
AI 推理的实际成本正为当前 AI 革命的迅猛势头注入一剂清醒剂,人们对优化机器学习成本的关注度也随之提升。除了将 AI 引入企业内部的潜力以及私有 AI 的普遍兴起之外,那些对 VRAM 需求巨大且资源消耗惊人的机器学习流程显然也需要进行优化。
就这一点而言,视频生成或许是最大的“罪魁祸首”。如果你曾对电影进行过重新压缩,或从视频编辑套件中导出视频,你应该已经深知这项特定的(非AI)任务对硬件造成的负担。它会消耗内存和CPU周期,并且往往会占用整台机器,使其无法进行其他操作,除非采取措施限制压缩算法对主机的影响。
因此,我们只需想象一下,AI 视频的兴起正在全球数据中心以何种程度重演这一“资源狂魔”般的过程。在如此大规模的运算中,哪怕最微小的性能提升,在整体计算中也会立即变得至关重要。
聚焦帧内
基于这一思路,上海的一项新研究(与京东合作)提出了一种视频编解码器,其目标并非渲染输出过程(即将海量原始帧压缩成较小视频文件的过程),而是针对实际的AI视频生成过程本身。
常规视频编解码器的工作原理并非将每个帧都作为完整图像存储,而是生成少量完整的画面(称为I帧),随后仅记录帧与帧之间的变化。
例如,如果视频中的人物略微移动,编解码器只会记录帧中发生变化的部分,而非重写整个场景。这些帧包括基于前一帧生成的P帧,以及能够预测后续帧信息的B帧:
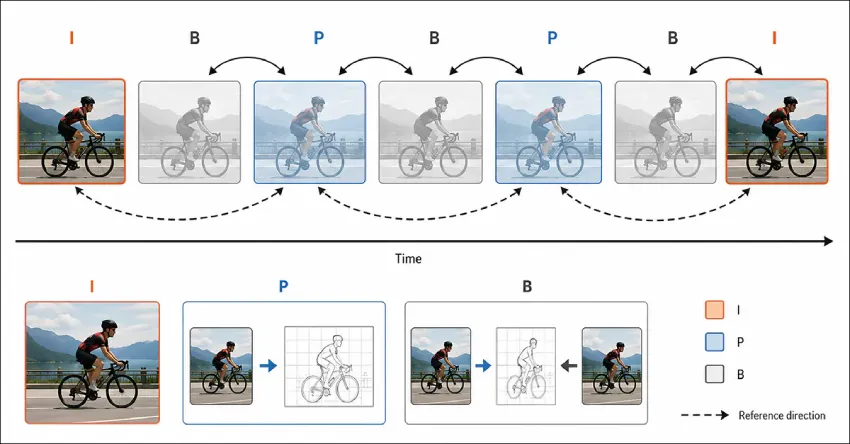

如图1:视频编解码器结构:顶行显示随时间变化的帧,分别标记为 I、P 和 B,其中 I 帧以全彩完全存储,P 帧和 B 帧以淡化显示以指示重建;箭头指示帧是使用较早的帧、较晚的帧还是两者都使用;下方面板描绘了完全存储的帧(I 帧,左)、由前一帧构建的帧(P 帧,左二)以及由较早和较晚的帧构建的帧(B 帧,右)。
正是由于对附近信息的重复利用,视频文件才能保持较小的体积。大多数帧并非作为新的图像运行,而是作为描述前一帧变化情况的指令。因此,Iframe 构成了“完整”的、占用大量空间的未压缩(或最小压缩)图像,而 Iframe 之间的帧仅包含 Iframe 之间(以及 Iframe 自身之间)的差异。
当每一帧都是完整的未压缩图像时,影片实际上就没有压缩。以这种方式保存影片(即未压缩视频),一部两小时的影片将需要接近(甚至超过)1TB的磁盘空间。然而,AI 正是通过这种方式制作影片,在计算如何生成视频时,将相同的资源和令牌分配给每一帧。
规模经济
这项名为《AdaCodec: A Predictive Visual Code for Video MLLMs》的新研究,则将完整的视觉令牌完全用于参考帧(I帧),而所有插值帧均以“紧凑型P令牌”的形式呈现——这一范式显然借鉴了传统“现实世界”视频编解码器所采用的压缩技术。
完成这种内部压缩后,生成式AI视频即可进行常规压缩,理论上,所有节省的资源都体现在服务器端:

图 2 AdaCodec概述。左图:视频被分割成自适应的图像组,完整的I帧用于难以预测的时刻,中间的P帧则使用紧凑运动和残差信息来表示。右图:该系统在11项基准测试中均达到或超过Qwen3-VL-8B的性能,在不同的令牌预算下保持更高的长视频精度,并在处理更少的视频令牌的同时降低响应延迟。
根据 AdaCodec 的测试结果报告,节省的成本是值得追求的;该论文指出,该系统在所有主要基准测试中都优于未经修改的Qwen3-VL-8B模型,同时使用了相同的处理量;并且在将视频令牌减少约 86% 后,仍然达到或超过了该模型的性能。
作者指出:
“我们从预测编码中汲取了灵感,该技术中系统传输的是预测误差,而非原始信号。这一原理具有生物学依据:人们认为视觉系统编码的是预测误差,即预期输入与实际观察到的输入之间的偏差,而非输入本身。
现代视频编解码器在工程上采用了相同的残差编码理念:参考帧承载完整内容,而预测帧则承载相对于参考帧的运动和残差信号。
这些系统虽然目标不同,但具有相同的条件结构:当相邻样本存在冗余时,信道应承载预测无法解释的部分。
然而,标准编解码器优化的是比特流和人类可视的重建效果,而非大语言模型(LLM)所消费的视觉符号。因此,我们将该机制重新设计为一种用于视频理解的机器学习语言模型(MLLM)接口。”
这项由上海交通大学、上海创新研究院和京东的 11 位研究人员共同完成的新研究,配有相应的项目页面,并承诺将发布源代码。
方法
如前所述,该系统并非将每一帧都视为全新的图像,而是寻找帧与帧之间发生变化的部分。在下图左侧,我们可以看到当前帧的一小部分区域与先前帧中最相似的区域进行匹配:

这两个位置之间的距离成为运动向量,而剩余的视觉差异则成为残差,这些紧凑的描述取代了存储完整图像的需求。
右侧展示了输入到 AI 模型中的信息:重要的参考帧仍作为完整图像进行处理,但中间帧则由体积小得多的运动与残差令牌表示。这显然使模型在处理显著减少的视觉数据的同时,仍能保留足够的信息来解析视频。
一个有趣的挑战在于如何决定哪些帧值得完整存储:传统视频编解码器通常会以固定间隔放置参考帧,无论是否需要。而 AdaCodec 则试图识别出最重要的时刻。
例如,设想一个主要描绘公寓内两人静态对话的场景——突然间,一支特警队破窗而入。此时,镜头视角和剪辑次数将急剧增加,所需的数据量远超常规参考帧间隔所能提供的:

这就是可变压缩(可变比特率)压缩方法背后的原理:该方法会分析源视频中的此类“繁忙”时段,并在需要的地方分配更多数据,但这需要付出不小的时间和资源成本。
在 AdaCodec 中,如果能根据相邻帧准确预测当前帧,系统便继续使用紧凑的运动与残差令牌;如果场景发生显著变化(例如上文提到的SWAT场景,或类似的较不剧烈的变化),则会插入一个完整的参考帧。这使得可用的处理资源能够更多地投入到重要的视觉信息上,而非均匀地分配到整个视频中。
数据与测试
在测试中,研究人员采用前述的Qwen3-VL-8B作为基础模型,并在涵盖视频理解三个领域的十一项基准测试中对AdaCodec进行了评估:长视频性能通过MLVU、LongVideoBench和LVBench进行评估; 通过TempCompass、MotionBench和TOMATO评估时序理解能力;通过Video-MME、MVBench、NExT-QA、PerceptionTest和EgoSchema评估通用视频理解能力。
测试的开源模型包括:InternVL3.5-8B、Keye-VL-1.5-8B、GLM-4.1V-9B、MiniCPM-V-4.5-8B、Eagle2.5-8B、PLM-8B、LLaVA-Video-7B、VideoChat-Flash-7B、Molmo2-8B 以及 Molmo2-O-7B。
下表中列出的GPT-5、Gemini和Claude变体仅作为比较基准。CoPE-VideoLM-7B和ReMoRa-7B是较早的视频语言模型,它们通过受编解码器启发的压缩技术减少了视觉令牌的使用,因此是AdaCodec最直接的竞争对手:

为了确保公平比较,我们为 AdaCodec 和标准 Qwen3-VL-8B 系统分配了相同数量的视觉标记,使结果能够反映压缩方法的有效性,而不是计算资源的任何差异。
在最激进的设置下,AdaCodec 将视觉标记的使用量减少了约 86%,同时在长视频、时间性和一般视频理解任务上仍然与基线系统持平或略微超过基线系统。
当节省下来的 token 被重新投入到处理更多视频帧中时,每个长视频基准测试和每个时间基准测试的性能都有所提高,在 LongVideoBench 上提高了 5.4 分,在 TOMATO 上提高了 4.3 分,同时还产生了该研究中一些最强的开源结果。
结论
尽管此类项目通常面向超大规模服务提供商,但作为围绕本地化、合理化人工智能部署而兴起的潜在“公共节俭主义”的一部分,这类努力同样会引起业余爱好者和中小企业的兴趣。
在 r/stablediffusion 等社区中,这早已不是什么新鲜事,因为那里发布的每个主要开源项目,都会被反复打磨成超优化版本(如 GGUF、量化权重等),只要稍加耐心,这些版本便能在低端显卡上运行。
如果这场第三次AI热潮的“表演阶段”确实已经结束,且假设企业会被推理的真实成本所吓退,那么像AdaCodec这样的项目可能会成为即将到来的“大优化”的一部分。
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/jishu/67288.html