
在语音 AI 领域,有效助手和尴尬交互之间的差别往往以毫秒计。基于文本的检索增强生成(RAG)系统可以容忍几秒钟的“思考”时间,而语音代理必须在200毫秒的预算内做出响应,才能保持自然流畅的对话。标准的生产向量数据库查询通常会增加50-300毫秒的网络延迟,实际上在LLM(逻辑语言模型)开始生成响应之前就已经耗尽了全部预算。
Salesforce AI 研究团队发布了VoiceAgentRAG,这是一个开源的双代理架构,旨在通过将文档获取与响应生成解耦来绕过这种检索瓶颈。


双智能体架构:快响应型 vs. 慢思考型
VoiceAgentRAG 充当内存路由器,通过异步事件总线协调两个并发代理:
- 快速响应者(前台代理):此代理负责处理关键的延迟路径。对于每个用户查询,它首先检查本地内存中的语义缓存。如果所需的上下文存在,查找大约需要 0.35毫秒。如果缓存未命中,它会回退到远程向量数据库,并将结果立即缓存以供后续回合使用。
- 慢思考者(后台代理):作为后台任务运行,该代理持续监控对话流。它使用最近六个对话回合的滑动窗口来预测3-5 个可能的后续话题。然后,在用户提出下一个问题之前,它会将相关的文档片段从远程向量存储预先提取到本地缓存中。
为了优化搜索准确率,慢思考者被指示生成文档风格的描述,而不是问题。这样可以确保生成的嵌入与知识库中的实际文本更加吻合。。
技术核心:语义缓存
该系统的效率取决于使用内存中的FAISS IndexFlat IP(内积)实现的专用语义缓存。
- 文档嵌入索引:与按查询含义索引的被动缓存不同,VoiceAgentRAG 使用条目自身的文档嵌入进行索引。这使得缓存能够对其内容执行正确的语义搜索,即使用户的措辞与系统的预测不同,也能确保相关性。
- 阈值管理:由于查询到文档的余弦相似度系统性地低于查询到查询的相似度,系统使用默认阈值。τ=0.40平衡精确率和召回率。
- 维护:缓存使用0.95 余弦相似度阈值检测近似重复项,并采用最近最少使用 (LRU)驱逐策略,生存时间 (TTL)为300 秒。
- 优先检索:当快速说话者缓存未命中时,
PriorityRetrieval会触发慢思考者立即执行检索,并使用扩展的 top-k(默认值的 2 倍)快速填充新主题区域周围的缓存。
基准测试和性能
研究团队使用Qdrant Cloud作为远程向量数据库,对该系统进行了 200 次查询和 10 个对话场景的评估。
| 指标 | 表现 |
| 总体缓存命中率 | 75%(暖弯时为79%) |
| 检索速度提升 | 316x(110米s→0.35米s) |
| 节省的总检索时间 | 200圈用时16.5秒 |
该架构在主题连贯或持续性主题场景中最为有效。例如,“功能对比”(S8)的命中率达到了95% 。相反,在波动性较大的场景中,性能有所下降;性能最低的场景是“现有客户升级”(S9),命中率仅为45%,而“混合快速攻击”(S10)的命中率也达到了 55%。
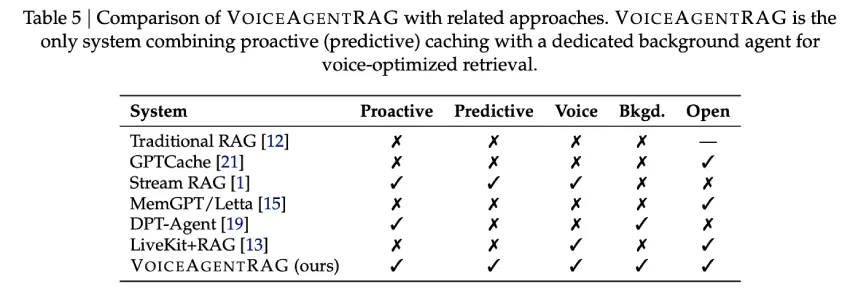
集成与支持
VoiceAgentRAG 代码库旨在与整个 AI 技术栈实现广泛兼容:
- LLM 提供商:支持OpenAI、Anthropic、Gemini/Vertex AI和Ollama。该论文的默认评估模型是GPT-4o-mini。
- 嵌入:该研究采用了OpenAI text-embedding-3-small(1536 维),但该存储库同时支持OpenAI和Ollama嵌入。
- STT/TTS:支持Whisper(本地或 OpenAI)进行语音转文本,支持Edge TTS或OpenAI进行文本转语音。
- 矢量存储:内置对FAISS和Qdrant的支持。
要点总结
- 双代理架构:该系统通过使用前台“快速说话者”进行亚毫秒级缓存查找和后台“慢速思考者”进行预测性预取来解决 RAG 延迟瓶颈。
- 显著提升速度:检索速度提升了 316 倍(110米s→0.35米s)缓存命中,这对于保持在 200 毫秒的自然语音响应预算内至关重要。
- 缓存效率高:在各种场景下,系统保持 75% 的总体缓存命中率,在主题连贯的对话(如功能比较)中,缓存命中率最高可达 95%。
- 文档索引缓存:为了确保准确性,无论用户如何措辞,语义缓存都会根据文档嵌入而不是预测查询的嵌入来索引条目。
- 预测性预取:后台代理使用最近 6 个对话回合的滑动窗口来预测可能的后续主题,并在自然的回合间停顿期间填充缓存。
论文地址:https://arxiv.org/pdf/2603.02206
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/jishu/65827.html