
随着科技的不断发展,AI语音驱动的虚拟形象越来越受到关注,用户通过输入文本或语音,以一定规则或深度学习算法,完成口型和面部表情的精准驱动,以快速构建丰富的虚拟形象智能驱动应用,此项技术已大规模应用至虚拟形象产业。
据IDC预测,中国数字人市场规模预计到2026年达102.4亿元。但数字人表现力不足仍是制约行业发展的一大难点,仅面部/手部动作并不足以理解人类行为,捕捉与语音一致协调的人体全身的运动,对于数字人/虚拟代理进行交互至关重要。
为了能够保证身体运动与音频更一致,发挥出虚拟形象的真正用处——实现有意义且真实连贯的交互行为,京东探索研究院提出一个新的语音到全身运动的方法,首先,建立了高质量的3D身体网格数据集;其次,将脸部表情,身体姿态和手部动作分别训练生成模型。通过定量评估表明京东探索研究院的语音合成富有表现力的三维人体具有最为可靠的生成质量。


01 技术挑战
首先,所有的虚拟数字人其背后的算法和模型都需要高质量的数据进行大量训练、测试、调参才能达到最终的最优效果。而三维整体身体网格和同步语音记录的数据集非常少,而且由于复杂的运动捕捉系统,它们很难获得。
其次,真实的人类往往形状各异,而且他们的脸和手都是高度可变形的,要生成逼真和稳定的三维整体身体网格的结果并不容易。
最后,由于不同的身体部位与语音音频的关联性不同,因此很难建立跨模式的映射,并产生真实的和多样的整体身体运动。
02 研究方法
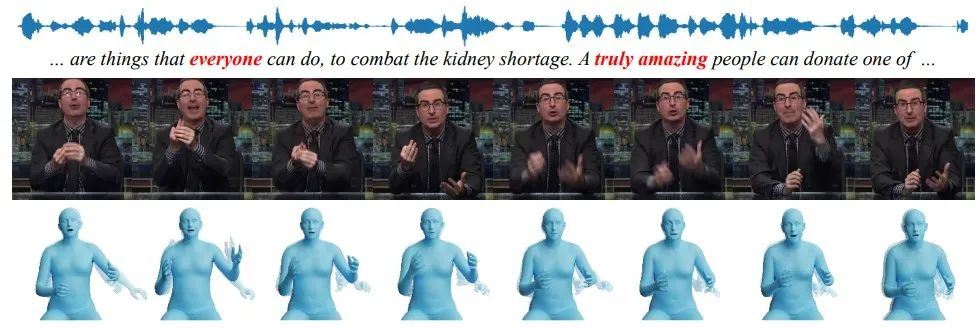
给定一个语音信号作为输入,我们的方法产生现实的,连贯的,多样的整体身体运动;也就是说,身体运动连同面部表情和手势。从上到下:输入音频、相应的脚本、视频帧和生成的动作。
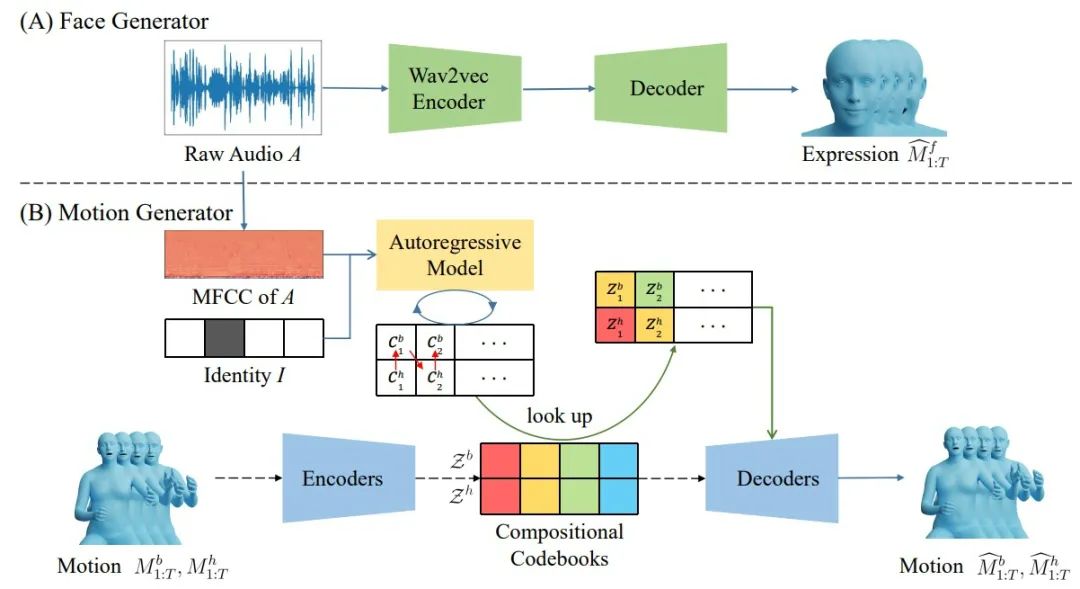
[1] 首先建立了一个高质量的3D整体身体网格的高质量数据集,并进行同步语音。
[2] 然后提出了一个新的语音到运动的生成框架,其中,脸部、身体和手被分别建模。分离建模源于这样一个事实,即脸部发音与人类语音密切相关,而身体姿势和手势与人类语音关联性较小。
[3] 具体来说,对脸部动作采用自动编码器,对身体和手部动作采用复合矢量量化自动编码器,用于身体和手部运动,这是产生多样化结果的关键。
[4] 此外,还提出了一个交叉条件自回归模型,用于生成身体姿势和手势,从而产生连贯而真实的运动。
经过定量评估来验证合成的运动的真实性和多样性。与基线方法相比,探索的方法在合成运动的真实性和多样性分别为0.414和0.821。
为了进一步证实定性结果,我们通过广泛的用户研究来评估该方法。与基线方法相比,90.3%的用户选择了京东探索研究院生成的人体运动与给定的语音更匹配。定量和定性的研究都表明我们的语音合成富有表现力的三维人体具有最为可靠的生成质量。
有了该技术的加持后:
利于产生共鸣。当数字人能够通过身体连贯动作和面部表情来模拟人类的行为和表情时,这种丰富的交互方式会让人们会更容易理解和产生共鸣。
可以提高交流效率。当数字人能够通过身体动作和面部表情传达信息时,用户可以更直观地理解数字人的意图和情感状态,从而降低交流的误解和障碍。
提升用户体验。更贴合语义的完整身体运动交互,可以让人类感受到数字人的生动性和亲和力,从而更加愿意与之交流,从而提升相关的产品和服务的接受度。
在数字人方向京东拥有深厚的技术积累,京东云旗下的言犀数字人如今已服务伊利、联想、国台酒业、六神、蔓迪、skg、同仁堂、Swisse等超过4000品牌,带动超过10亿元GMV。借助言犀虚拟主播,蔓迪直播销售转化率提升16%,平均GMV占比真人主播达25%,成本降低15%;同仁堂成交转化率超5%,还打造多个平台AI直播矩阵;六神初次开播,半月成交转化率就高达39%,转粉率达3.5%。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。