
以下文章来源于 Amphion,作者 Amphion Team。


论文预印版:https://arxiv.org/abs/2510.00981
模型展示页面:https://flexicodec.github.io
仓库地址:https://github.com/amphionspace/flexicodec
音频编解码器是音频语言模型(speech language model)的重要组成部分。现有音频编解码器常以超过50Hz的帧率运行,这导致自回归(AR)语言模型的计算成本高昂且文本与音频模态之间存在帧率不匹配问题。尽管已有工作将帧率降低到12.5Hz,但低于此帧率的解决方案仍未被充分探索。我们发现,主要的挑战在于极低帧率下语义信息的丢失。
在本篇工作中,我们提出一个新的音频编解码器FlexiCodec,旨在通过以下三个创新点来设计一个 <10Hz 超低帧率、语义信息丰富、帧率可控的音频编解码器:
- 动态帧率 (Dynamic Frame Rate):根据语音内容的复杂性自适应调整时间分辨率,在信息密集区域(如快速语音)使用更多帧,在信息稀疏区域(如长元音、音节和静默)使用更少帧。
- ASR引导的语义 (ASR-guided Semantics):利用预训练的自动语音识别(ASR)模型的特征来提取更集中、更丰富的语义信息,以编码核心的RVQ-1 token。
- 可控帧率 (Controllable Frame Rate):在推理时支持3Hz到12.5Hz之间的平均帧率调整。
- TTS 支持:验证了 FlexiCodec 在一个灵活帧率TTS系统中的有效性。该系统支持多种平均帧率设定,多帧率下均表现竞争力,速度明显优于现有方法。
我们的工作是目前最早提出低于 10Hz 帧率的 codec 工作之一,同时,我们在一个低于 10Hz 的 AR TTS 模型上验证了模型实用性。
方法
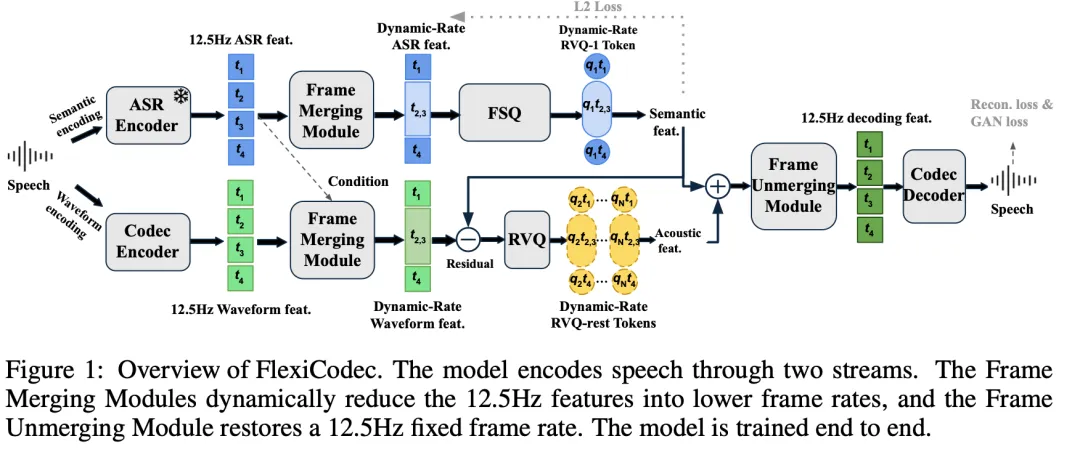
本文提出的FlexiCodec架构设计围绕动态帧率与语义和声学的有效编码展开。整体结构包含两个主要部分:双流编码器和动态帧率策略,以及后续的Transformer瓶颈模块和残差矢量量化(RVQ)方案。
- 双流编码架构
图(1)展示了 FlexiCodec 的整体架构。双流的架构参考了 Amphion 团队此前的 DualCodec 工作,旨在解耦语义和声学信息。
- 动态帧率机制
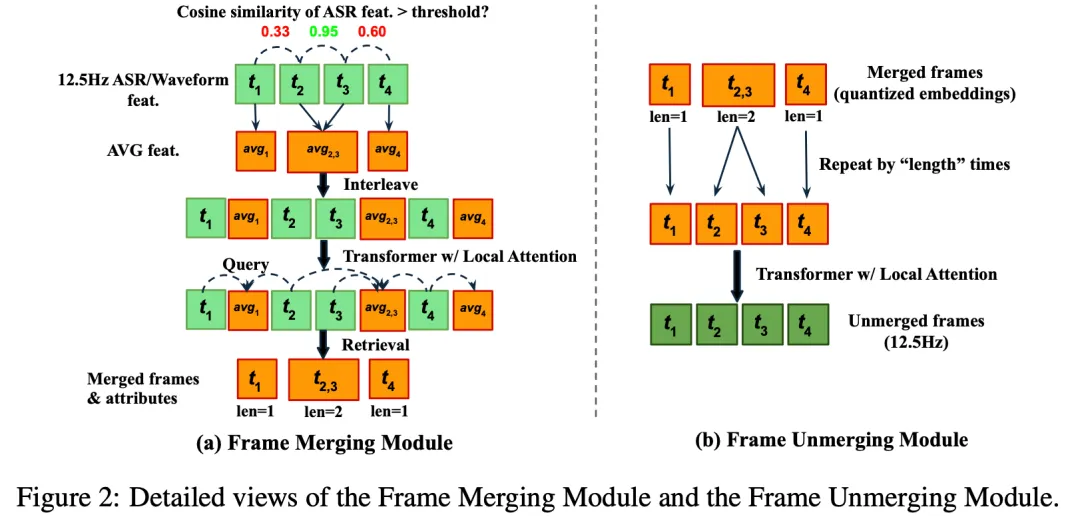
FlexiCodec引入动态帧率机制,如图(2)所示,通过计算相邻帧的语义向量相似度,将语义接近的多个连续帧合并成单一帧,完成从固定帧率到动态帧率的转换。在解码之前,动态帧率 token 会被重复,还原到 12.5Hz 固定帧率。同时,我们采用 Transformer 来辅助帧合并和帧重复。
- 可控帧率推理
FlexiCodec支持推理阶段灵活调节帧率:用户可以根据需求在3Hz到12.5Hz之间调整输出帧率,实现速度与质量的灵活权衡。在资源受限或实时应用中可选择较低帧率以加快下游任务处理速度。在高品质需求时,可选用较高帧率以保证语音细节。
实验
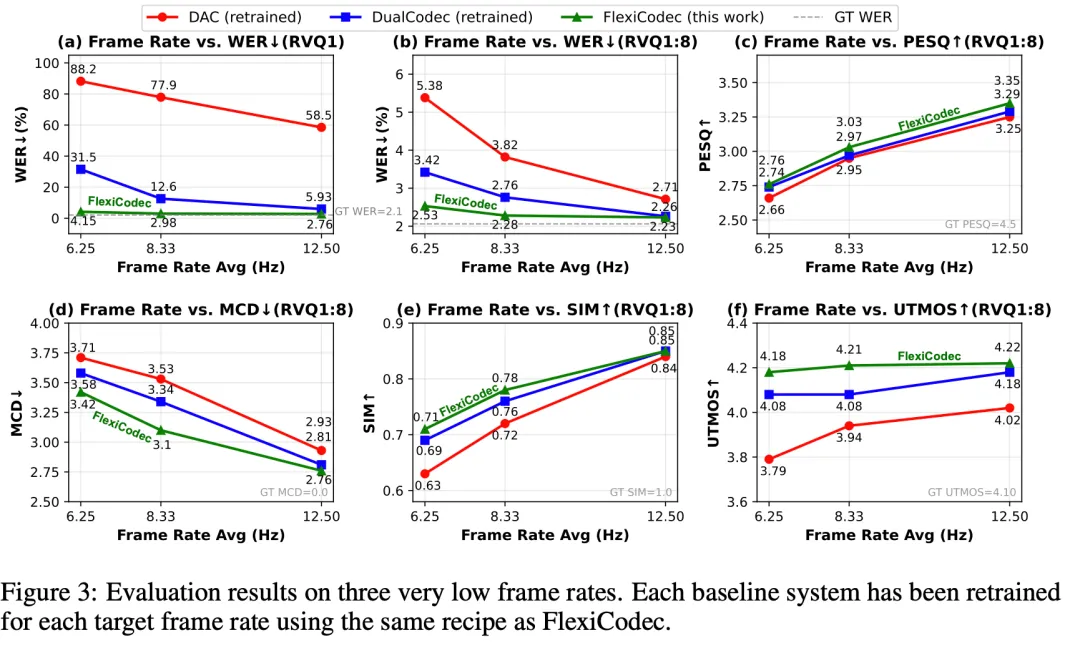
极低帧率下的性能表现: 在6.25Hz、8.3Hz和12.5Hz的平均帧率下,FlexiCodec在语义信息保留方面(通过ASR模型的词错误率WER评估)显著优于在低帧率重新训练的基线系统DAC和DualCodec。声学质量指标(如PESQ、MCD、SIM、UTMOS)也显示FlexiCodec略优于基线。
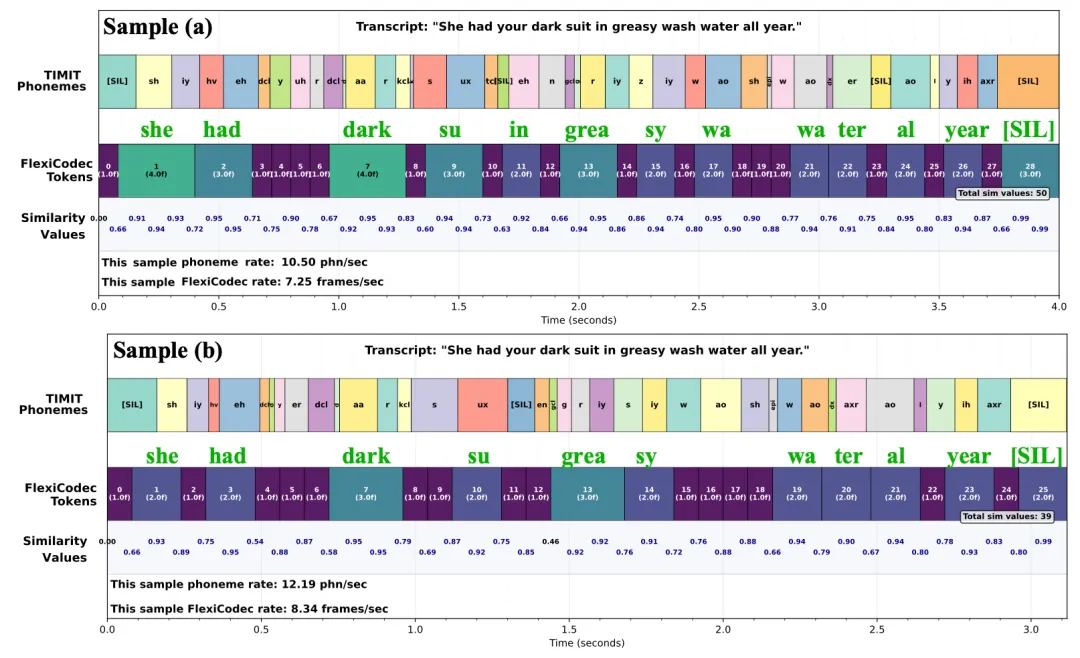
可视化分析:我们通过可视化分析了FlexiCodec的动态帧率 token 与音素的对齐。我们观察到,(1)对于相同的内容,不同说话人的动态帧率合并模式表现出很强的一致性。 尽管四位说话者的音质和韵律有所不同,但动态的merging捕捉到了相似的合并结构,例如,“she”、“had”、“su”、“grea”、“year” 的语音模式以及静音片段。(2)被合并的帧构成音节、短词或常用词(例如,“su”、“your”、“all”)、长元音(例如,“dark”、“water”中的“/aa/”)以及静音区间([SIL])的帧经常被合并。
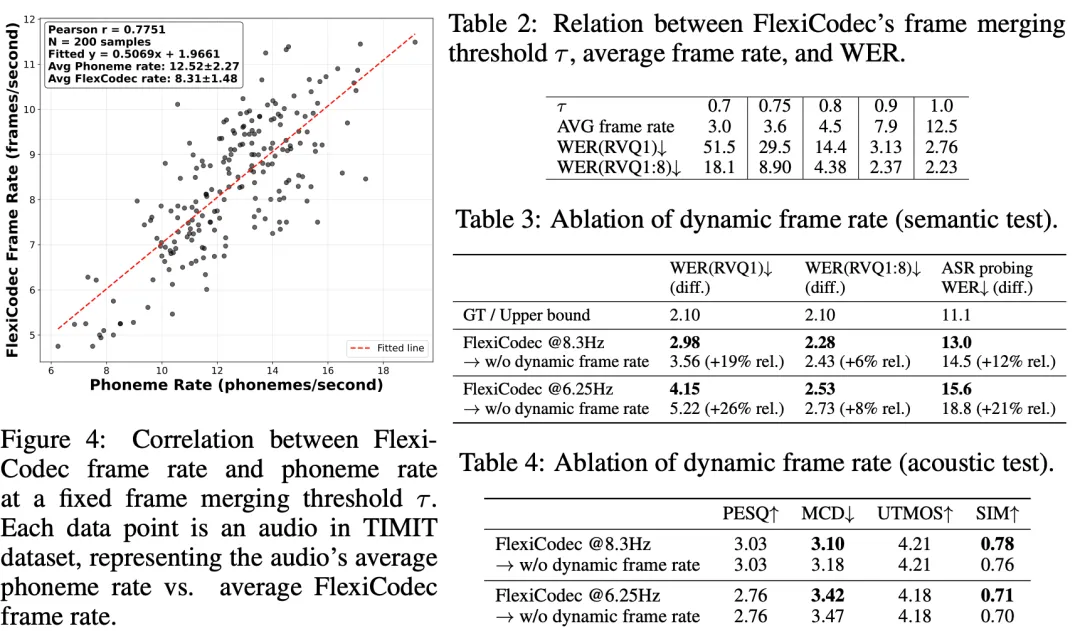
动态帧率分析: 如图(4)所示FlexiCodec的动态帧合并机制能够有效适应语音的音素复杂度,音素率与FlexiCodec帧率之间呈现强正相关(Pearson r = 0.775)。表(2)显示,通过调整帧合并阈值 \tau,模型在推理时可以实现3Hz到12.5Hz的连续帧率控制。表(3)(4)显示,动态帧率策略提升了语义信息保留能力,但在音频音质上影响不大。其中,在6.25Hz帧率下,相比固定帧率的FlexiCodec变体,RVQ-1 WER 从 5.22% 降低到 4.15%。
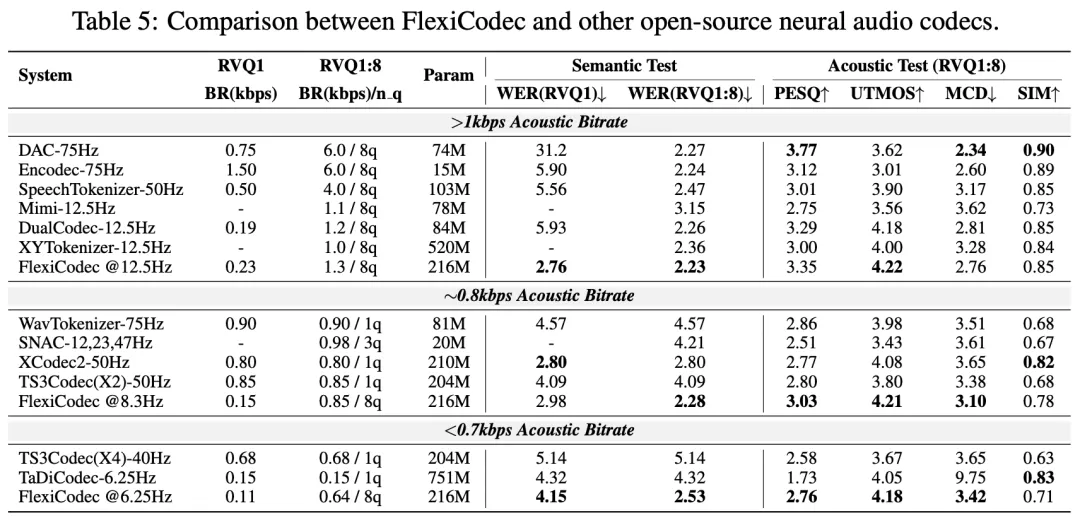
与开源编解码器的对比: FlexiCodec在多种比特率下均展现出先进的音频质量。即使在较低帧率下,FlexiCodec也与高帧率系统具有竞争力。
下游TTS任务应用:
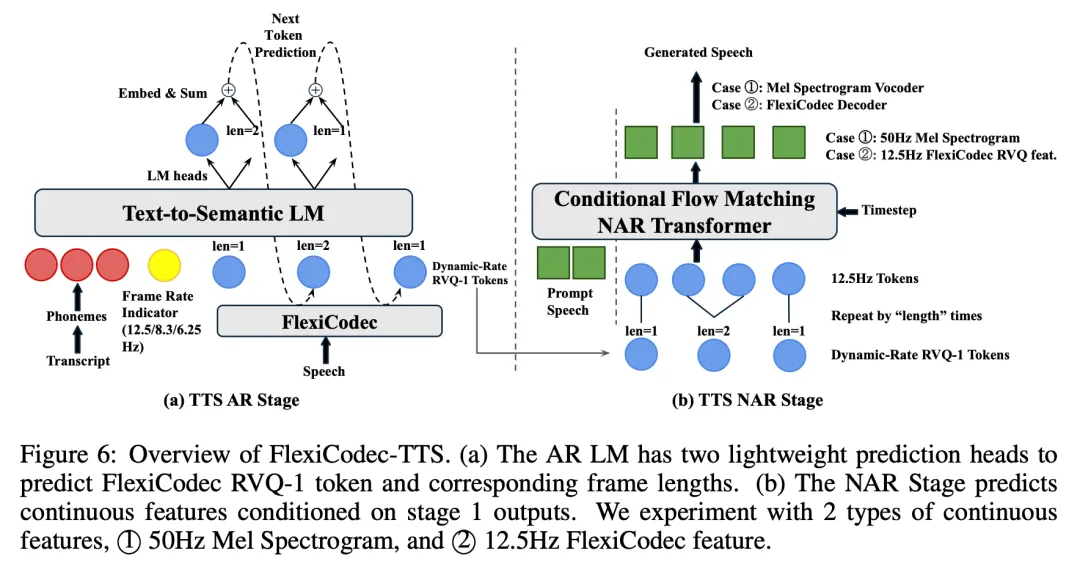
如图(6)所示,FlexiCodec被集成到AR+NAR(Flow Matching)TTS框架中(FlexiCodec-TTS)。
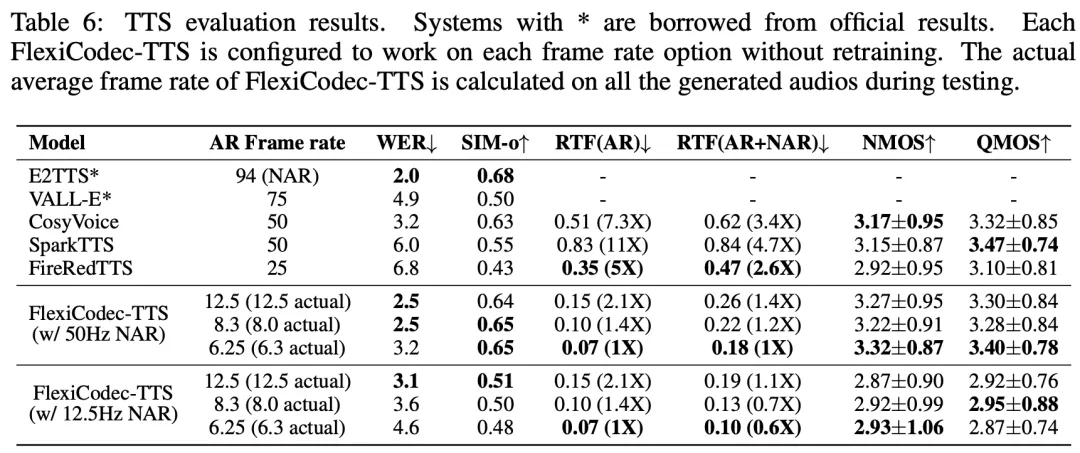
如表(6)结果显示,FlexiCodec-TTS在保持高音质的同时,实现了显著的速度提升。在6.25Hz AR配置下,AR阶段的实时因子(RTF)仅为0.07,比CosyVoice的AR模型快7.3倍。此外,研究发现,高帧率的NAR阶段对音频质量至关重要,而AR阶段使用较低帧率不一定会降低性能。
音频理解任务应用: 在XARES基准的9项音频理解任务中,FlexiCodec的 第一层 token 嵌入表现出色,优于大多数其他编解码器,并能在某些任务(如关键词识别)上与的连续特征模型匹敌,证明其token在通用音频理解方面的强大表示能力。
消融研究: 进一步的消融实验证实了ASR特征的有效性、Transformer在帧合并和解合并模块中的关键作用(尤其在维护声学质量方面),以及FSQ量化相比于 VQ 量化的提升。
结论
FlexiCodec通过引入动态帧率、ASR辅助双流架构以及基于Transformer的帧合并/解合并模块,有效解决了极低帧率下语义信息保留的挑战。它在低帧率和低比特率语音编码方面展现出强大的性能,支持可控帧率,并在下游TTS系统中表现出显著效率和竞争力。未来的工作将探索多语言支持、流式传输、提高可解释性以及在统一多模态大模型(如Audio LLMs)中的集成。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。