
1、引言
对于一些需要音频分离的场景,比如基于声音对象提取的虚拟全景声研究、K歌伴奏的提取等,一直是较难实现的行业痛点。
音轨分离,即音乐源分离 (MSS) ,是将混合音频分离成若干单个源的任务,例如人声、伴奏以及鼓、钢琴、贝斯等不同乐器。推广开来,该技术并不局限于音乐,是可以对任意音频均能实现指定声源(音轨)的分离或提取的任务。
对于传统的音轨分离方式:AU等专业音频编辑软件也只能提取部分音轨,无法实现任意音源(声音对象)的提取;到相关网站寻找原音轨资源,局限太大无法推广。
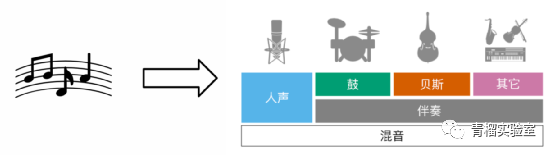

2、音轨分离技术简介
音轨分离技术作为音频的一项基础能力,其一般直接应用于K歌、音效场景。现阶段公开方法较少,且由于数据集限制仅能分离指定少量乐器,应用场景有限。
当前,基于深度神经网络的方法已成功应用于音乐源分离。基于深度学习模型的整体流程大致分为以下四个步骤:
(1)数据收集:由于音轨分离任务对于数据质量的高要求,业界可以直接使用的相关数据集较少,最为常见的是musdb18数据集,包含150首不同风格的全音轨歌曲。
(2)预处理:包括一些对于音频常见的处理,例如数据划分与规整,提取频谱,序列向量化等。
(3)模型构建:即算法选型与设计,应用于该任务常见的有LSTM,DRNN,UNET等。
(4)模型训练与预测:遵循神经网络的常规流程。

以基于频域的方法-Spleeter为例。Spleeter训练流程与预测流程,如下图所示:
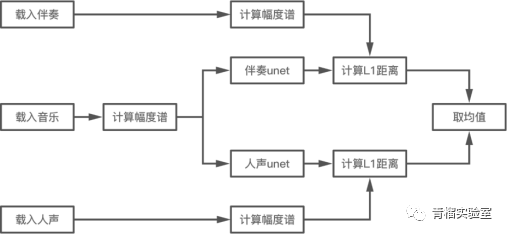
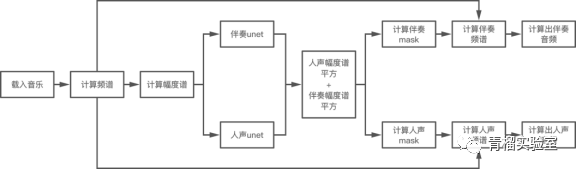
基于深度神经网络的方法,通常用于学习从混合声谱到一组源声谱的映射,所有声谱图都只有幅度。但是,这种方法会受到一定的限制:
1)不正确的相位重构降低了性能;
2)将掩码的幅度限制在 0 和 1 之间,而我们平时观察到有 22% 的时频 bin 的理想比率掩码值超过 1;
3) 在深架构上的潜力尚未得到充分探索。
基于以上结论,本文采用优化模型-基于残差UNet架构的音轨分离。
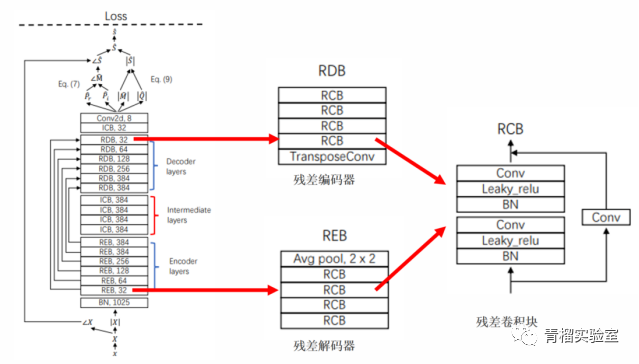
基于残差UNet架构的音轨分离模型将音乐源分离的幅度和相位估计进行解耦,引入了一个包含数百层的深度残差 UNet。在构建具有数百层的残差 UNet 时,使用残差编码器块 (REB) 和残差解码器块 (RDB) 来增加网络深度。上图显示了残差 UNet 架构,其中使用了 6 个 REB 和 6 个 RDB。每个 REB 由 4 个残差卷积块(RCB)组成。每个 RCB 由两个卷积层组成,卷积核大小为 3×3。在 RCB 的输入和输出之间添加了一个快捷连接(shortcut connection)。在遵循预作用残差网络配置的卷积层之前,应用批量归一化和具有 0.01 负斜率的 leaky ReLU 非线性函数。在每个 REB 之后应用 2 × 2 平均池化层以减小特征图大小。每个 REB 由 8 个卷积层组成。
解码器 (RDB) 中的块与编码器 (REB) 中的块对称。每个 RDB 由一个转置(transposed)卷积层组成,其卷积核大小为 3 × 3,stride 为 2 × 2 ,用来对特征图进行上采样,然后是四个 RCB。每个 RDB 由 9 个卷积层组成,包括 8 个卷积层和 1 个转置卷积层。为了进一步提高残差 UNet 的表示能力,该研究在 REB 和 RDB 之间引入了中间卷积块 (ICB)。基于残差UNet架构的音轨分离模型使用 4 个 ICB,其中每个 ICB 由 8 个卷积层组成。
与以往方法进行音源分离效果的对比结果:
| 人声 | 贝斯 | 鼓声 | 其它 | 伴奏 | |
| Open-Unmix | 6.32 | 5.23 | 5.73 | 4.02 | – |
| Wave-U-Net | 3.25 | 3.21 | 4.22 | 2.25 | – |
| Demucs | 6.29 | 5.83 | 6.08 | 4.12 | – |
| Conv-TasNet | 6.81 | 5.66 | 6.08 | 4.37 | – |
| Spleeter | 6.86 | 5.51 | 6.71 | 4.55 | |
| D3Net | 7.24 | 5.25 | 7.01 | 4.53 | 13.52 |
| ResUNetDecouple+ | 8.98 | 6.04 | 6.62 | 5.29 | 16.63 |
表格第一行显示了 Open-Unmix 的性能,它由三个双向长短期记忆层组成,实现了 6.32 dB 的人声 SDR。第二行显示,在时域中训练的 Wave-U-Net 系统实现的 SDR 略低于其他时频域系统。第三行之后显示了 Demucs、Conv-TasNet、Spleeter 和 D3Net 的结果。
在比较的方法中,D3Net 分别实现了 7.24 dB 和 7.01 dB 的最佳人声和鼓声 SDR。Demucs 达到了 5.83 dB 的最佳低音 SDR,而 Spleeter 在之前的研究中达到了 4.55 dB 的其他最佳 SDR。
如表格最后一行所示,ResUNetDecouple 系统在分离人声、贝斯、其他和伴奏方面明显优于其他方法。
3、结语
基于残差UNet架构的音轨分离技术的应用,将更有效地实现指定音源的分离,以提取特定声音对象,包括人声、伴奏、乐器以及枪声、赛车声等,打造沉浸式音频体验。
作者:相迎迎 | 来源:青榴实验室
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。