步的研究来解决现有的差距。
参考:
1、Almutairi Z, Elgibreen H. A Review of Modern Audio Deepfake Detection Methods: Challenges and Future Directions.Algorithms. 2022; 15(5):155.
2、REN Yanzhen, LIU Chenyu, LIU Wuyang, WANG Lina. A survey on speech forgery and detection[J]. JOURNAL OF SIGNAL PROCESSING, 2021, 37(12): 2412-2439.
作者:宋芳婷、黄君如
来源:21dB声学人
原文:https://mp.weixin.qq.com/s/7HWrUKXklc0_zczV_n1nAg
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。