
视觉语言模型本地化字幕面临的挑战
描述图像或视频中的特定区域一直是视觉语言建模领域的一项挑战。虽然通用视觉语言模型 (VLM) 在生成全局描述方面表现良好,但它们往往无法生成详细的、特定区域的描述。这些局限性在视频数据中尤为明显,因为模型必须考虑时间动态。主要障碍包括:视觉特征提取过程中细粒度细节的丢失、针对区域描述的带注释数据集不足,以及由于参考描述不完整而导致评估基准对准确输出产生不利影响。
Describe Anything 3B:专为本地化描述而定制的模型
NVIDIA 的这项 AI 成果展示了 Describe Anything 3B (DAM-3B),这是一个多模态大型语言模型,专为在图像和视频中生成详细的本地化字幕而设计。配合 DAM-3B-Video,该系统可以通过点、边界框、涂鸦或蒙版等指定区域的方式接受输入,并生成基于上下文的描述性文本。它兼容静态图像和动态视频输入,并且这些模型已通过 Hugging Face 公开发布。


核心架构组件和模型设计
DAM-3B 包含两项主要创新:焦点提示和局部视觉主干,并采用门控交叉注意力机制进行增强。焦点提示将完整图像与目标区域的高分辨率裁剪图融合,既保留了区域细节,又保留了更广泛的上下文。该双视图输入由局部视觉主干处理,该主干嵌入图像和掩码输入,并应用交叉注意力机制融合全局特征和焦点特征,然后将其传递给大型语言模型。这些机制的集成不会增加 token 的长度,从而保持了计算效率。
DAM-3B-Video 通过对帧内区域掩码进行编码并跨时间进行积分,将此架构扩展到时间序列。即使在存在遮挡或运动的情况下,也能为视频生成特定区域的描述。

训练数据策略和评估基准
为了克服数据稀缺问题,NVIDIA 开发了 DLC-SDP 流程——一种半监督数据生成策略。这个两阶段流程利用分割数据集和未标记的网络规模图像,整理出一个包含 150 万个局部化示例的训练语料库。区域描述通过自训练方法进行细化,从而生成高质量的字幕。
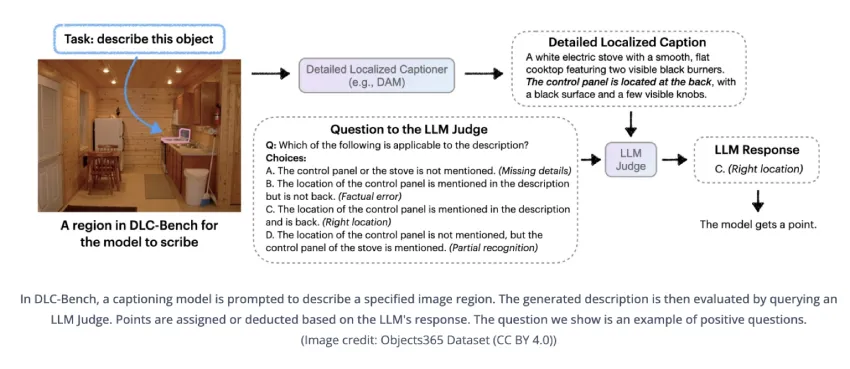
为了进行评估,团队引入了 DLC-Bench,它基于属性级别的正确性来评估描述质量,而不是与参考字幕进行严格的比较。DAM-3B 在七个基准测试中取得了领先的性能,超越了 GPT-4o 和 VideoRefer 等基线模型。它在关键词级别(LVIS、PACO)、短语级别(Flickr30k 实体)和多句本地化字幕(Ref-L4、HC-STVG)方面都表现出色。在 DLC-Bench 上,DAM-3B 的平均准确率达到 67.3%,在细节和精度方面均超越其他模型。
结论
Describe Anything 3B 通过将情境感知架构与可扩展的高质量数据流水线相结合,解决了区域特定字幕长期以来存在的局限性。该模型能够描述图像和视频中的本地化内容,广泛应用于辅助功能工具、机器人技术和视频内容分析等领域。通过此版本,NVIDIA 为未来研究提供了强大且可重复的基准,并为下一代多模态 AI 系统设定了精细的技术方向。
资料
- 论文:https://arxiv.org/abs/2504.16072
- 项目:https://describe-anything.github.io/
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/jishu/57669.html