
Zyphra 发布了 Zamba2-VL,这是一系列开放的视觉语言模型。该版本涵盖三种规模:12 亿、27 亿和 70 亿参数。每个模型都基于 Zamba2 混合 SSM-Transformer 架构构建。
视觉语言模型(VLM)能够同时读取图像和文本,并回答有关图表、文档和照片的问题。大多数开源VLM使用密集Transformer作为语言模型。Zamba2-VL则用混合状态空间设计取代了它,其目标是在更低延迟下实现具有竞争力的准确率。
什么是 Zamba2-VL
Zamba2-VL 遵循目前标准的 LLaVA 式 VLM 模板。预训练的视觉编码器将图像块转换为特征。轻量级的 MLP 适配器将这些特征投影到语言模型的坐标系中。然后,语言模型读取交错的视觉和文本标记序列。该模型支持单图像和多图像的理解与关联。
Zyphra 将每个 Zamba2 主干网与 Qwen2.5-VL 的 Vision Transformer 编码器配对。选择该编码器是基于其两个特定特性:它采用二维旋转位置嵌入和原生动态分辨率处理。一个双层 MLP 适配器将编码器连接到主干网。
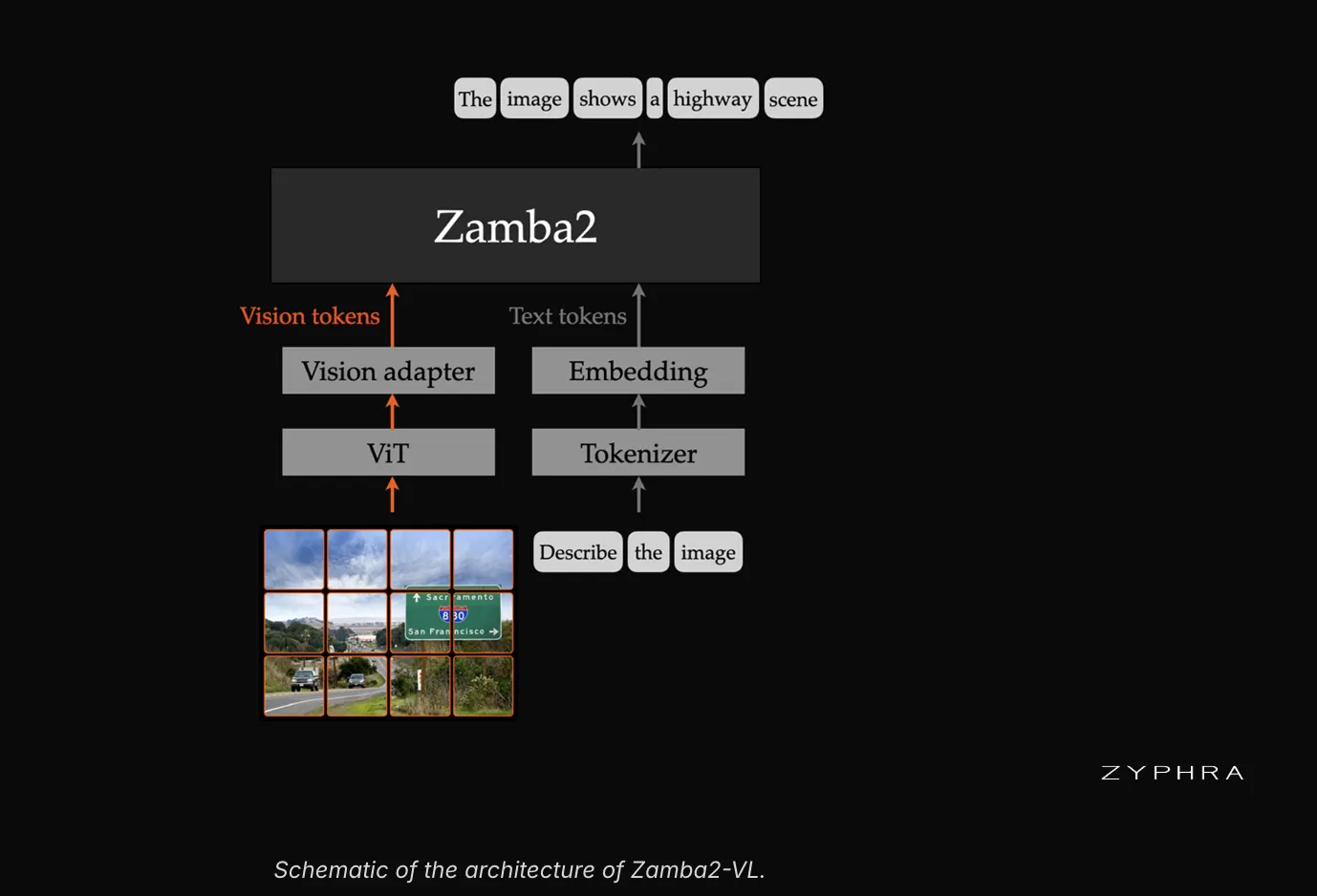

架构
Zamba2 的主干网是其设计与典型 VLM 的主要区别所在。它是由 Mamba2 状态空间层和共享 Transformer 模块混合而成。Mamba2 层以线性时间运行,状态大小固定。少量共享注意力层交错于它们之间。每个共享模块的每一层都承载着一个唯一的 LoRa 适配器。
Mamba2 层承担了大部分计算任务,且计算成本很低。共享注意力层保留了纯 SSM 模型所放弃的上下文信息检索能力。这种混合模型以完全注意力表达能力和状态空间效率为代价。
Zamba2-VL 使用 Mistral v0.1 分词器。它使用 1000 亿个视觉文本和纯文本词元进行训练。这些数据来源于开放的网络数据集。

模型质量和基准
研究团队对 Zamba2-VL 进行了 14 项基准测试,涵盖图表、示意图和文档理解,以及一般感知、推理和视觉计数能力。所有分数均来自 Zyphra 基于 VLMEvalKit 的评估工具。该报告将 Zamba2-VL 与 Molmo2、Qwen3-VL 和 InternVL3.5 系列进行了比较。
| 评估 | Zamba2-VL-2.7B | InternVL3.5-2B | Qwen3-VL-2B | Molmo2-4B | Qwen3-VL-4B |
|---|---|---|---|---|---|
| DocVQA(test) | 90.9 | 89.4 | 93.3 | 87.8 | 95.3 |
| ChartQA(test) | 79.6 | 81.6 | 78.7 | 86.1 | 81.8 |
| OCRBench | 73.6 | 83.4 | 84.1 | 62.0 | 84.1 |
| CountBenchQA | 87.5 | 70.0 | 87.9 | 91.2 | 87.3 |
| PixMoCount(test) | 82.5 | 32.8 | 55.7 | 87.0 | 89.2 |
| MMMU(val) | 37.7 | 49.9 | 40.9 | 48.8 | 51.4 |
| MathVista(mini) | 51.0 | 61.4 | 51.8 | 56.5 | 63.6 |
InternVL3.5-2B 和 Qwen3-VL-2B 尺寸相近。Molmo2-4B 和 Qwen3-VL-4B 尺寸更大。
这种模式并不均衡,值得深入理解。计数是表现最强的类别。Zyphra 报告称,Zamba2-VL-1.2B 在 PixMoCount 测试中得分为 62.5。相比之下,InternVL3.5-1B 的得分为 32.8,PerceptionLM-1B 的得分为 17.7。文档理解方面也表现出色,2.7B 模型的 DocVQA 得分为 90.9。但在知识密集型推理方面,该模型落后于 MMMU 和 MathVista 等规模更大的基线模型。
为什么推理速度更快
Zamba2-VL 的主要优势体现在推理环节。Transformer 的注意力机制会随着序列长度呈二次方增长。多模态输入会迅速拉长序列长度。一张高分辨率图像就能产生数千个视觉标记。一段短视频就能产生数万个标记。
Zamba2-VL 避免了注意力机制中不断增长的键值缓存。它继承了近乎线性时间的预填充机制和固定大小的循环状态。在 32k 个 token 的预填充任务中,它在得分与 TTFT 的关系图中领先。对比中没有其他 Transformer VLM 能在类似的延迟下达到与其相同的得分。延迟差距至少有一个数量级。
在 12 亿和 27 亿规模下,效率优势最为显著。这正是设备端和边缘部署的目标规模。
场景及示例
实际问题在于它适用于哪些场景。文档和表单提取受益于 DocVQA 的出色性能。例如,大规模的发票解析或收据数字化。零售和库存盘点则与 PixMoCount 和 CountBenchQA 的优势相契合。接地支持功能可指向产品或 UI 图像中的对象。设备端助手受益于其极低的首次令牌获取时间。12 亿版本主要面向手机和边缘设备。对于多页 PDF 等长篇视觉输入,线性时间预填充功能优势最为显著。
优缺点
优点:
- 据 Zyphra 称,这是第一个基于完全开放的混合 SSM-Transformer LLM 的开放式 VLM 系列。
- 首次令牌生成时间比同类 Transformer 基线低一个数量级。
- 具备较强的视觉计数能力和对竞争性文件的理解能力。
- 三种尺寸涵盖边缘、中部和 7B 级部署。
- 采用 Apache 2.0 许可证,包含公开的权重和可运行的推理代码。
缺点和挑战:
- 作为研究成果发布。
- 在知识推理方面落后于 MMMU 和 MathVista 等大型模型。
- OCRBench 性能低于同尺寸的 Qwen3-VL 和 InternVL3.5。
- 优化后的内核需要 CUDA GPU;CPU 路径速度较慢。
- 部署需要从已发布的代码进行自托管。
要点总结
- Zamba2-VL 在 Apache 2.0 下以 1.2B、2.7B 和 7B 参数交付。
- 主干网将 Mamba2 状态空间层与一些共享的 Transformer 模块配对。
- 与同类 Transformer VLM 相比,首次令牌生成时间下降了一个数量级。
- 计数和文档理解能力强;知识推理能力弱。
- 权重和工作推理代码已在 Hugging Face 和 GitHub 上公开。
参考资料:
- https://arxiv.org/pdf/2606.00390
- https://github.com/Zyphra/transformers/tree/zamba2-vl
- https://huggingface.co/collections/Zyphra/zamba2-vl
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/jishu/67908.html