
语音领域每年都有很多比赛,每个比赛都有自己的侧重点,其中CHiME系列比赛的侧重点就是多通道远场语音识别,与其他的语音识别比赛有所区别的是,CHiME提供分布式麦克风和麦克风阵列数据,这样可以选择合适的前端算法以降低识别的WER,著名的CGMM-MVDR也是在这个比赛中提出的。CHiME比赛今年已经是第8届了,今天我们一起看看下官方提供的基线系统。
自从CHiME7之后,麦克风阵列的几何结构信息就不能被用于前端语音增强,因此一些传统的方法无法使用。CHiME官方提供的baseline支持多通道、多说话人的语音输入,整体可以划分为3个部分:
- Speaker Diarization Module
- Multi-channel Audio Front-End Processing Module
- ASR Module
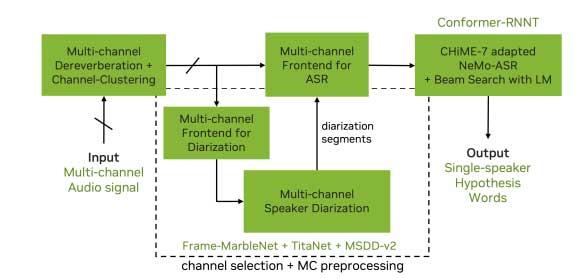

I、Speaker Diarization Module
这个模块的主要工作是说话人分离,确定包含多人交替说话的语音中每个时间点是谁在说话,这里加入前端处理模块来提升说话人分离的精度。说话人分离模块主要包含以下几个算法:
1、MIMO-WPE Dereverberation
WPE是MIMO去混响的经典算法,这里使用block-wise的WPE算法,窗长为40s,重叠2s。整个处理过程STFT的窗口长度为64 ms,75%的overlap。使用10帧滤波器、预测延迟为3帧,迭代10次。
2、Channel Clustering
对经过WPE算法的音频计算幅度平方相干矩阵
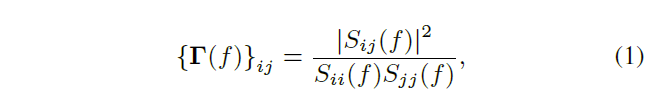
然后使用归一化最大特征裂隙的谱聚类(normalized maximum eigengap spectral clustering, NME-SC)方法对上述相干矩阵进行聚类,最后每个类别的信号取平均以减少音频输入通道数。
3、Multi-channel VAD
多通道VAD采用了MarbleNet的网络结构每次对20 ms的数据进行判决,使用了接近2000小时的音频进行训练,在多通道VAD的推理过程中,我们丢弃VAD概率低于50%的通道,并对其余通道VAD概率进行取最大值的操作作为最终VAD的预测结果。

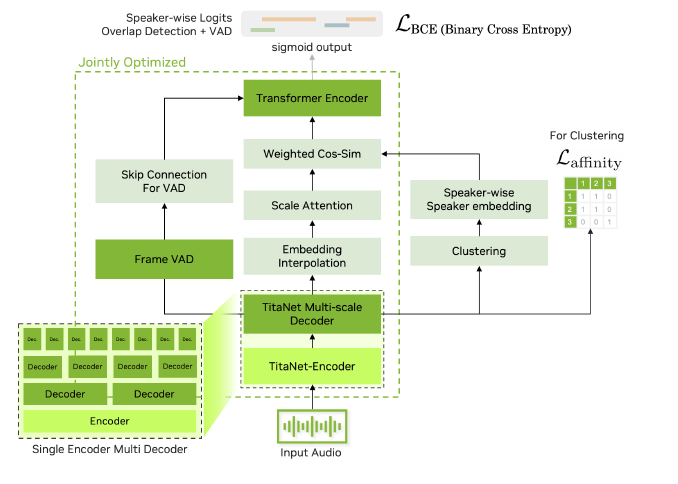
4、Multi-channel Diarization Module
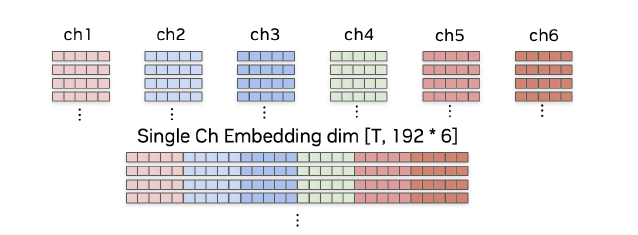
这个模块使用了一个多尺度的说话人分离解码器(multiscale diarization decoder, MSDD),该系统采用多尺度嵌入方法并利用 TitaNet作为说话人embedding的提取器。多尺度示意图如下,分别提取0.5s、1.5s和3s,3个不同的尺度,相同尺度下,数据重叠50%:

所有通道对应不同尺度的embedding最后concat到一起形成最终的多通道多尺度说话人的embedding
最后上述的embeddings会被送入基于attention的MSDD进行处理,说话人分离完整的pipeline如下所示:
II、Multi-channel Audio Front-End Processing Module
多通道音频前端主要目的是提取单个说话人目标的语音信号,整体流程如下所示

1、Envelope variance based channel selection
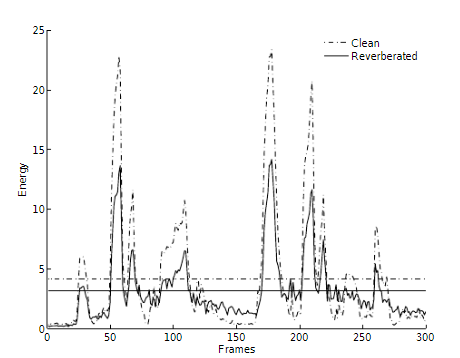
远场语音识别受到噪声和混响影响比较大,对于多个通道的场景如何选择适合声学模型识别的信号就显得比较重要,这里采用的方法是基于包络方差的方法去评估语音质量。下图是混响语音和纯净语音filter-bank的能量可以看出还是有较大的差别,因此可以通过这种方法去选择合适的通道作为语音识别的输入。
2、MIMO dereverberation
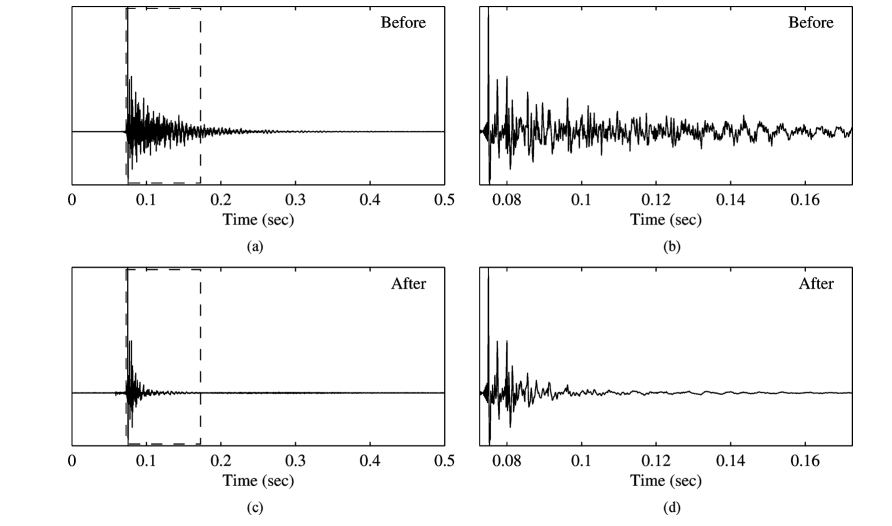
这里采用了另外一种MIMO的子带域多通道线性预测方法算法去混响。该方无需假设特定声学条件,其效果如下图所示,可以看出晚期混响明显被抑制。
3、Guided source separation
GSS采用了复角度中心高斯混合模型(complex Angular Central Gaussian Mixture Model,cACGMM),并计算其概率密度函数,然后通过EM算法进行求解,最后可以得到TF-mask。接着将GSS计算得到的Mask送入MIMO MVDR系统,结合最大后验信噪比进行通道选择得到增强后的语音。
III、ASR Module
ASR网络采用了Conformer-Transducer的网络结构 ,相关内容可以参考我们前段时间的一篇文章细数语音识别中的几个former。该网络结构参数量为0.6B,为了提升ASR的性能构建了基于BPE的N-gram语言模型。
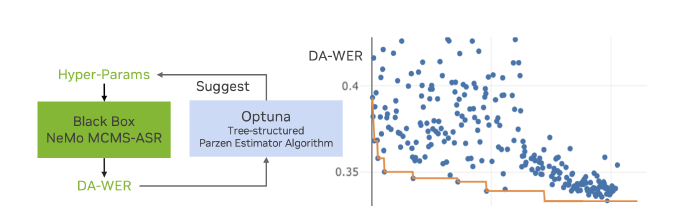
此外baseline还引入进行超参数优化,该框架有助于根据评估系统性能的目标指标优化黑盒系统的参数,其流程如下图所示。
III、Conclusion
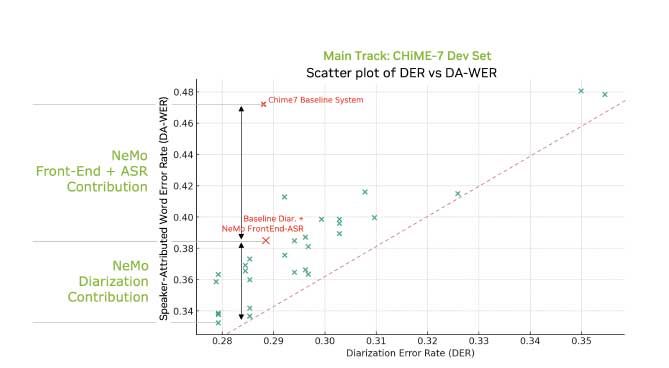
总的来说,CHiME-8的系统比较复杂,为了提升远场语音识别的精度在数据送到ASR系统前进行了很多的处理,而实验结果也表明这些工作的确带来了WER的降低,pipeline中的某些环节可以在实际中进行应用。
参考文献:
[1]. https://www.chimechallenge.org/current/task1/baseline
[2]. https://arxiv.org/pdf/2310.12378.pdf
[3]. https://arxiv.org/pdf/2306.13734.pdf
[4]. https://arxiv.org/pdf/2010.13886.pdf
[5]. https://www.researchgate.net/publication/259118453_Channel_selection_measures_for_multi-microphone_speech_recognition
[6]. https://www.audiolabs-erlangen.de/media/pages/resources/aps-w23/papers/259461a00d-1663358899/sap_Yoshioka2012.pdf
[7]. https://groups.uni-paderborn.de/nt/pubs/2018/INTERSPEECH_2018_Heitkaemper_Paper.pdf
作者:Ryuk
来源:语音算法组
原文:https://mp.weixin.qq.com/s/Fs_2vD1RHUY67v1V-8AHaw
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。