
文章来源:TOMM 2025
论文题目:A Hybrid Scheme for Face Video Compression
论文链接:https://dl.acm.org/doi/10.1145/3783982
论文作者: Anni Tang, Zhiyu Zhang, Chen Zhu, Jun Ling, Rong Xie, Li Song (SJTU Medialab)
内容整理:唐安妮
随着社交媒体的快速发展,人脸视频数据量呈现爆炸式增长,使得人脸视频压缩成为研究热点。传统视频编码技术对所有视频内容采用相同的压缩方式,而针对说话人头部视频的压缩应具有更大潜力。现有生成式压缩方法多采用静态参考帧,当视频中出现动态背景或大幅姿态变化时会导致保真度下降。本文提出一种融合传统编码与生成式压缩的人脸视频混合压缩方案:一方面,我们通过传统编解码器对关键帧进行采样编码,以提供包含实时背景与运动信息的动态参考帧;另一方面,我们设计了一种深度视频生成模型,可根据提取的稀疏关键点合成流畅的视频帧。该方案结合了传统编码的像素级还原能力与深度生成模型的细节生成能力,能够在低码率条件下实时实现高保真人脸视频压缩。此外,我们还设计了人像修复模块以提升低质量关键帧的重建质量,从而优化低码率场景下的压缩效果。大量实验表明,本方法在率失真性能与编码复杂度方面均优于传统编解码器及现有生成式压缩方法。
研究背景
随着社交媒体与短视频应用的爆发式增长,人脸视频数据量急剧上升,对存储与传输带宽造成巨大压力。高效的人脸视频压缩技术因此成为研究热点。现有方法主要分为通用编码与生成式编码两类:通用编码(如HEVC、VVC)泛化性强且能实现像素级还原,但难以兼顾码率与计算复杂度;生成式编码则针对人脸等特定内容,通过关键点、特征图等简化信息生成高质量视频,在低码率压缩中潜力显著。
然而,现有生成式压缩方法大多采用静态参考帧,即编码器使用一组固定且不随时间更新的高质量视频帧作为参考。当背景动态变化或人物姿态发生较大改变时,解码器仅依靠静态参考帧难以实现高保真重建,导致像素级还原能力和客观重建质量下降,且在高码率场景下性能受限。


为此,我们提出一种混合压缩方案:一方面,以动态参考帧(经传统编码的关键帧)提供实时背景与运动信息;另一方面,通过设计的深度视频生成模型,依据关键点合成非关键帧。该方案结合了传统编码的像素级还原能力与生成模型的细节生成优势,实现了低码率下的高保真人脸视频实时压缩。
本方案在码率控制上具有较高的灵活性,可通过调整关键帧的量化参数实现宽范围内的码率调节,并能根据存储或传输需求选择合适的编码配置。实验表明,所提方法在率失真性能与编码复杂度方面均优于传统编解码器及现有生成式压缩方法,能够在消费级设备上实现实时编解码,具有较好的实用性与可扩展性。
方法描述
本文提出一种将传统编码与生成式压缩相结合的混合编码方案,以实现低码率下的高保真重建。我们按一定频率提取关键帧作为动态参考帧,以提供实时的像素级信息(如背景、光照、姿态等),从而克服静态参考帧带来的缺陷。

编码端:对于输入视频序列,我们按固定频率采样关键帧(本文采用每10帧抽取1帧关键帧),并使用传统编解码器(如HEVC、VVC等)对其进行编码,其量化参数(QP值)可根据实际需求动态调整。对于所有视频帧,我们使用关键点检测器提取关键点,并通过无损编码方案进行压缩。最终码流由上述两部分组成。
解码端:一方面,解码传统编解码器生成的码流以重建关键帧;另一方面,无损解码关键点码流,并基于重建的关键帧和解码后的关键点,通过深度视频生成网络合成全部视频帧。
关键点检测和压缩
受FOMM启发,我们采用二维稀疏关键点作为面部表征,并使用如图所示的深度图条件关键点检测器:

首先,将视频帧输入预训练的深度估计器预测对应的人脸深度图;接着,将原帧与深度图拼接后输入检测器,以无监督方式预测10个稀疏关键点。关键点位置变化可反映面部运动信息。
在压缩方面,我们在FOMM的基础上移除了雅可比矩阵的预测,并将关键点从浮点型量化为8位整型,使单帧数据量从240字节降至20字节。随后采用无损编码方案(帧内/帧间预测结合指数哥伦布编码与自适应算术编码)进一步压缩,最终实现非关键帧平均4.98字节/帧的码率。各步骤压缩效率如表1所示。

深度视频生成网络
我们提出深度视频生成模型来实现非关键帧的高保真重建。如图所示,该模型包含潜空间动画模块(Latent Animation)与基于双向长短期记忆网络的潜空间融合模块(Latent Fusion),能够综合考虑前后关键帧信息,生成时序平滑的视频帧。
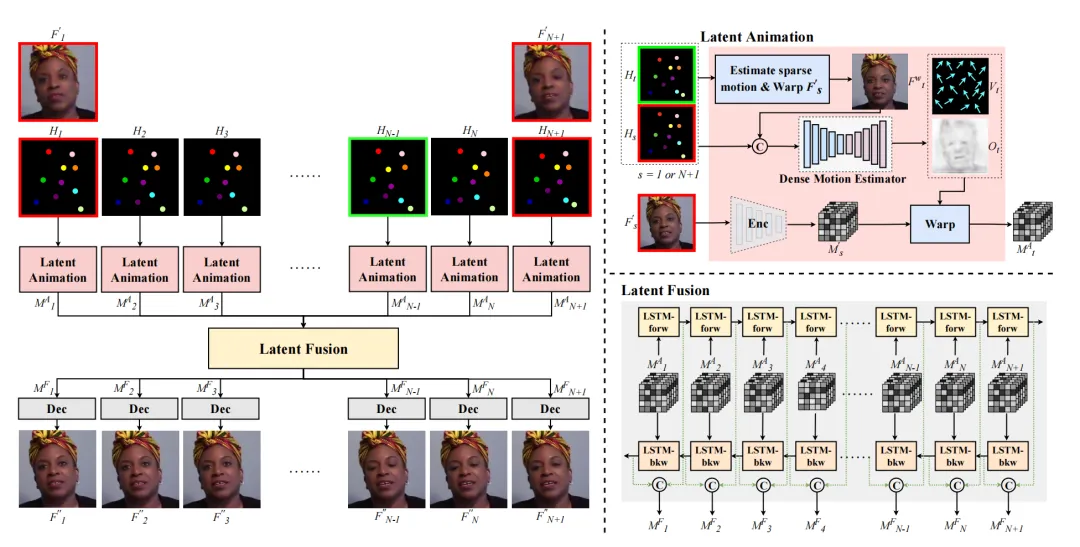
我们使用了L1重建损失、VGG感知损失、对抗损失以及一个正则化项来训练该网络。训练分为两个阶段进行:
- 第一阶段训练除潜空间融合模块外的全部网络组件,因为该模块会显著降低训练速度。具体而言,我们从视频中随机选取两帧分别作为源帧与目标帧,以端到端方式训练关键点检测器、潜空间动画模块与CNN解码器。
- 第二阶段固定关键点检测器与潜空间动画模块,集中训练潜空间融合模块并对CNN解码器进行微调。
人像恢复模块
为提升低码率场景下的重建质量,我们设计了一个人像恢复模块。该模块利用已累积的高质量关键帧补充纹理细节,将低质量关键帧恢复为高质量图像。

如图5所示,采用6个串联的PR-SPADE残差模块进行纹理增强,最终解码生成恢复后的图像。
具体实现时,选取历史最清晰的关键帧作为高质量参考帧,结合关键点热图估计稀疏运动场,将参考帧形变对齐至当前帧以提供纹理参考。该形变结果通过预测归一化层的缩放与偏置参数,实现特征图的空间自适应调整。
该模块同样采用L1重建损失、VGG感知损失与对抗损失进行训练。实验表明,在量化参数≥40的低码率场景中,该模块能显著提升重建视频的视觉质量。
实验部分
对比实验
我们将提出的方法与以下方法进行比较:传统编解码器x265和VVenC(一种高效的VVC实现,其压缩性能接近VVC但编码复杂度显著更低),生成式压缩方法FOMM、MRAA、OSFW、CFTE、DAC、RDAC与我们先前的人脸编码工作,以及当前先进的端到端视频压缩方法DCVC-DC。率失真性能的比较结果如图6所示。

如图7所示,FOMM、MRAA、OSFW和CFTE均使用单个静态帧(首列)作为参考来引导所有帧的合成,而其余方法则采用动态参考帧来引导合成。

具体而言,在第一行示例中,视频背景发生动态变化。生成式压缩方法通常侧重于面部动画与合成,采用静态参考帧无法重建实时变化的背景,导致保真度下降。第二行中,基于静态参考帧合成的图像未能完整还原被遮挡的背景,造成重建质量降低。在最后两行示例中,当参考帧与目标帧之间存在大幅头部姿态变化时,会出现不同程度的形变与伪影,严重影响视觉感知。相较之下,采用动态参考帧的方法能更好地处理动态背景与大幅姿态变化。其中,我们提出的混合方案得益于精心设计的合成模块,在低码率下实现了更优的视觉质量与重建保真度。
编码复杂度
各方法的编码复杂度测试结果如表2所示:

VVenC压缩性能强但计算量大,x265可实现实时编码但码率较高。本文提出的混合方案能在码率与计算量间取得更好平衡:以x265编码关键帧并结合生成模型合成中间帧,在保证较低复杂度的同时获得优于VVenC的率失真性能。相比现有生成式方法,本方案采用动态参考帧与优化的合成模块,在相近复杂度下实现了更高重建保真度;其宽范围码率可调特性也带来了更强的灵活性与实用价值,提升了合成视频的质量上限。
消融实验
在前期研究中,我们发现直接进行逐帧预测容易导致合成帧与下一关键帧之间出现明显跳变,为此,我们引入时域融合机制。最初设计的像素级融合虽能缓解抖动,但在本方案中会产生视觉伪影(如图8第一行所示,整体模糊且眼部存在严重失真)。相比之下,采用潜空间融合的第二行合成帧在真实感与保真度上表现更优。

定量实验结果表明,潜空间融合在各项指标(尤其是衡量运动一致性的tOF指标)上均更优。原文中的主观实验也能证明这一点。

关于人像恢复模块,我们探究了高质量参考帧的选择对恢复结果的影响,实验结果如表4所示。

此外,我们调整了关键帧的采样间隔𝑁,并在表5中展示了相应的编码性能。可以看出,在关键帧编码质量固定的情况下,随着𝑁的增大,整体码率会下降,但重建质量也会随之降低。同时,𝑁增大时解码过程占用的GPU内存也会增加。本文最终选择了𝑁=10这一折中方案。

更多实验结果及分析请参考原文。
讨论
应用场景
随着人脸视频数据量激增,本文提出的高效压缩方案能显著缓解存储与带宽负担。一方面降低存储成本,为个人及服务商节省开支;另一方面减轻网络负载,提升传输速度并减少用户流量消耗,使弱网环境下的视频体验成为可能。此方案支持在消费级设备上实时编解码,显著改善用户体验,拓展了视频通话、会议等实时通信的应用潜力。此外,本方案还可与通用视频压缩方法结合,通过分区编码实现优势互补。
延迟问题

在LDP模式下,默认解码器会产生约333毫秒的延迟(𝑁=10时),这对视频会议而言偏高。为此,我们提出一种优化方案:仅对靠近下一个关键帧的部分连续帧(如最后5帧)进行潜空间融合,其余非关键帧则基于前一个关键帧通过潜空间动画直接重建。如图9所示,这种延迟友好型解码方案可将固有延迟稳定控制在4帧(以30fps视频为例约133毫秒),符合实时视频通信的要求。
未来工作
在视频会议等固定人物场景中,可利用用户预先录制的视频对生成模型进行微调,使其学习特定说话风格与动作模式,从而提升性能。具体可优化低延迟解码器的帧融合效果,或采用更稀疏的关键点表征以降低码率。
本研究虽聚焦人像视频,但传统编码与生成式压缩相结合的思路,有望拓展至各类2D/3D视频的低码率高保真压缩。未来还可探索将该框架作为传统编解码器中预测模块的生成式替代:关键帧作为帧内编码帧,关键点流替代运动矢量等预测元素。由于生成式重建不参与后续预测循环,该架构对数据丢失具有天然鲁棒性,尤其适用于不稳定网络传输。
结论
本文提出的混合压缩方案结合传统编码的像素级还原与深度模型的细节生成能力,实现了低码率下的实时高保真人脸视频压缩。相比传统编解码器和现有生成式方法,该方案在码率、重建质量和计算复杂度上具有综合优势,且具备适应不同场景的灵活性。研究验证了其在实时通信中的可行性,并揭示了传统编码与AI生成技术融合的巨大潜力,为未来视频压缩研究提供了新方向。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。