
本文基于经典的端到端图像编码框架,着手于编码器和解码器的优化,提出了 1. 融合多尺度特征的反投影方法;2. 对输入图像高频、低频信息的分割方法,以及对两者潜在表示的双重注意力融合机制。
论文标题:Neural Image Compression via Attentional Multi-scale Back Projection and Frequency Decomposition
发表会议:ICCV 2021
作者:Ge Gao, Pei You, Rong Pan, Shunyuan Han, Yuanyuan Zhang, Yuchao Dai, Hojae Lee
论文链接:https://openaccess.thecvf.com/content/ICCV2021/papers/Gao_Neural_Image_Compression_via_Attentional_Multi-Scale_Back_Projection_and_Frequency_ICCV_2021_paper.pdf
内容整理:陈予诺
近年来,深度图像压缩成为计算机视觉领域一个快速发展的课题。其中最先进的方法表现出比传统方法更好的压缩性能。尽管已经取得了巨大的进步,但当前方法保留精细空间细节从而实现最优重构的能力仍然不足,这在低码率下更加明显。我们在解决这个问题上有三个贡献。首先,我们设计了一种新的反投影方法,该方法通过注意力机制和多尺度特征融合,增强了表征能力。我们的反投影方法通过对high-level、low-level属性的注意力机制和多尺度特征融合的反馈联系来重新校准当前的估计值。第二,我们对输入图像进行频率分解,并分别处理不同的频率分量。之后我们采用一个双重注意模块将其潜在特征重新组合起来,使感兴趣的区域内的细节得到充分处理。第三,我们提出了一个新的训练方案,以减少潜在特征的残差。实验结果表明,我们的模型分别在Kodak和CLIC2020数据集上,相比最新的编码标准Versatile Video Coding (VVC),高出10.32%和4.12%的BD-rate(使用PSNR进行计算)。这证明了我们的方法在保留和弥补空间信息、提高压缩质量方面的有效性。
方法
总体架构
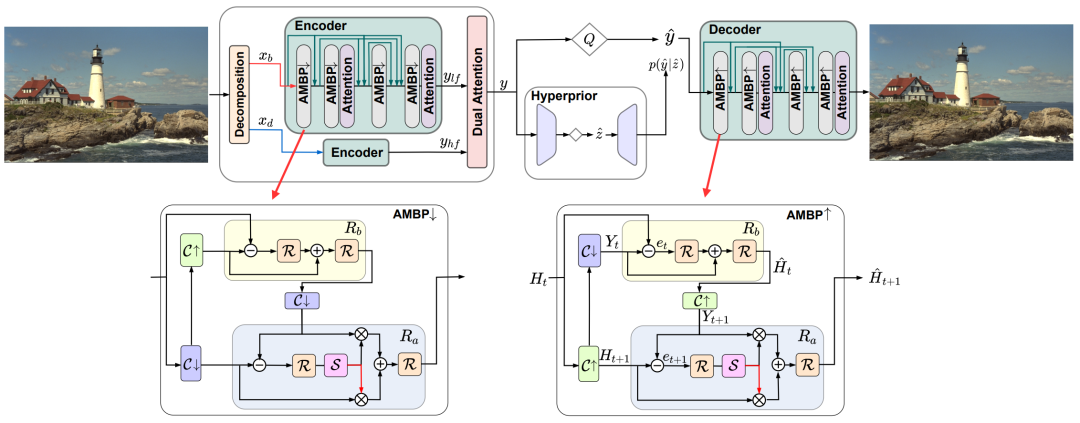


下文重点解析分频模块 Decomposition、双重注意力模块 Dual attention和多尺度反投影模块 AMBP。
分频模块
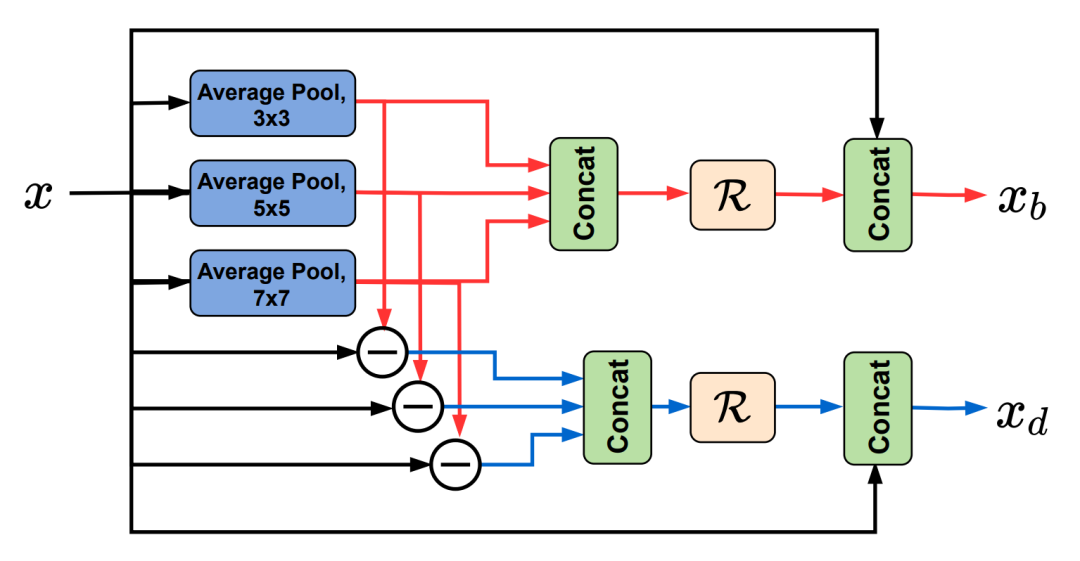
分频模块提取输入图像的低频信息。方法是做平均池化,然后经过三种不同卷积核大小的卷积。高频信息则通过用原始信息减去低频信息的方式获取。将获得的三组高低频信息分别Concat到一起后经过一个Residual Block,再与原始信息 Concat一次,即获得最终的高频、低频信息和
双重注意力机制模块
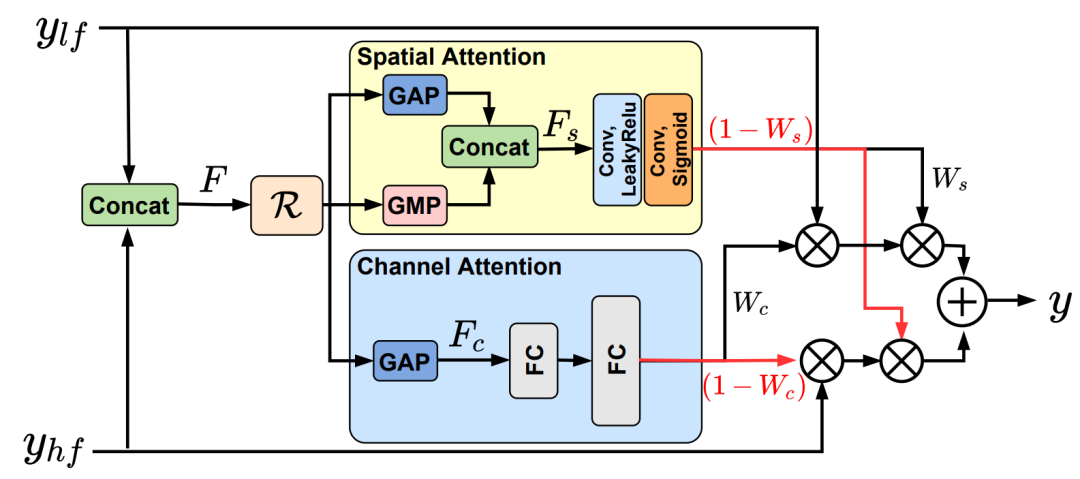
图片数据在送入编码器之前被拆分为高频信息和低频信息,经过编码后需要重新合并。此处采用Spatial和Channel的双重注意力机制。这种计算通道注意力和空间注意力的方法是一种经典的注意力机制,最早出现于 “CBAM: Convolutional Block Attention Module” 一文。
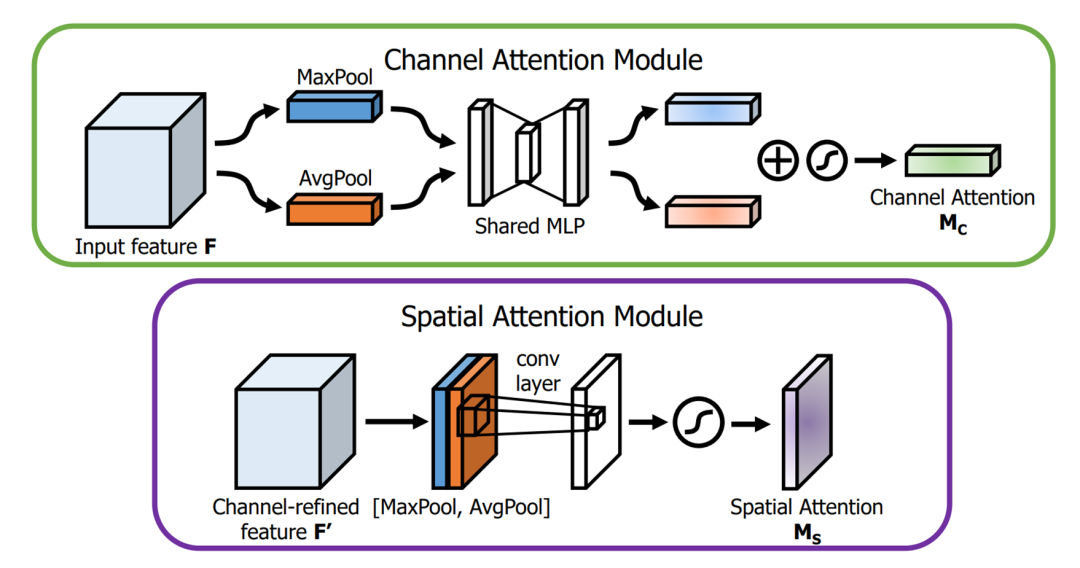
Channel Attention:
- 我们对输入特征F的每一个Channel,在H x W上分别进行全局平均池化和全局最大池化;
- 将平均池化和最大池化的结果送入共享的全连接层;
- 对全连接层的输出结果进行相加,再经过sigmoid激活函数,获得逐通道的权重;
- 用该权重和原feature的通道对应相乘。
Spatial Attention:
- 我们对输入特征F的所有Channel使用全局平均池化和全局最大池化获得两个H x W的张量;
- 将两者Concat堆叠到一起后,使用一次通道数为1的卷积调整通道数;
- 使用sigmoid激活函数获得H x W的每一个特征点的权值;
- 用该权重和原本的feature在H x W内对应相乘。
上述为CBAM中的双重注意力机制。本文的双重注意力机制非常类似于CBAM,其中GAP和GMP分别对应全局平均池化和全局最大池化。

多尺度反投影
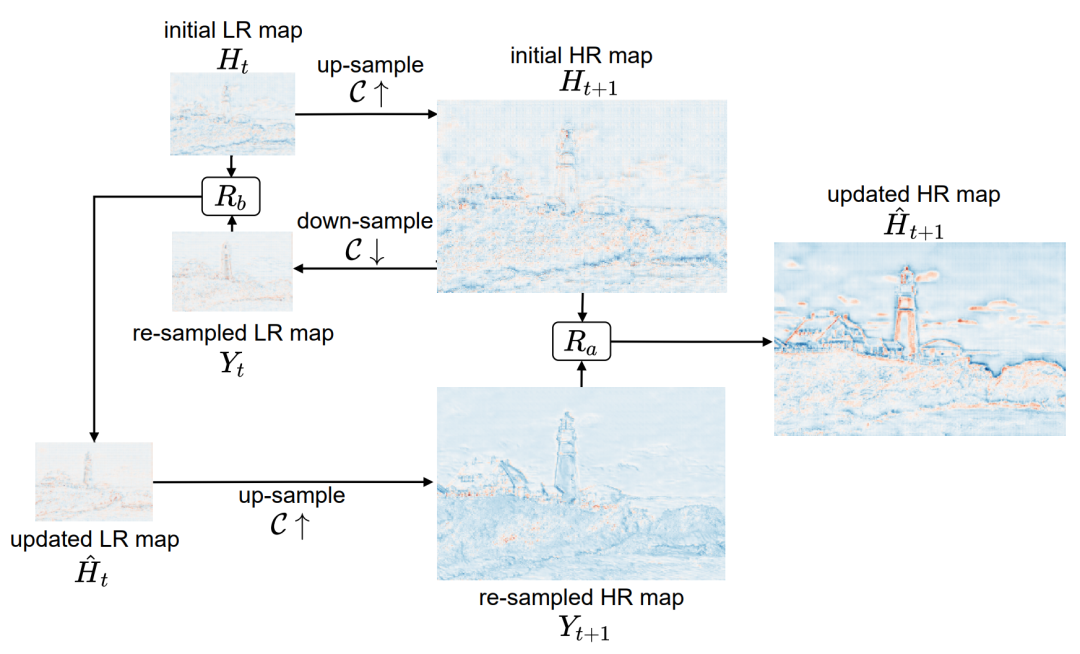
这个模块的想法来自于超分辨率网络 DBPN,思路是不断利用反馈残差来细化高分辨率图像。
、是两个Residual fusion block,其结构如下图所示。图6 、和、
其中S是一个Channel attention module。
用upsample举例解释反投影的过程:使用原始的低分辨率图像,先上采样再下采样,然后和原图做残差融合,再上采样和第一次上采样的图像融合,得到最终的高分辨率图像。
混合训练机制
类似于 Channel-wise autoregressive entropy models for learned image compression 一文,本文采用noisy relaxation来近似量化,并通过一个额外的rounding loss 来微调解码器,此处指解码器第一个模块提炼的潜在信息。本文发现,通过解码原始latent,而非量化后的latent,可以有效提高重建质量。所以本文在损失函数中增加约束,迫使网络在优化的过程中更加关注如何减小 latent 的 rounding residual。
这一策略的损失函数为
为
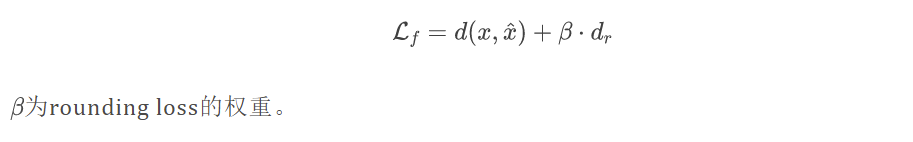
实验
消融实验
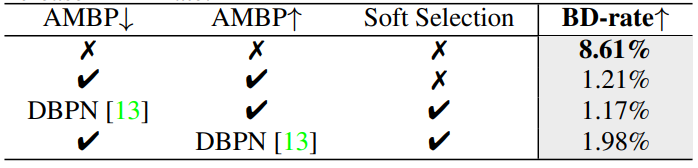
此处消融实验baseline为本文模型,对比指标为BD-rate的上升百分比。
四个实验分别为 去掉编码器的AMBP模块和解码器的AMBP模块、去掉Soft Selection(指里面的channel attention)、使用原始DBPN替换修改后的反投影模块AMBP。
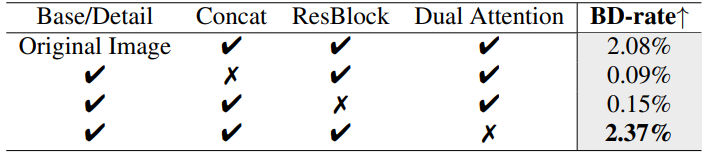
此处消融实验主要关于原始图像和高低频信息的处理。baseline仍然为本文模型,对比指标为BD-rate的上升百分比。
第一个实验为使用原始图像直接输入,替代分频信息。第二个实验为去掉把原始图像和分离的高低频信息concat的操作。第三个实验为去掉Decomposition中的ResBlock。第四个实验为去掉Dual Attention模块,使用四个卷积层堆叠替代。
通过对比实验,可以证明本文模型中各个部分和细节设计的有效性
模型性能对比实验

此处 Ref 指代 Learned image compression with discretized gaussian mixture likelihoods and attention modules
和 Reference model 相比,本文的模型参数量翻倍,编解码时间分别为2.57倍和1.64倍。
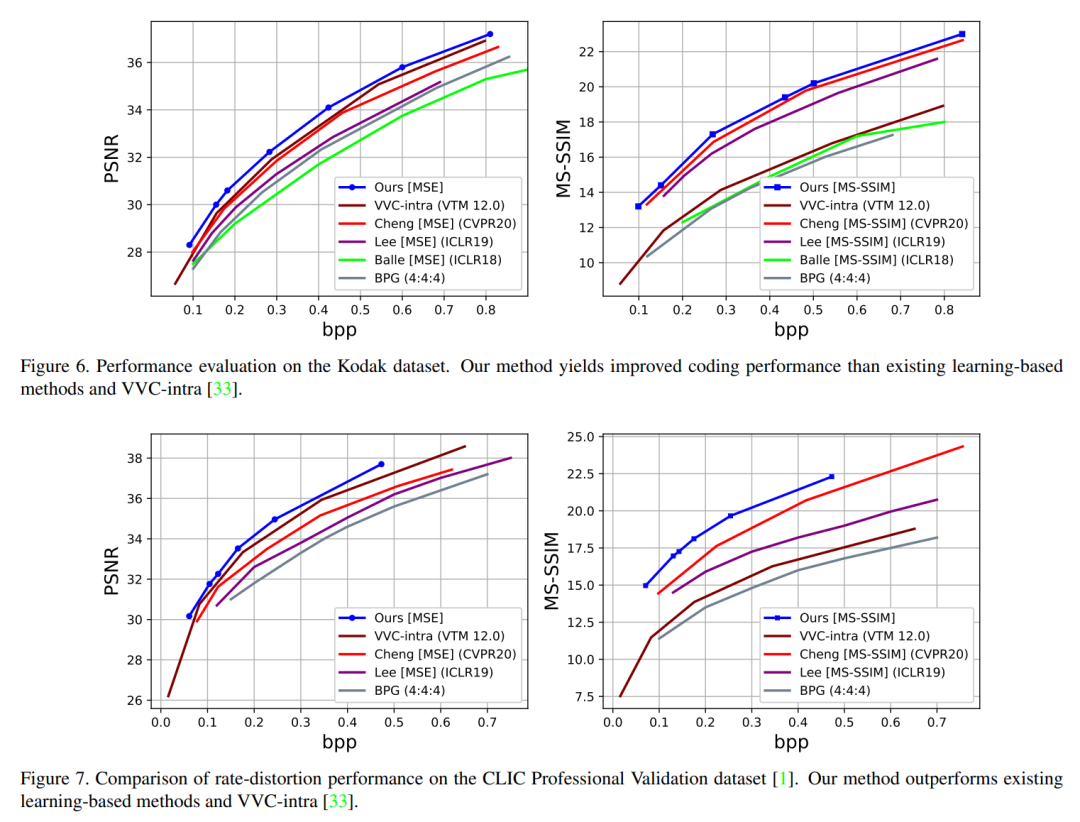
RD 曲线对比,本文模型在 Kodak 和 CLIC 数据集上都表现出SOTA性能(不过参与对比的模型有限)
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。