
近几年,空间音频从“更高质量到音频”走向“可被理解与生成的三维声场”。它不只是把声音变“立体”,而是让系统理解声源的方位、距离、运动,并能按需生成。在 AR/VR、影视、游戏与交互内容的牵引下,研究重心也从传统的信号级处理迈向多模态、可控生成与语义级推理。近年来空间音频技术发展迅猛,研究成果层出不穷,但却一直缺乏全面深入的综述文章对领域进行总结。
近期,来自浙江大学的学者系统梳理了空间音频的表示形式 、 理解任务 、 生成任务、数据集与评测的全链路,深入探讨了空间音频的发展现状和最新进展,形成了综述文章 ASAudio。


论文标题:
ASAudio: A Survey of Advanced Spatial Audio Research
论文地址:
https://arxiv.org/abs/2508.10924
项目仓库:
https://github.com/dieKarotte/ASAudio
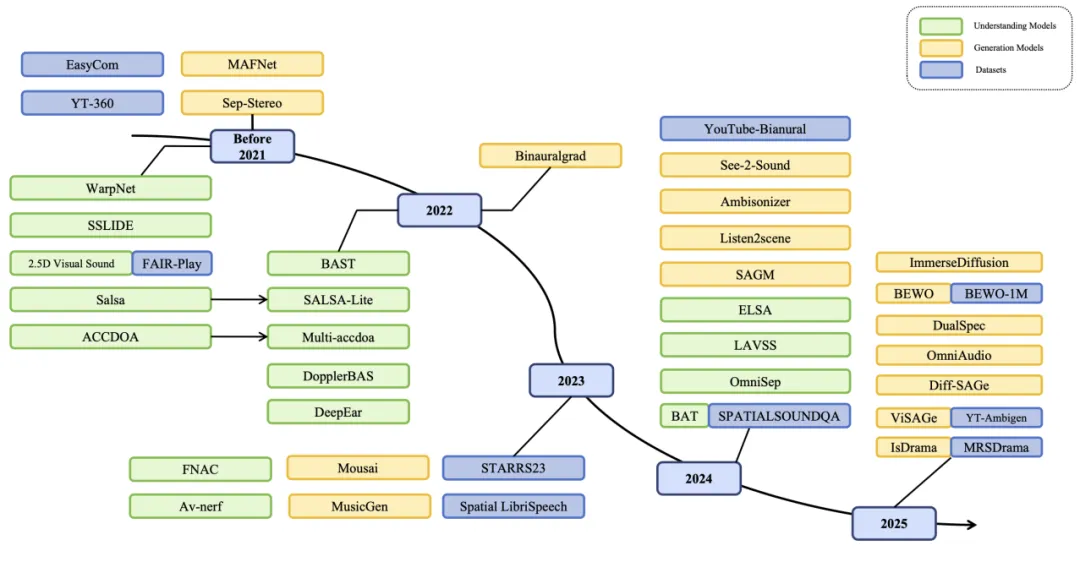
该综述将当前空间音频研究版图总结为以下7类:
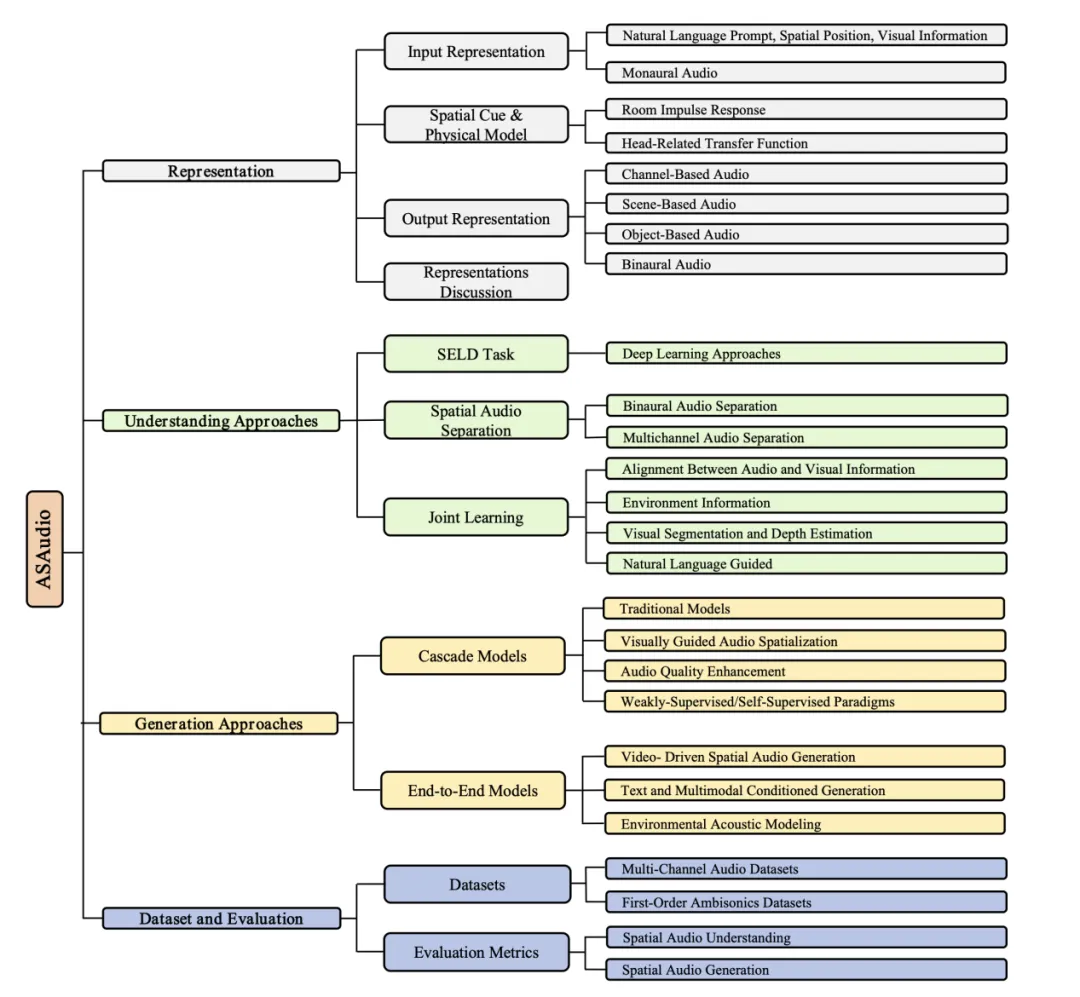
1. 输入表示(Input Representation):把单声道音频、文本、视觉、空间坐标作为输入轴,统一梳理其承载的语义/声学/几何信息与常见预处理(如文本对齐、视频几何提取、坐标系/朝向/速度建模)。这一步决定了后续理解与生成能接住怎样的条件与约束。
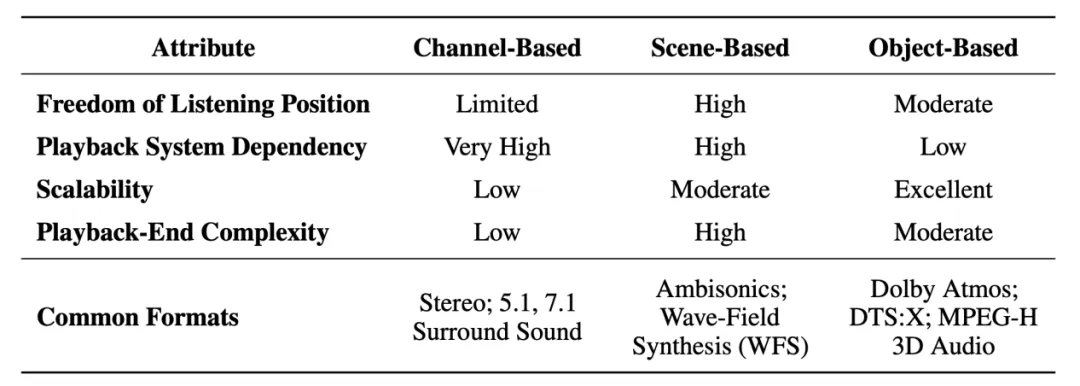
2. 输出表示(Output Representation):介绍通道表示(Stereo/5.1/7.1)、场景表示(Ambisonics/WFS)与基于对象的表示(Atmos 等)三种空间音频表示范式,并介绍最终连接听觉端的双耳音频形式。
3. 物理建模与空间线索(RIR/HRTF ):RIR 负责“房间如何回响”,HRTF 负责“人如何听到”。个性化 HRTF与视觉/几何驱动的房间声场估计是提升空间真实感的关键路径。
4. 理解任务(Understanding Tasks):覆盖SELD(事件定位与检测)、分离(Separation)、联合学习以及跨模态对齐(语音-视频/语音-文本)。
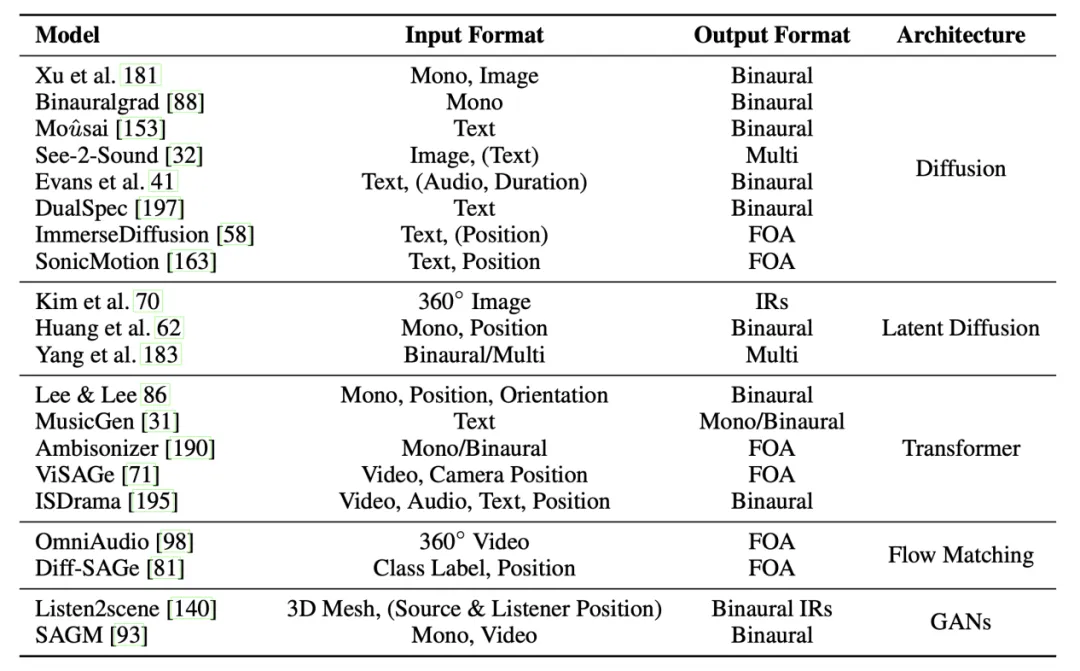
5. 生成范式(Generation Tasks):从传统 DSP 空间化与“视频/文本引导的上混(Mono→Binaural/FOA/多通道)”,到扩散(Diffusion)/流匹配(Flow Matching)/Transformer/VAE 等端到端生成。尤其ImmerseDiffusion、Diff-SAGe等在双耳/多通道/FOA的空间真实感与音质上带来跃升。
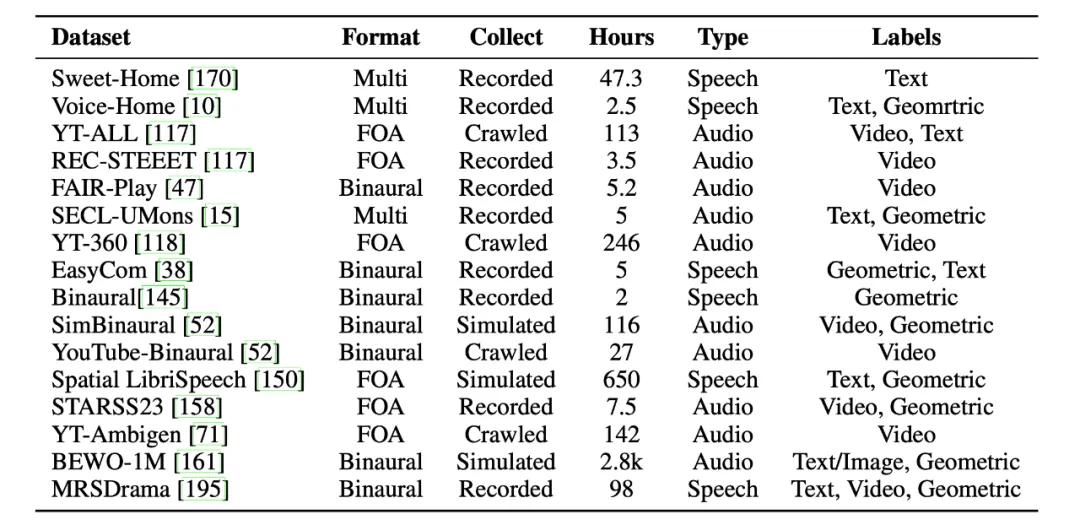
6. 数据集与数据生成(Datasets):真实采集与仿真合成并举。近年的代表数据/基准包括 MRSDrama、BEWO-1M、YT-Ambigen、STARS23、Spatial-LibriSpeech 等;不少理解/生成工作自带数据/基准推动口径统一。
7. 评测标准(Evaluation Metrics):理解端常用事件 F1/ER、DOA 误差、SDR/SIR 等;生成端在波形/谱域误差、MRSTFT与感知类PESQ/MOS/FAD/KL/CLAP之外,强调用强度向量(Intensity Vector)反演方位角/仰角/距离与球面角误差来量化“空间感”。
1. 输入表示
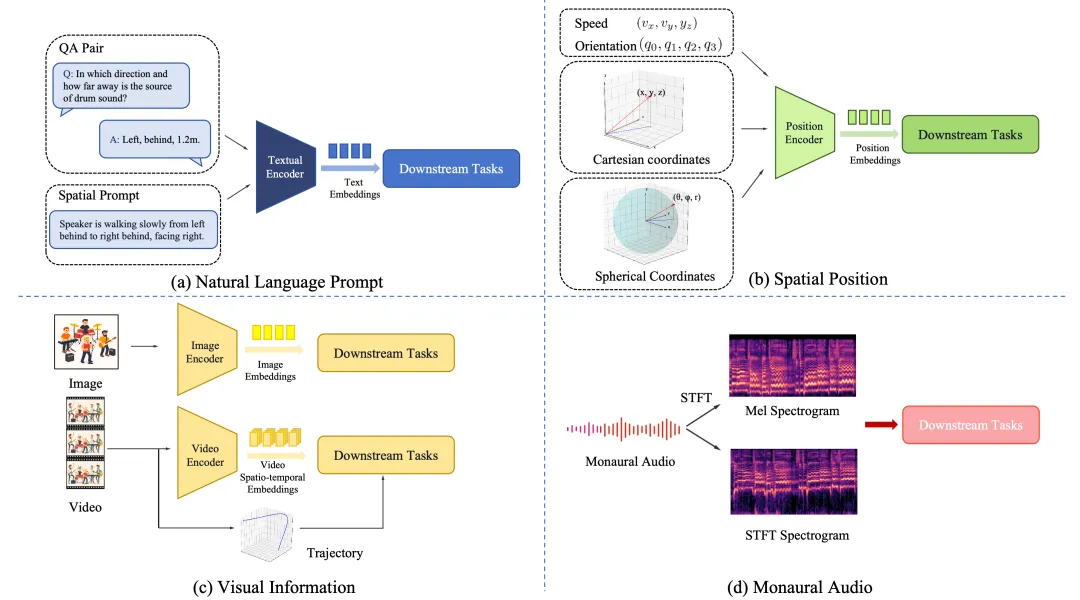
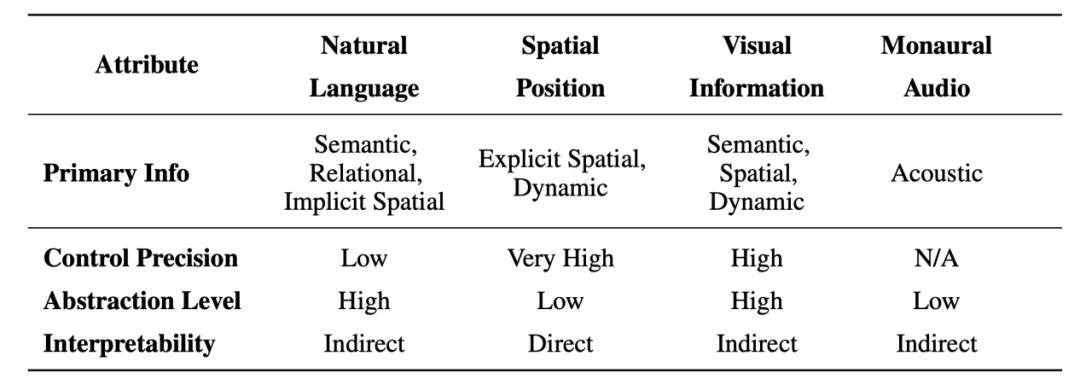
空间音频任务的输入表示是多样的,由于空间音频包含语义,声学和空间的信息,因此任务的输入也针对这几个部分的信息进行设计。
例如,对于声学的部分,通常有单声道音频提示作为输入,可以提供音色信息等声学特征。
对于语义的部分,通常有文本提示作为输入,可以提供音频的语义信息。
对于空间的部分,通常有空间位置提示,形式可能是自然语言的文本描述、图片或者视频形式的视觉信息或者是空间位置的坐标信息,包括直角坐标、球坐标等形式。
这些输入信息可以是单独的,也可以是组合的,通常会有不同的组合方式。
2. 输出表示
空间音频任务的输出表示形式同样多样,通常包括双耳音频、立体声、多声道音频、Ambisonics等。
我们分三类对输出表示形式进行了介绍:
基于声道的音频表示信号,例如5.1或7.1声道音频,通过在录制时设定的声道和扬声器的位置映射,可以在播放的时候根据扬声器位置映射奖相应的声道输入到相应的扬声器上进行播放;
基于场景的音频表示信号,例如FOA(First Order Ambisonics)音频,通过球面谐波变换表示整个三维空间的声音场信息,在播放时通过HOA(Higher Order Ambisonics)解码器将其转换为多声道音频信号进行播放;
基于物体对象的音频表示信号,例如杜比全景声(Dolby Atmos),通过记录每一个声音对象的音频特性和声源位置,在播放时通过对所有的音频对象进行渲染播放。
这些重放的音频格式可以通过耳机、扬声器或其他音频设备进行播放,提供身临其境的听觉体验。
3. 物理建模与空间线索
空间音频的一个基本方面是对声音在三维空间中如何传播和被感知进行精确建模。在这一背景下,两个关键概念是房间脉冲响应(RIR)和头部相关传输函数(HRTF)。
在我们假设声学环境是线性时不变(Linear and Time-Invariant, LTI)系统的前提下,房间脉冲响应(Room Impulse Response, RIR)完整地表征了从声源到接收器之间所有声学路径的特性。RIR可以被分解为三个主要部分:直达声、早期反射声和晚期混响。一旦获得了RIR,通过卷积运算,就可以精确预测任何“干”信号在该房间、该位置听起来的效果,因此,RIR是连接虚拟声学与现实世界的桥梁。
头相关传输函数(Head-Related Transfer Function, HRTF)是实现高保真双耳空间音频体验的基石,它本质上描述了一个声音从空间中某一点传播至听者双耳鼓膜处所经历的声学变换过程。这一过程可被精确地建模为一个线性时不变(Linear Time-Invariant, LTI)系统,其物理根源在于声波与听者独特的身体结构,包括头部、躯干以及尤其是构造复杂的耳廓(pinnae)之间发生的复杂的衍射、反射和声影蔽效应。由于HRTF直接取决于个体独一无二的头型、耳廓形态及身材尺寸等生理人类学特征,每个听者耳廓所产生的关键谱峰和谱谷的频率位置与深度都是独一无二的,这构成了HRTF个性化问题存在的根本前提。
4. 理解任务
传统的音频理解任务包括一系列子任务,如语音识别、说话人识别、事件检测等。理解任务主要与其他模态的共同学习相关联,包括基本的音频理解,文本到音频理解,视觉到音频理解等等。
拓展到空间音频的理解任务,由于除了语音本身的语义特征和声学特征之外,还额外包含了空间特征,因此对于空间音频的理解任务也有很多扩展,
除了单纯的音频理解任务从单声道转化为以双耳、多声道或者ambisonics的形式进行理解之外,空间音频理解任务还包括了以下的内容。
在拥有更多声道信息后,声源检测和定位任务(SELD)变得复杂,声道之间蕴含的空间信息也可以被利用来进行SELD任务的相关处理。事件检测的位置不仅仅局限于检测声音来自画面内或者画外,还可以拓展到360度或者全景的音频检测。
空间音频事件定位的任务也随之拓展。双耳声道的音频信号让我们可以考虑现实中的双耳效果,模拟真实的人耳听觉,声道的差异让定位任务和声源分离任务得以更好的进行。
空间音频追求真实的声音建模,因此模拟真实声场的声学特征也成为了空间音频理解任务的一个重要组成部分,这些工作研究了场景声学特征一致性的建模。
在一些视觉辅助的空间音频理解任务中,视觉信息中蕴含的深度信息和场景信息也被作为一种监督手段。视频信息和空间音频的对齐和联合学习为生成任务提供了更好的条件。
一些对于音视频的联合学习任务可以理解给定的场景信息,并进一步生成新位置的音视频信息,是声源定位、分离、理解的综合任务。
在自然生活场景中,空间信息也往往是以自然语言的形式进行描述的,因此加入LLMs的理解任务也成为了一个重要的研究方向。
还有一些相关的编码器工作,针对双耳音频,在保留空间信息的同时,进行音频的编码和解码任务。
5. 生成范式
早在1881年,Ader首先使用了一对麦克风和电话听筒传输声音信号,进行了首次空间(立体声)声音演示。较早时期的空间音频生成方法主要基于传统的数字信号处理,单独录制每个声源的音频,再通过各种音频处理技巧结合预设的场景设置和空间信息对其进行混合处理。
这种方法的缺点在于需要大量的音频数据和场景信息,且难以适应不同的场景和声源变化。因此,将单声道的音频进行空间化一直是一个热门的研究方向。
另一方面,生成模型的飞速发展推动了空间音频生成技术的进步,端到端的空间音频生成方法也在不断发展,让我们能够生成更高的质量的空间音频。
作为一个相对更窄的生成领域,空间音乐的生成的研究早于音频生成的研究,在更多监督和输入的情况下实现了立体声的音乐生成。
本节介绍了空间音频生成方面的最新进展,包括传统的DSP方法、近期的深度学习架构的空间音频生成,并根据模型架构分类介绍。
6. 数据集与评测标准
空间音频数据存在多种格式,每种格式都体现出不同的特征,并针对特定任务进行了定制。本节深入分析了现有的空间音频数据集,阐述数据收集和处理的多种方法,并解释这些要素如何助力对空间音频的理解。
由于录音设备和应用场景的不同,空间音频数据有多种格式,通常还会附带其他模态的标注和辅助数据。此外,由于录制空间音频通常成本高昂且耗费资源,许多现有方法借助模拟系统,从现有的单声道音频数据集中生成合成数据。一些数据集还包含从公开视频平台爬取的真实空间音频。本节重点介绍了多种空间音频格式(包括多声道音频、一阶环绕声和双耳音频)相关的采集和处理方法,既有录制的,也有模拟的。
7. 总结展望
鉴于沉浸式音频的快速发展,本文对空间音频领域进行了全面且系统的综述,填补了现有文献中的一个显著空白。我们的综述通过从几个关键方面对近期研究成果进行梳理,为该领域提供了结构化的概述。首先,我们详细阐述了构成空间音频任务基础的各种输入和输出表示形式。接着,综述的核心聚焦于两大主要研究范式:空间音频理解和空间音频生成。在理解领域,我们探讨了空间音频分析的方法,包括声音事件检测、定位、声源分离以及联合学习。在生成领域,我们考察了空间音频合成技术,并按架构对生成模型进行了总结。为完善我们的分析,我们从训练和评估两个角度,系统总结了相关数据集、评估指标和基准的现状。我们希望本综述能为该领域的研究人员和从业者提供有价值的参考,为未来的研究方向提供指导,并推动空间音频技术的发展。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。