
本工作由上海交通大学宋利教授带领的Medialab实验室成员产出,并被ECCV2022录用。本工作提出了一种基于Transformer的端到端视频目标跟踪算法框架。该框架使用上下文特征信息对当前帧进行时序增强,从而替代传统的实例层面的特征增强。其次,通过估计参考帧和关键帧的特征位置偏移来指导空间信息的传递。实验证明该方法可以有效地利用时序信息来增强检测效果。
来源:ECCV 2022
论文作者:Han Wang, Jun Tang, Xiaodong Liu, Shanyan Guan, Rong Xie, Li Song.
论文链接:https://arxiv.org/pdf/2209.02242.pdf
项目链接:https://github.com/Hon-Wong/PTSEFormer
摘要
近年来出现了一种应用上下帧来提高检测的性能的研究趋势,即视频目标检测。现有的方法通常会融合时序特征以增强检测性能。然而,这些方法通常缺乏来自相邻帧的空间信息,并且存在特征融合不足的问题。
为了解决这些问题,我们执行了一种渐进的方式来引入时间信息和空间信息以进行集成增强。时间信息由时间特征融合模型(TFAM)引入,通过在上下文帧和目标帧(需要检测的帧)之间进行注意机制。同时,我们采用空间转移模型(STAM)来传达每个上下文帧和目标帧之间的位置转换信息。我们的 PTSEFormer 建立在基于 Transformer 的检测器 DETR 之上,还遵循端到端的方式来避免繁重的后处理程序,同时在 ImageNet VID 数据集上实现 88.1% 的 mAP。
介绍
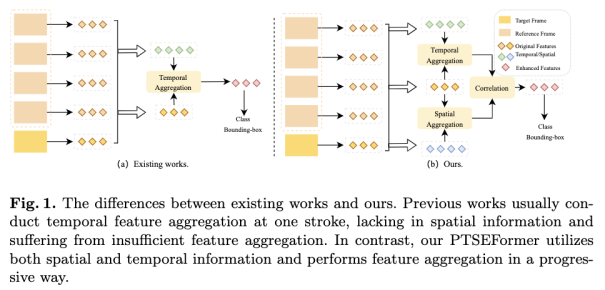

给定目标帧及其上下文帧,视频目标检测旨在检测目标帧中的对象,并通过上下帧的时序信息增强当前帧的检测效果。通过从上下文帧中观察不同姿势的相同实例,可以解决许多困难的情况,例如模糊的外观和背景遮挡。
以前的作品研究通常会单次地融合时序特征,存在时间信息利用不足的问题。特别是,他们采用实例级关联,也即是使用RoI提取的特征来增强目标帧的实例特征,从而忽略帧之间的空间关系。为了使上下文特征多样化,一些工作着力于如何从更远的上下文中挖掘信息。然而,作为人类视觉的常识,来自附近时间窗口的信息足以在大多数场景中进行增强检测。具体来说,在将模糊对象与目标帧区分开来时,我们通常指的是在时间上在目标帧附近滑动的帧,而不是观察整个视频。这样一来,如何充分利用上下文帧的信息,而不是扩大上下文帧的范围,应该受到重视。
在本文中,我们提出 PTSEFormer 来解决上述问题。受 DETR启发,PTSEFormer 使用Transformer作为基本结构来避免复杂的后处理(如Seq-NMS, Viterbi, Tublet-Rescore)。与通过注意力机制单次融合目标帧和上下文帧的特征并在RoIs提取的特征上进行实例级关联相比,PTSEFormer通过一种渐进式的方法,既关注时间信息又关注帧之间的空间转移关系。
具体来说,Temporal Feature Aggregation Module旨在引入时间信息,以增强目标帧的特征,在所有上下文帧中对相同对象具有不同的视角。Spatial Transition Awareness Module设计用于估计目标帧和每个上下文帧之间对象的位置转换,通过帧到帧的空间信息增强目标特征。为了在transformer解码器上建立一个平衡的相关模型,我们进一步提出了门控相关模型,该模型考虑了由残差连接层引起的不平衡,并添加了一个门控来修复它。
此外,作为 DETR 的一项重要设计,Object Queries包含从训练数据中学习到的固有对象位置分布,并且在推断过程中是固定的。我们提出了Query Assembling Module(QAM)来直接从上下文中回归Object Queries。这是因为从相邻的上下文帧推断位置比从训练数据决定的固定参数推断位置更合理,QAM通过时间传达隐含的位置信息。我们在 ImageNet VID 数据集上进行了广泛的实验,与之前的端到端最先进的方法相比,在 mAP指标上实现了4.9%的绝对提升,显示了我们方法的有效性。
方法
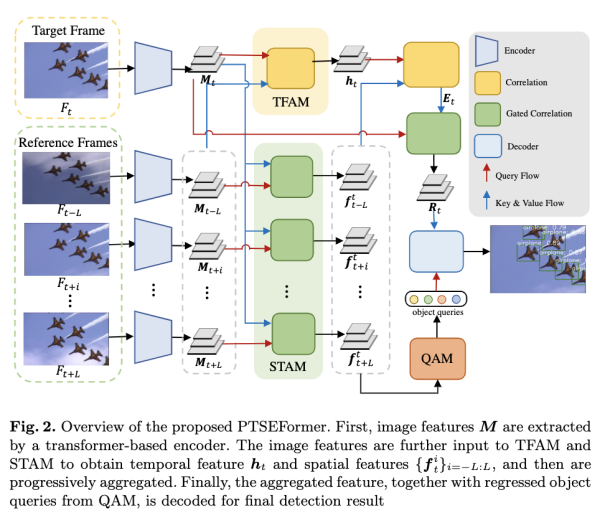
提出 STAM 来学习对象从上下文帧 t+i 到目标帧 t 的相对位置转换。由于在 VOD 任务中没有目标id标注,因此 t+i 和 t 帧的关系的学习并非易事。一个直接的想法是使用attention机制 来建模 t+i 和 t 之间的空间转换关系。然而 Q 和 V 上的不平衡权重使得在两帧匹配对象是不可行的。具体来说,Q 和 V 的权重分别为 1 和 softmax。当尺寸较大时,权重远小于1,导致对 Q 和 V 的关注严重不平衡。通常,这种架构用于不同空间和维度的特征之间的关联,这自然需要有偏向的关注。但是在视频目标检测任务中,我们认为不平衡的注意会损害效果。
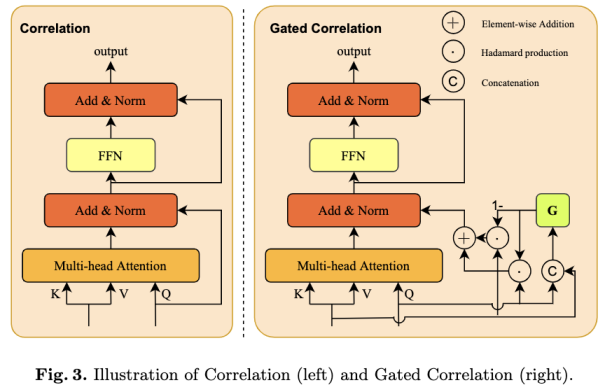
为了解决上述限制并受到 GRU 门控设计的启发,我们设计了一个 Gated Correlation operation。通过在解码器的残差连接中添加一个门控,我们可以改变 Q 之前的权重。此外,为了获得让权重与输入 Q 和 V 有关,控制权重必须由 Q 和 K 决定。因此,我们通过一个全连接层传递 Q 和 K 以获得权重。
在原始的 DETR 中,设计了一组可学习的嵌入向量来学习不同目标的位置分布。对于每个object query,解码器解码一个 bounding box。遵循相同的原则,我们使用解码器解码我们的增强特征。但是,仍然存在一个问题,即原始object query随着时间的推移是固定的,无法从上下文中受益。因此,我们提出了QAM,以使object query通过时间传达位置分布信息。
实验
SOTA 实验
我们首先把我们的 PTSEFomer 与几种最先进的方法进行比较。如表所示,我们将这些方法按其主干网络分为两类。我们在 mAP 上实现了比现有方法更高的性能,并且具有很大的优势。当然,更大的主干网络提高了所有方法的性能,包括我们的方法。
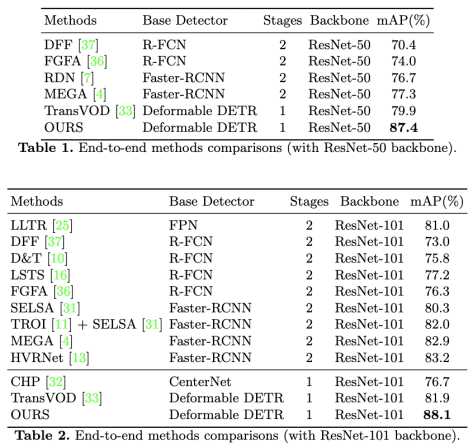
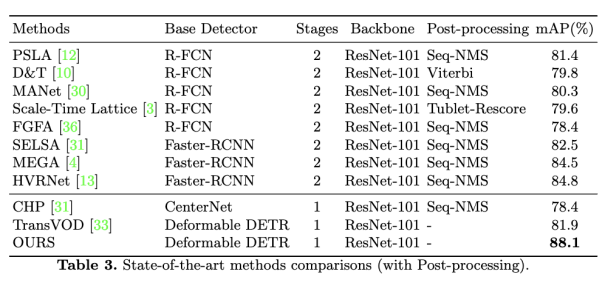
我们还将我们的 PTSEFormer 与几种最先进的方法 + 后处理程序进行了比较。后处理在许多 VOD 方法中被证明是有用的,尤其是在那些基于锚点检测器的方法中。实际上,大多数现有方法都有其带有后处理的版本以提高性能。例如,使用最广泛的后处理 Seq-NMS,通过序列进行 NMS 操作,将 mAP 提升 1%-2%。然而,这些后处理过程虽然被证明是有效的,但需要额外的计算。我们声明,即使我们不采用后处理,我们的方法仍然在 mAP 上获得了最好的分数。
消融实验
我们也做了各个组件的消融实验来证明各模块的有效性。


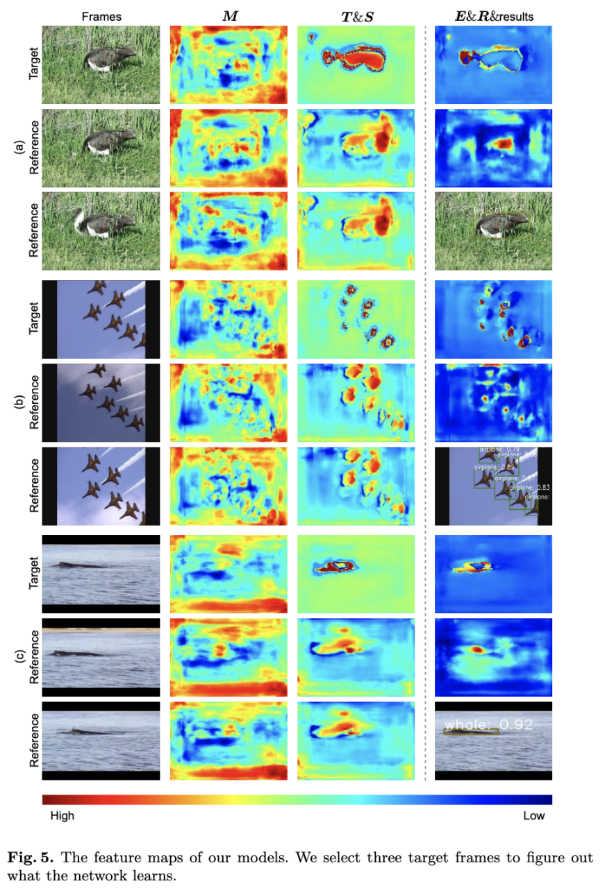
可视化
特征图可视化以及结果可视化。

结论
在这项工作中,我们提出了一种针对视频目标检测的渐进式时空增强 Transformer。基于单阶段目标检测器 DETR,我们通过引入渐进特征聚合的适当设计来提高性能。时间信息和空间信息被证明有助于提高检测器对图像恶化的鲁棒性。我们还在公共数据集 ImageNet VID 上进行了广泛的实验,以验证我们方法的有效性。我们希望我们的工作能够为 VOD 应用无锚方法的研究提供启示。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。