
导读:本次分享主要介绍腾讯 AI Lab 近期在人脸高效率 3D 数字化技术方面的研究成果,包括使用单张照片、多张照片、RGBD 自拍等方式进行人脸 3D 数字化,以及在人脸 3D 建模精度的评估方法等方面的研究。
全文目录:
- 人脸 3D 数字化概览
- 如何评估 3D 人脸重建
- RGBD 自拍数字化
- 问答环节
分享嘉宾|暴林超博士 腾讯AI Lab 专家研究员
编辑整理|马南 海天瑞声
出品社区|DataFun
01 人脸3D数字化概览
如下是我们现在在腾讯 AI Lab 做的一个高保真 3D 数字人小志,是采用虚幻引擎渲染的效果。从静态的建模角度来看,现如今数字人脸部的数字化技术,基本上已经可以做到以假乱真,看起来跟照片非常接近的程度。动态的效果展示中,表情是模拟真人表情的动画,结合语音驱动的数字人的口型和动作。


高保真 3D 数字人是如何制作出来的呢?其制作管线流程如下:
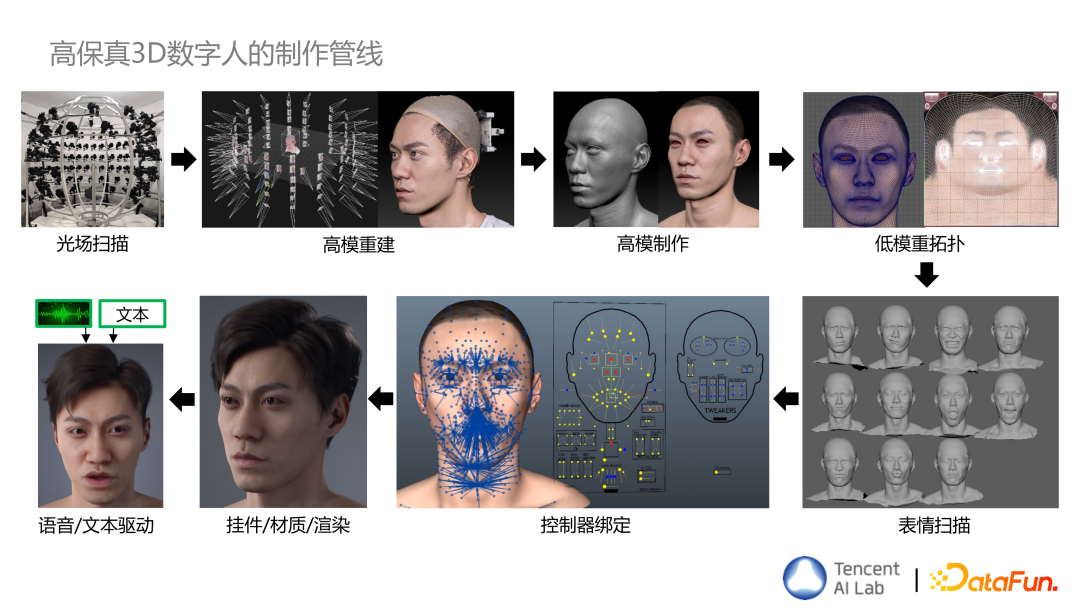
首先使用光场扫描的方式采集模特的图片数据,然后对这些图片数据进行高模重建,重建的过程会有噪声或者瑕疵,高模制作就是对瑕疵的清理、以及细节的雕刻,同时会按照固定的拓扑模板做一个低模重拓扑,这个过程中就可以制作出 UV 贴图,包括材质渲染所需的贴图,比如法线贴图、高光贴图、粗糙度贴图。上面这些环节是静态建模的过程。
后续如果要让其动起来,还需要一些动态建模的过程,比如会先有一些演员不同表情的扫描,这些扫描的数据还是需要经历前面的高模重建、高模制作、以及低模重拓扑的制作管线,才能真正用到动画的资产里面去。下一步非常耗时的步骤其实是做控制器绑定,这一步对于后续的动画动作是否自然生动至关重要。接下来是处理头发、眼珠、牙齿等挂件,以及皮肤材质的设置、渲染等步骤。最后基于语音的输入或者文本的输入,让其自动做一些口型、表情,以及动作。整个的数字人制作管线就是这样的一个流程。
制作 3D 写实数字人的工期久、人工成本大,所以 AI Lab 也在研究如何能更高效地制作高保真的数字人,主要分了几条不同的路线来做技术的探索,各级方案的特点如下:

S 级别的数字人制作方案,耗费的时间和人工较大,是为了追求最高的质量。我们技术侧研究更多是偏向 A、B、C 三个级别,无论是采集设备还是制作方案方面,都希望能够更高效、更便捷地制作高保真数字人。比如 A 级,不再使用 S 级中的 360° 光场设备,而是使用相对简易的相机阵列,很容易搭建起来,后续采用以 AI 算法为主的生成,因为输入是比较丰富的,所以能够兼顾高品质和高效率。B 级和 C 级是针对消费端的输入,可以实现任意用户采用消费端设备就可以采集并自动生成高保真数字人形象。最简单的是 C 级别的方案,用单张或多张照片,就可以实现人脸的重建,以及后续的数字化。这种方案是 C 端用户最容易触达的。下面我重点介绍一下我们在 B 级方案中研发的一套算法,这项工作已经发表到了图形学顶刊 ACM Transactions on Graphics 上。
02 RGB 自拍数字化
RGBD 自拍的图像以及深度数据,经过算法自动选帧,筛选出覆盖人脸各个角度、且动作没有变形的一些帧,再进行几何建模、材质建模,得到一个高清的纹理贴图以及高清的法线贴图,然后我们会复用在渲染引擎里面的一些其它的贴图,当然从法线贴图还可以进一步算出粗糙度贴图。
接下来介绍整个算法的流程,主要分为 7 个步骤:
- 步骤一 自动选帧算法
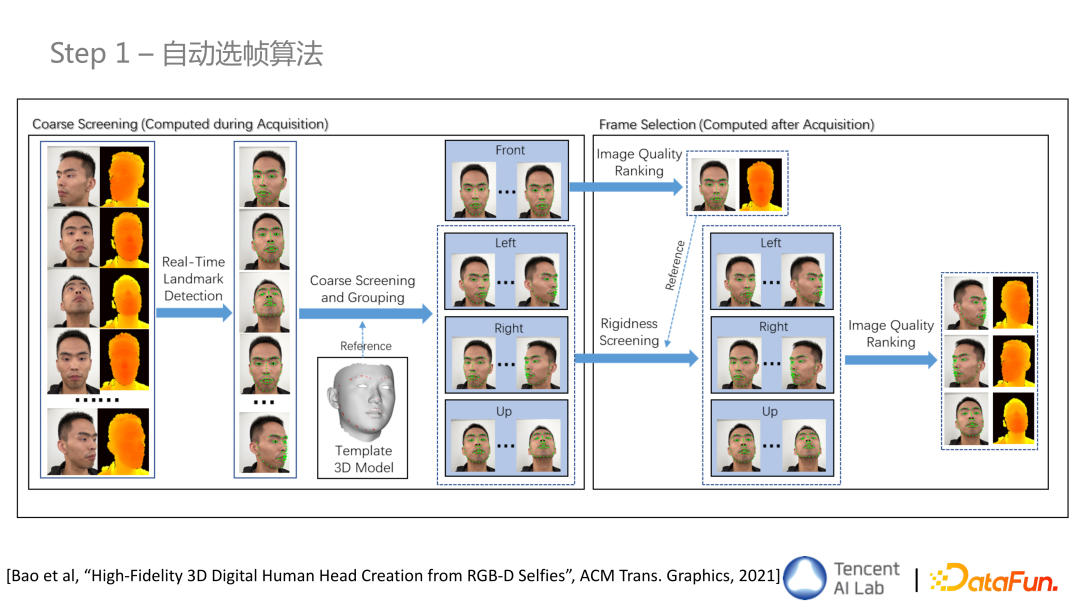
这一步包括多步筛选,首先是 Landmark Detection 粗筛,从正脸、侧脸、仰头等不同角度都筛选出一些候选的帧。在这些候选帧中,会进行刚性筛选,筛选出与参考帧相比,没有任何动作的帧。最后根据图像质量排序,选出正脸、左、右、上四张 RGBD 数据。
- 步骤二 模型初始拟合

在初始拟合步骤中,首先会进行传统的关键点拟合,得到一些初始形状,提取脸部区域后,得到不同侧面的 UV 展开,之后再进行融合和参数化拟合,就可以得到初始颜色贴图。
- 步骤三 基于可微渲染的优化
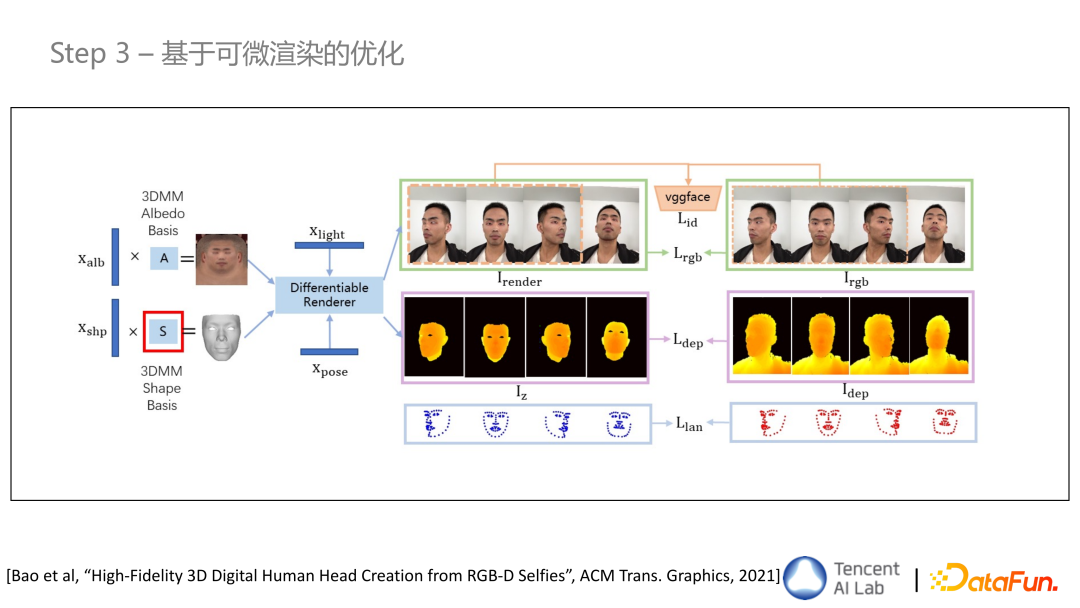
基于可微渲染的优化框架是我们整个建模中最核心的算法。基于一个可微渲染器,根据图像的 appearance 信息,以及 ID 的一致性信息和 depth 的一致性信息,再加上 landmark 各种约束,来反推基于 3DMM 的 shape 和 texture 的参数。
- 步骤四 纹理/法线贴图合成
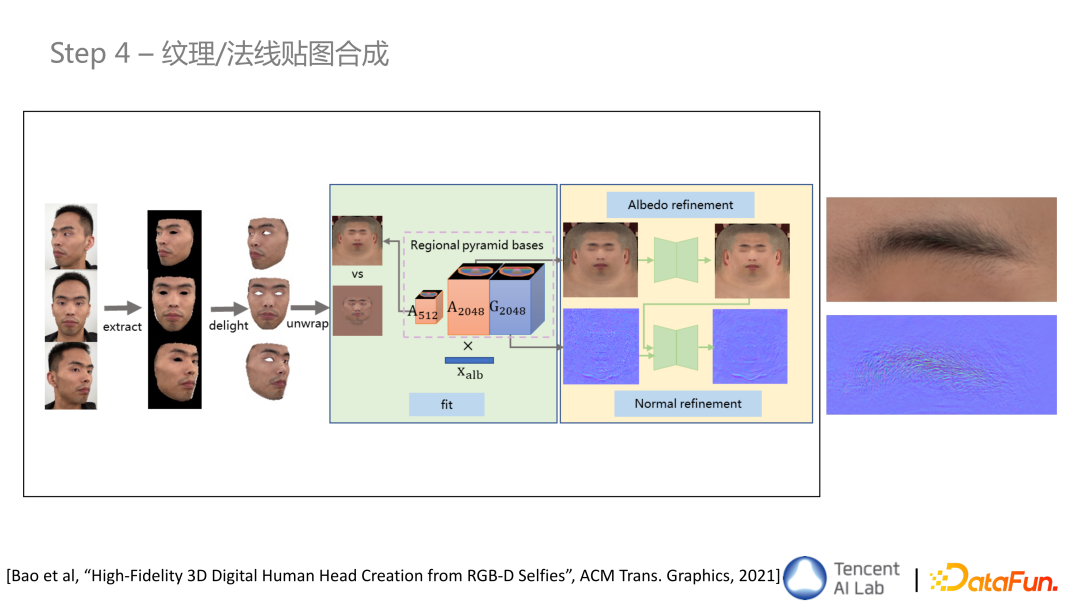
基于前步初始的 UV 展开后的图,经过更细致的,基于局部金字塔的纹理贴图基底去做 fitting,得到一个基于纹理基底的参数的表示,之后得到由参数化 fitting 融合出来的2k 的纹理贴图和法线贴图,再经过 image translation network 做纹理贴图和法线贴图的精细化,最终得到细节更加清晰的图。
- 步骤五 补头/挂件挂载/渲染

经过了 shape 的重建,以及纹理贴图和法线贴图的生成后,后续还要进行补头、挂件挂载(头发、眼珠、牙齿)等工作,并进行最终的渲染。
下面是一些结果展示。
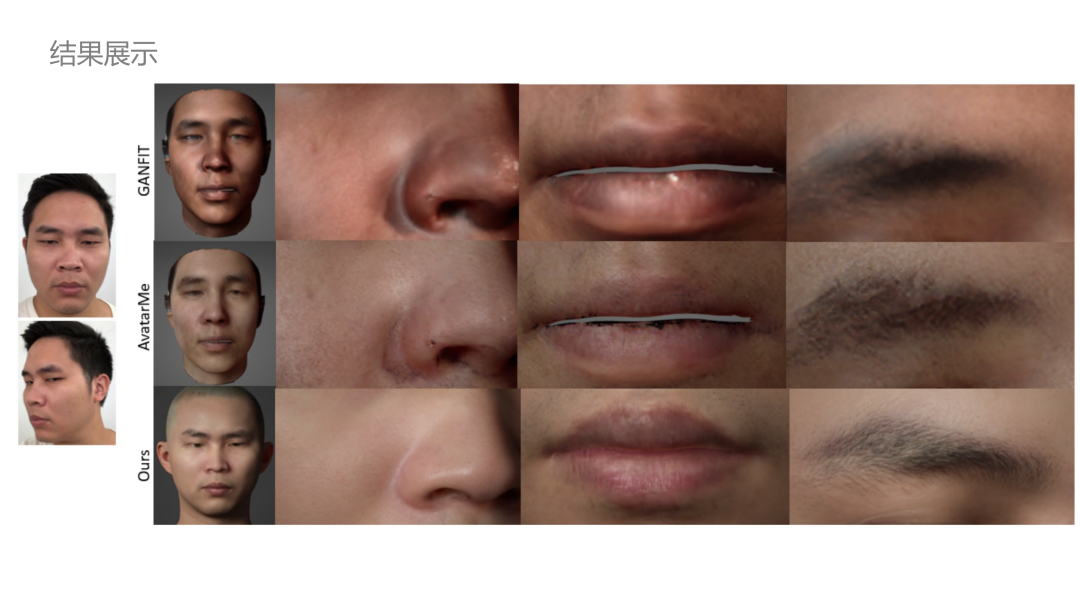

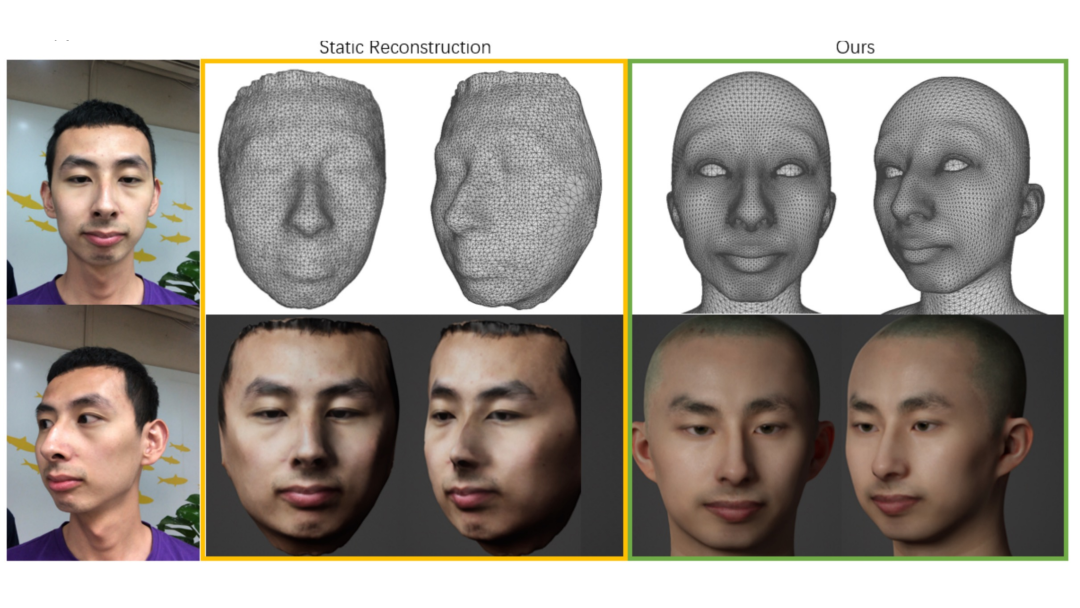
- 步骤六 AutoRigging
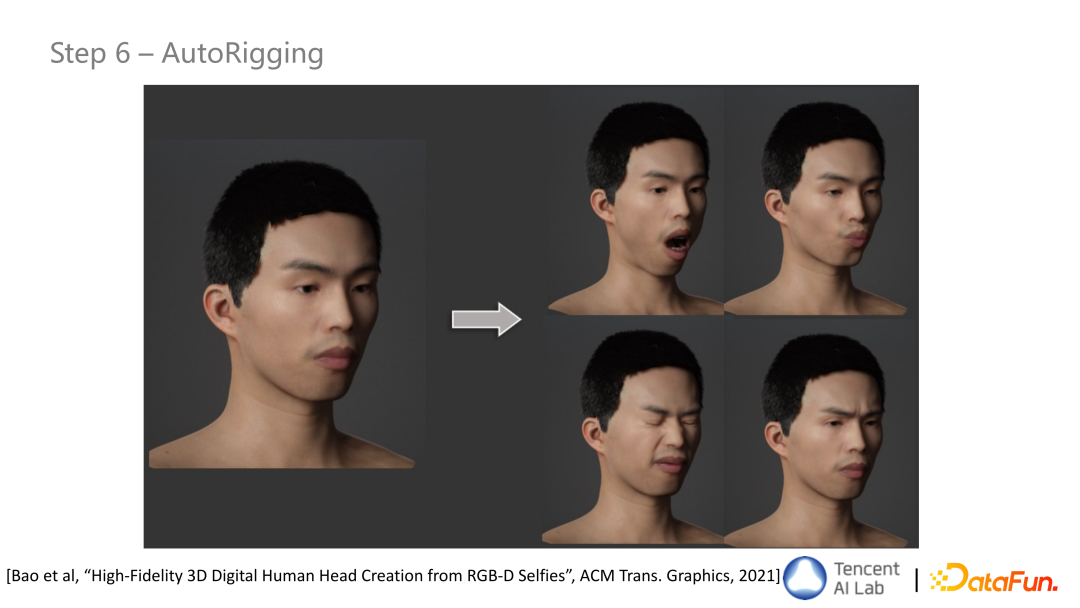
静态建模后,可以利用变形迁移等技术生成相应的表情 blendshape 资产。
- 步骤七 文本/语音驱动

有了以上资产后,就可以通过文本、语音驱动让数字人动起来。整个算法流程大致是这样的,我们在 TOG 论文里对于每个步骤有更详细的描述,算法的核心代码也已经开源,欢迎大家扫码关注。在上面的工作中,最核心的一个步骤是重建出高保真的人脸模型,下面我们针对这个问题进行更深入的探讨。
03 如何评估 3D 人脸重建

3D 人脸形状的重建是一个比较核心的部分,我们对 shape 重建的结果和一些 SOTA方法进行了对比,也有在 benchmark 上面做一些客观评测。很多情况还是需要仔细的去观看,比如脸部形状的贴合程度和嘴形鼻子形状的重建效果。最终发现目前的 benchmark 都无法与主观感受的效果相吻合,在这个过程中,我们发现 3D 人脸重建结果评估方法其实是存在很多问题的。
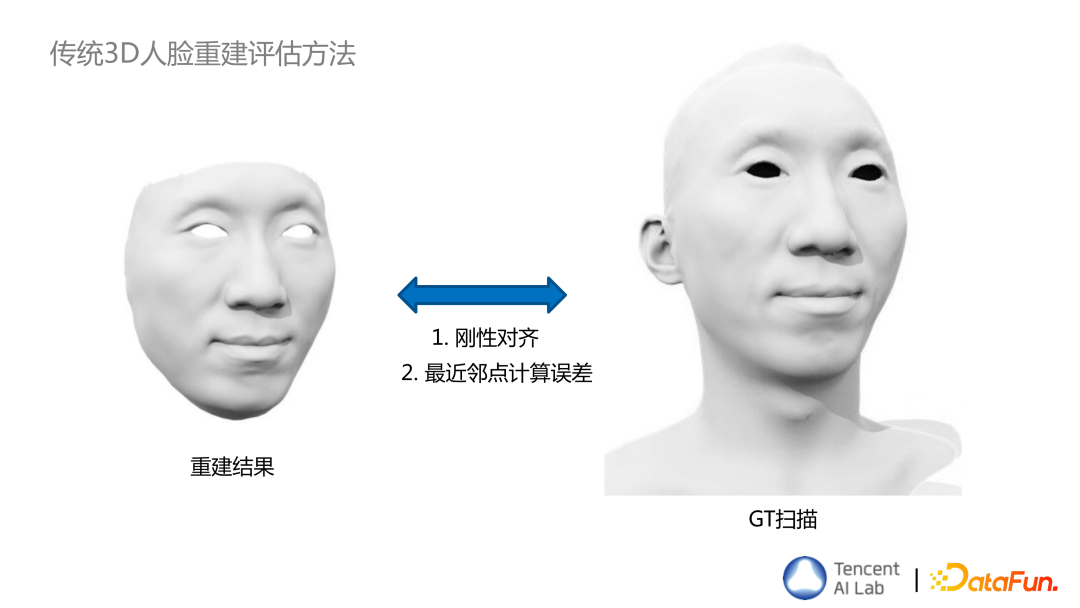
传统 3D 人脸重建评估方法主要有刚性对齐和最近邻点计算误差两个步骤。
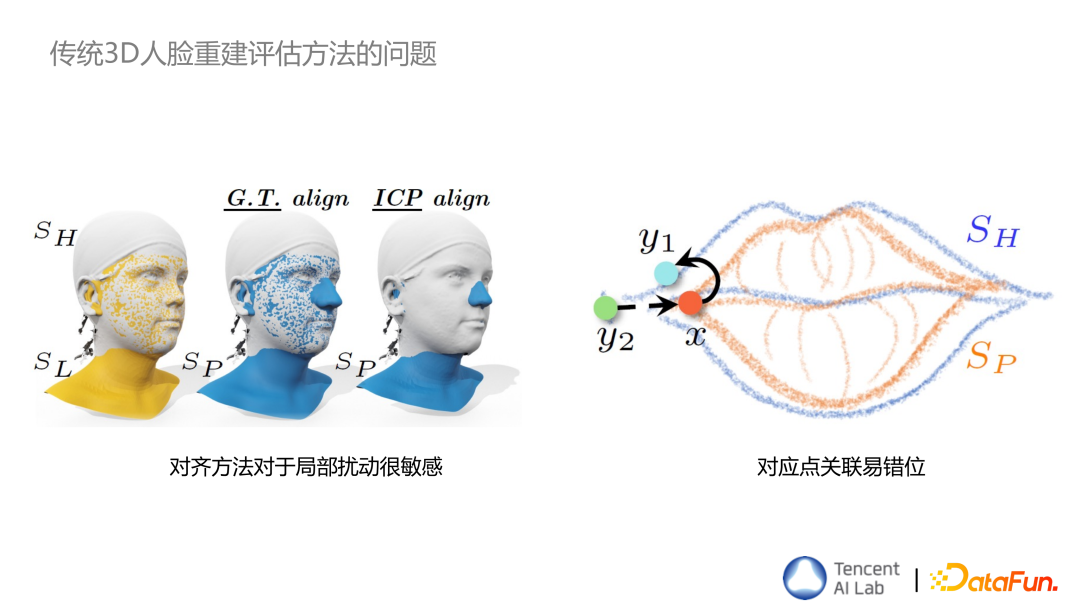
在刚性对齐步骤中,容易出现的问题,是对齐方法对于局部扰动很敏感。比如上图中灰色模型和黄色模型可以很好的对齐,如果对鼻子做一个扰动,理想情况下应该还是用原来的对齐相对 pose 来计算 error,那么鼻子区域的 error 就会比较大,但事实上经过算法重新计算刚性对齐后,很多其它地方都会参考鼻子去做 alignment,导致整个脸的区域会后移,这样计算出来的 error 就不能很好的反应哪些区域重建的不好。
另一个问题是在找对应点计算 error 的过程中,对应点关联易错位。比如上图中蓝色的线是 GT 效果,橙色是计算出来的效果,x 点应该与 y2 点对应,但如果用最近点很容易把 x 点与 y1 点对应。
针对这两个问题,我们在 3D 人脸重建的评估方法上做了一些改进。首先基于前面发现的问题,我们重新做了一个用于评估的 benchmark 数据集,叫做 REALY。REALY 包含 100 对 2D 图片(下图中第一排),以及 3D 扫描模型(下图中第二排),最关键的是第三排,每个人脸的扫描模型做了一个统一的拓扑对齐后,再把原始高模对应的语义信息进行分割,就得到了在高模上的脸部区域的一些 Mask,我们可以分别对每个区域做评估,甚至对每个区域做完对齐之后做评估。

评估方法上,我们针对刚才提到的两个问题做了改进。
针对全局刚性对齐的问题,我们按 Mask 做局部对齐并只计算局部误差,就可以比较客观的反映出来鼻子、嘴型、脸型、眉毛等的效果。
针对对应点错位的问题,我们引入了逆向 non-rigid deformation 更新对应点关系,可以理解为在找对应点关系的时候是一个双向过程,这样可以使得对应点关系找得更准。我们也做了一些实验,来验证这两个改进,发现有很大的帮助。

根据这个方法,我们对现有的能找到开源代码的单张照片的 3D 人脸重建算法做了一个非常详细的评测,过程中也发现了一些有趣的观察:
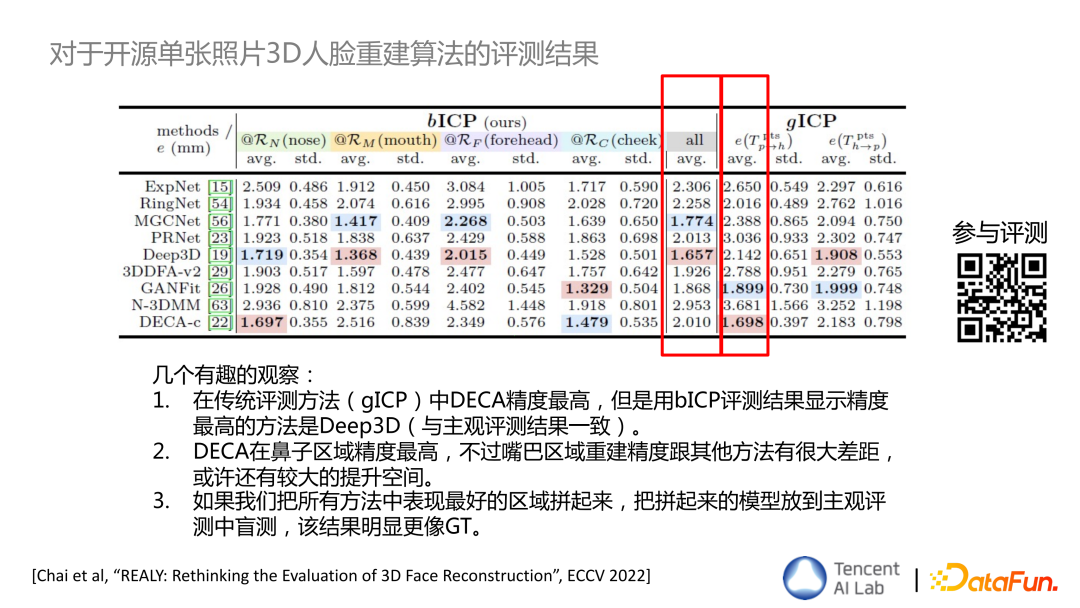
这项工作已经发表到今年的计算机视觉顶会 ECCV 上,相关的数据集和代码也已经公开,欢迎大家扫码关注。以上就是我今天分享的内容,谢谢大家,欢迎大家提问。
—
04 问答环节
Q1:想问一下关于阴影的处理,是通过真么样的思路?是有监督还是无监督的方法来做?
A1:首先是 moldel base delighting 的过程,会估计出球谐光照,根据估计出来的光照去处理 delighting,这一步骤会导致脸部区域不是很均匀,有些高光也无法去掉;其次是 fitting 的过程,会去掉不均匀的部分;再进行 refinement 的过程,使用比较均匀的 UV 贴图,可以进一步的把光照做的比较平。所以是经过了以上三个步骤的处理使得光照比较均匀。
Q2:头发是如何建模及渲染的?
A2:头发是以挂件的形式挂上去的,是调用事先人工建模好的头发库,渲染也是在Groom 里用 UE4 渲染。
Q3:口腔内部如何建模?
A3:目前是没有建模的,但是我们这个拓扑里口腔是一个包络,有了这个腔体,可以往里面放牙齿和舌头的挂件。
Q4:你们的数字人做的比其他算法更真实,主要的差异是什么原因导致?几何模型、皮肤纹理更真实?还是贴合性?
A4:传统的 3D 人脸重建我们只关注人脸局部的一个区域,但是做数字人来讲,这还是远远不够的。一是我们重建的 shape 跟真人非常贴合;二是纹理的合成,我们构建了一个比较高质量的的纹理数据集,通过这些数据集训练 refinement 可以得到很精细的毛发等的相关细节;三是我们把整个完整的流程和管线都做的比较细致;四是有在用工业界的渲染管线来渲染数字人。以上就是我们的数字人更真实的原因。
今天的分享就到这里,谢谢大家。
|分享嘉宾|
暴林超 博士
腾讯AI Lab 专家研究员
香港城市大学博士,目前在腾讯AI Lab担任T13级专家研究员及虚拟人算法组组长,主要从事3D虚拟人相关的算法研究和落地,在
CVPR/ICCV/ECCV/TPAMI/TOG/TIP等国际顶级会议和期刊发表文章30余篇,谷歌学术总引用量超过2000。
|关于DataFun|
专注于大数据、人工智能技术应用的分享与交流。发起于2017年,在北京、上海、深圳、杭州等城市举办超过100+线下和100+线上沙龙、论坛及峰会,已邀请超过2000位专家和学者参与分享。其公众号 DataFunTalk 累计生产原创文章800+,百万+阅读,15万+精准粉丝。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。