
本文提出了一种动态的状态空间模型 Content-Aware Mamba(CAM),并基于它构建了图像压缩模型 CMIC。作者指出,标准 Mamba 在图像压缩中存在两个关键瓶颈:其一,固定的 raster scan 无法有效建模空间上相距较远但语义上高度相关的 token;其二,严格因果的序列建模方式与图像本身的非因果结构并不匹配。为此,CMIC 引入了内容自适应 token 重排(Content-Adaptive Token Permutation, CTP)和全局先验提示(Global-Prior Prompting, GPP),在保持线性复杂度的同时提升长距离冗余建模能力,并在 Kodak、Tecnick 和 CLIC 数据集上达到了 SOTA 性能。
文章来源:ICLR 2026
论文题目:Content-Aware Mamba for Learned Image Compression
论文作者:Yunuo Chen, Zezheng Lyu, Bing He, Hongwei Hu, Qi Wang, Yuan Tian, Li Song, Wenjun Zhang, Guo Lu
(SJTU Medialab, MIT, Alibaba Group, Shanghai AI Laboratory)
论文链接:https://openreview.net/pdf?id=WwDNiisZQm
代码链接:https://github.com/UnoC-727/CMIC
内容整理:陈予诺
图像压缩模型需要的非线性变换与交互模式
压缩要做的事情,本质上是识别并消除冗余。而图像中的冗余往往并不是局部的、规则网格状的,也不是严格单向的。比如,天空中相隔较远的两块平滑区域、物体表面不同位置的相似纹理、以及场景中反复出现的重复结构,都对应着跨空间位置的相关性。这意味着,一个有效的图像压缩模型不仅需要足够大的感受野,还需要具备在非欧氏内容空间中建模 token 关系的能力。
在 learned image compression 中,非线性变换网络承担着建模潜变量之间统计依赖、进而压缩冗余信息的核心作用。更具体地说,内容相似的 token 往往意味着它们之间存在更强的冗余性,因此模型应当尽可能促进这类近似 token 之间的有效交互,从而提升对长程冗余的建模能力。早期图像压缩方法大多依赖 CNN 或 window-based Transformer 作为非线性变换骨干,但这类方法的交互模式通常受限于局部感受野,难以充分捕捉跨区域的冗余关系。近期,一些工作开始尝试引入 Mamba-style 空间状态模型,希望以线性复杂度实现对全局冗余的建模;然而,这类方法在图像压缩场景下仍然存在若干关键局限。
为什么 Mamba 还没有真正“吃透”图像压缩
近年来,Mamba 一类状态空间模型(SSM)在视觉任务中越来越受到关注。它的核心优势在于:相比 Transformer 的二次复杂度,全局建模能力可以通过线性复杂度实现。这对图像压缩这种既需要大感受野、又在意效率的任务来说非常有吸引力。
但问题在于,标准 Mamba 最初是为一维序列设计的。当它被直接搬到图像压缩里时,通常需要先把二维图像特征“扫”成一维序列,再做 selective scan。这个过程本身就引入了两个不太合理的假设:
第一,它默认 token 之间应该按固定空间顺序交互,也就是 raster scan 或若干预定义方向的 scan。可在压缩任务里,真正重要的并不一定是“空间上邻近”的区域,而往往是那些视觉内容相似、统计冗余相近的区域。它们可能在图像上离得很远,但在压缩建模里恰恰应该被放到一起看。
第二,Mamba 的递推建模是严格因果的。当前 token 只能看见前面已经扫描过的 token,这种单向依赖对于语言序列很自然,但对于图像并不自然。图像没有天生的“前后顺序”,远处的后续区域同样可能包含对当前编码很关键的信息。
因此,标准 Mamba 的问题并不只是“扫描效率”或者“感受野够不够大”,更深层的问题在于:它的扫描路径和信息流方向,都没有对齐图像压缩真正关心的冗余结构。


具有冗余感知的空间状态模型
核心思想:不要再让 Mamba 按照图像坐标系机械地进行因果性建模,而要让它沿着内容相关性去感知并建模冗余。
内容自适应 Token 重排:让相似内容排着队被扫描
标准 Mamba 的第一个核心问题,是扫描顺序完全固定。
CMIC 对这个问题的处理很直接(Content-Adaptive Token Permutation, CTP):既然压缩更关心“谁和谁内容相似”,那就先把相似的 token 聚在一起,再让 Mamba 去扫描。这样,原本在二维空间里相距很远、但在特征空间里很接近的区域,就能在一维序列中变成相邻 token,从而更容易被状态空间模型连续建模。
作者没有采用每张图在线跑一遍 K-Means 这种昂贵又不稳定的方式,而是借鉴 VQ-VAE 的思路,为每个 CAM block 维护一个共享的、可更新的聚类 codebook。训练时,使用余弦相似度的 K-Means 对 token 做聚类,并通过 EMA 更新质心;推理时则直接用训练好的质心进行确定性分配,不需要再做迭代聚类。
这样一来,CMIC 实际上把“二维图像上的 token”重新映射成了“按内容组织的一维序列”。Mamba 不再被困在欧氏空间的邻域关系里,而是优先沿着特征空间的近邻去传播状态。这一点对于压缩尤其关键,因为压缩真正要消除的是冗余,而冗余更接近于内容相似性,而不是几何位置上的相邻性。
从下图中的聚类可视化也能看出,这种重排不是机械分组,而是真正把一些具有相似语义或视觉统计属性的区域归到了一起,比如天空、纹理边缘、羽毛等区域往往会被一致地激活到某些 cluster 上。

全局先验提示:让 Mamba 不再被严格因果束缚
即便 token 顺序已经变得更合理,标准 Mamba 仍然有第二个问题:它还是严格因果的。也就是说,就算你把相似 token 放到一起了,当前 token 的状态更新仍然只能依赖于前面已经扫描过的内容。这种单向递推对图像来说依然过于受限。
因此,CMIC 又提出了第二个关键设计:Global-Prior Prompting(GPP)。这个模块的直觉是:既然单向扫描无法天然看到全局,那就在扫描过程中显式注入一个样本级的全局先验。
前面 CTP 利用的是聚类的结果,却并未利用好聚类得到的 质心 (cluster centers) 信息。质心本身具有很强的 dataset-level 统计信息,因此,作者构建了一个 redundancy-aware prompt dictionary。每个 cluster 映射到一个 prompt 向量,而对某张具体输入图像,可以根据它的 token-cluster 分配关系,生成一组 sample-specific prompts,再把这些 prompts 注入到状态空间模型的输出投影中。
这么做的意义在于,Mamba 在每一步读取状态时,不再只依赖前面 token 的递推结果,而是同时受到一份来自整张图像统计分布的全局先验调制。这样,模型虽然形式上仍然保留了线性扫描,但其信息流已经不再是“纯粹的单向局部因果链”,而是带有全局语义条件的扫描过程。
从下图(Mamba layer 单层感受野可视化)中可以看到,增加 GPP 能够有效打破原有的严格扫描因果性:扫描的中心位置时,后续位置也会出现非零响应,说明模型开始具备“看向未来”的全局语义感知。

可以把它理解成:CTP 负责“把该靠近的 token 排到一起”,而 GPP 负责“让扫描时每一步都带着对整张图内容分布的理解”。两者一个改路径,一个改信息流方向,刚好对应解决标准 Mamba 在压缩中的两大根本问题。
整体框架
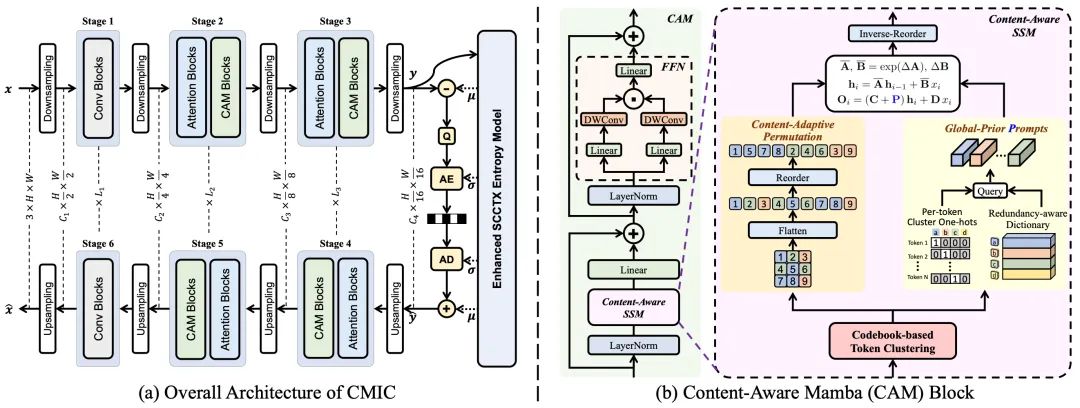
CMIC的整体框架如上图所示。
需要注意的是:在每个 stage 中,作者依然保留了 window attention 来负责局部依赖建模,而 CAM block 负责更高效地建模长程冗余。换句话说,整个系统的设计不是要完全抛弃注意力,而是让注意力负责局部,让内容感知的 Mamba 负责全局,这样能兼顾局部细节和全局压缩效率。
实验
主实验:率失真性能


论文在 Kodak、Tecnick 和 CLIC 三个标准数据集上进行了评测,并与 VTM-21.0、ELIC、TCM、FTIC、CCA、MLIC++、MambaVC、MambaIC 等一系列强基线进行了比较。
结果非常直接:CMIC 在三个数据集上相对 VTM-21.0 分别取得了 15.91%(Kodak)、21.34%(Tecnick) 和 17.58%(CLIC) 的码率节省,整体表现达到 SOTA 水平。
进一步看,它比近年的 Mamba-based LIC 模型更强。和 MambaVC 相比,CMIC 在 Kodak / CLIC / Tecnick 上分别额外节省了 7.51% / 6.80% / 10.09% 的 BD-rate;和 MambaIC 相比,也分别有 2.36% / 2.17% / 6.48% 的优势。
从论文给出的 RD 曲线可以看到,这种优势不是某个单独码率点上的偶然收益,而是在多个 bit-rate 区间内都比较稳定。尤其在高分辨率的 Tecnick 和 CLIC 上,CMIC 的优势更明显,这也侧面说明:当图像分辨率更高、长程冗余更丰富时,内容感知的全局建模确实更有价值。
除了 PSNR,论文也报告了 MS-SSIM 结果。CMIC 在这一指标下同样保持了很强的竞争力,说明这种改进不仅反映在像素失真意义上的 RD 优势,也体现在整体感知质量上。
复杂度与高效性
CMIC 的参数量为 69.11M,FLOPs 为 2.39T,2K 图像解码延迟约 0.405 秒,峰值显存约 4.44GB。和 TCM-L 相比,CMIC 在 FLOPs、延迟和显存上都更省;而和同样基于 Mamba 的 MambaIC 相比,CMIC 的参数量下降了 56%,FLOPs 下降了 57%,解码延迟下降了 39%,峰值显存更是下降了 78%。
这说明 CMIC 的收益并不是建立在“更重的全局扫描”上。相反,它避免了昂贵的多方向扫描和 2D 扫描,而是通过更合理的 token 组织方式和更轻量的全局提示,把计算用在了真正和冗余建模相关的地方。从工程角度看,这一点很重要。因为图像压缩方法最终不仅要拼客观指标,还要考虑推理代价和部署成本。CMIC 在这一点上是比较平衡的。
可视化分析:CMIC 真正学到了“看哪里更重要”


这篇论文通过 ERF(Effective Receptive Field)展示了模型对于冗余分布的感知能力。在整体 ERF 可视化中,CMIC 的感受野覆盖明显更广,表明它能够更充分地利用全局上下文。而在单图像的 ERF 可视化中,CMIC 的高响应区域并不是均匀扩散的,而是会主动对齐到语义相关或冗余较高的区域,比如羽毛、海岸线、飞机结构等。这说明它不是“更大范围地平均看”,而是真正学会了按内容分配注意力和状态传播路径。
结论
CMIC 这篇工作的核心在于 指出:如果不改变扫描顺序和信息流方式,Mamba 在图像压缩中的潜力其实远远没有被释放出来。 CMIC提出的一种解决思路是:
- 用 Content-Adaptive Token Permutation 把内容相关的 token 聚到一起,让扫描路径更符合冗余结构;
- 用 Global-Prior Prompting 把全局统计先验注入状态空间模型,缓解严格因果约束;
- 在此基础上构建 CMIC,在保持较高效率的同时,显著提升率失真性能。
如果说过去我们更多是在讨论“Transformer 怎么做全局建模、Mamba 怎么做线性建模”,那 CMIC 提供了一个很重要的视角:对于图像压缩,关键不只是模型有没有全局感受野,而是这个全局建模过程是否真正对齐了图像中的内容冗余。
如果有帮到你,感谢引用:
@inproceedings{
chen2026contentaware,
title={Content-Aware Mamba for Learned Image Compression},
author={Yunuo Chen and Zezheng Lyu and Bing He and Hongwei Hu and Qi Wang and Yuan Tian and Li Song and Wenjun Zhang and Guo Lu},
booktitle={The Fourteenth International Conference on Learning Representations},
year={2026},
url={https://openreview.net/forum?id=WwDNiisZQm}
}版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。