
本文将涵盖在 Meta 旗下的应用程序包括 Messenger、Instagram、Facebook 和 WhatsApp 中为用户提供可靠且高质量的音频体验所需的要素,以应对各种设备和网络条件的多样性。除了介绍通常被提及的增益控制、回声消除、噪音抑制和编解码器等组件外,演讲还将深入探讨一个较为陌生但可能更重要的音频可靠性问题。此外,演讲还将探讨在元宇宙中提供音频的新挑战。
来源:SYSTEMS @SCALE SUMMER 2023
链接:https://atscaleconference.com/videos/real-time-audio-at-meta-scale/
主讲者:SRIRAM SRINIVASAN
内容整理:王睿妍
引入
时至今日,我们已经见证了设备、移动性和无所不在的通信方面的巨大进步。与此同时,这些进步也带来了新的挑战。视频通话使得蜂窝网络出现拥塞和不同覆盖范围的通话更加常见。麦克风和扬声器相邻距离很近,低音量和相关影响因素引入了非线性,使回声成为目前更难解决的问题。经过二十多年的熟悉,用户对质量有了更高的期望。

主要内容
会议安排
接下来将介绍在元尺度上处理最困难的音频挑战方法,并深入探讨音频的可靠性,确保音频实际工作。最后我将展望未来和 RTC 中最令人兴奋的领域之一,即元宇宙中的大型群组通话。

高质量通话的基本要素
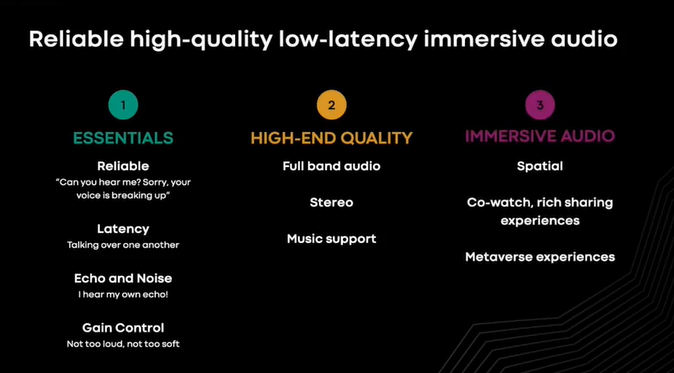
在开始大型沉浸式通话之前,首先要保证得到了正确的基本要素。通话中过长的延时会降低交互性,导致参与者频繁地重复确认通话内容,这不是自然的对话。许多呼叫通过低带宽连接进行,即使最好的 WiFi 网络也会出现拥塞,因此 robust packet loss(指数据通信中对丢包(packet loss)具有鲁棒性或健壮性的特性或算法)也是很重要的一个因素。为避免背景噪音和自己的声音回响,需要全双工、高品质的声学生态消除和非平稳的噪音抑制。全波段立体音频的提供使我们离实现高质量体验的目标更近一步。这一目标的下一步是实现身临其境的音频体验,如特殊音频,这是创造身临其境魔力的关键。
音频工作已经被研究了几十年,为什么这个问题仍是一个挑战呢?这是由于麦克风和扬声器的特性、他们之间的耦合、房间的混响、背景噪音、嘴和麦克风之间的距离,他们都有很大的不同,这与在单个设备上构建音频管道非常不同,我们必须迎合各种各样的设备。为了在我们的规模上提供良好的体验,我们的解决方案及其质量需要从低 CPU.低速率连接和一端的设备扩展,在频谱上最现代的 5G 手机在另一端。我们需要这样做以便我们可以根据用户的特定设备和网络为他们提供良好的体验。更重要的是,用户对音频的容忍度非常低,由于网络的影响或干扰,即使是轻微的断电或噪音也有能非常让人讨厌。
音频处理管线
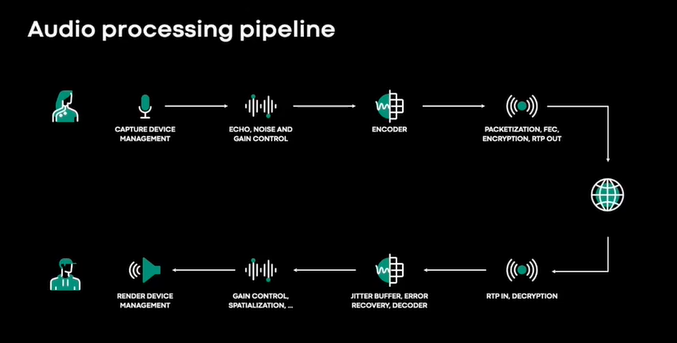
- 无论是通过移动设备、笔记本电脑还是浏览器拨打电话,亦或是通过蓝牙外设耳机作为扬声器拨打电话,自动增益控制器对于保持正常的音量水平都是必不可少的。
- 低比特率高质量编码是近年来备受关注的另一个领域。
- 增加了冗余以提高数据包丢失弹性,加密后作为 RTP 数据包通过网络发送。
- 在接收器组件上(例如缓冲器和解码器等),它们一起工作以补偿分组到达时间分组规律的变化。
这样就可以获得低延迟、平滑的音频播放。在本次演讲中,我们将重点关注一个鲜为人知但很重要的组件,即音频设备管理,在解决了音频可靠性和无音频的问题,下图是放大后的音频设备管理组件。
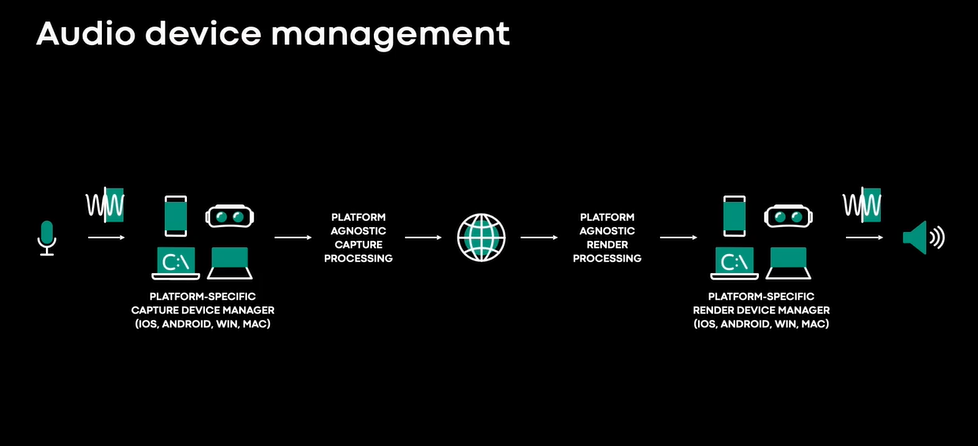
该组件负责将音频样本从麦克风送到采集管道,并从渲染管道送到扬声器。该组件依赖于平台,它抽象出音频捕获和渲染的操作系统细节,以便以与平台无关的方式构建更改级别的组件。回声和噪声的控制组件可以在实验室中开发和测试,使用公开可用的音频文件和网络跟踪的代表性数据库。
音频设备管理
另一方面音频设备管理也十分困难,它是很容易影响到我们规模的数百万用户的一个边界案例。我们需要创新,使用遥测技术来识别问题并找出问题的根源,这样就可以修复它们,然后在生产中进行测试。我们对结束加密隐私的承诺意味着这必须在没有任何音频数据或任何用户身份的情况下完成,我们建立了一个完全符合隐私的框架,以便在通话结束时实现这一目标。
解决“听不到音频”的问题
对于用户表示他们听不到音频或听不到声音的呼叫,可以用自动化框架分析遥测数据,以确定处理链上的潜在原因。
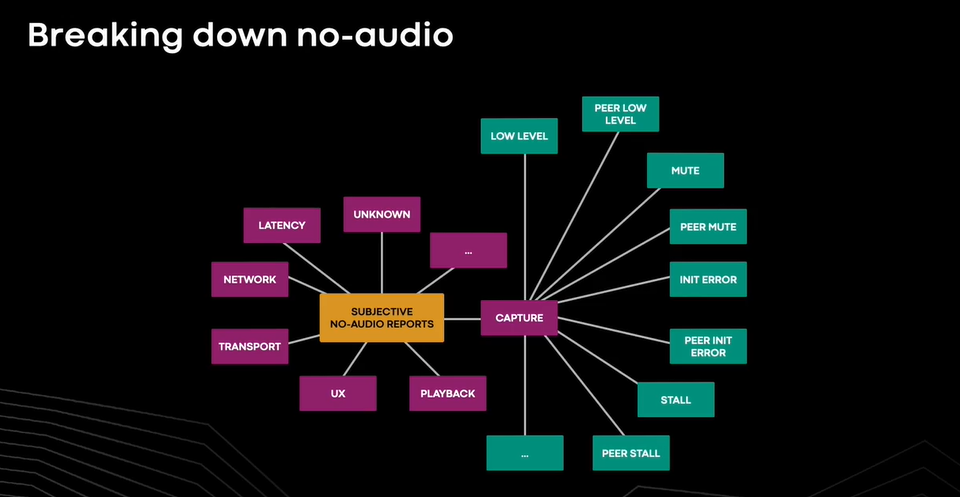
音频问题可能会在我们看到的管道中的多个地方引入。第一个故障点是捕获设备管理模块无法传送音频样本,考虑到用户群中和外围设备的多样性,这是一个常见的故障点。虽然后续的软件组件,如 echo、 noise control、 codex 等也可能引入故障,但它们不太频繁,并且不依赖于设备。下一个大的故障源与通过网络发送的数据有关。音频数据包可能会由于数据包丢失而丢失,或者意味着永远不会到达另一端。与捕获端类似,接收端也是 no-audio 问题的来源。假设1%的电话用户报告了 no-audio 问题,我们现在能通过识别和记录不同处理阶段(捕获、回荡、网络传输、ux 等)的错误代码将这1%的用户问题分解为刚刚谈到的类别。之后每个类别被分解成可以进一步修复的子类别。
在我们的使用经验中,总是有非零百分比的问题被归类为未知原因,有时倾向于对调查选择做出不同的解释。例如由于瞬时网络伪像而只有瞬时音频丢失的问题被归类为无音频。这些仍是需要解决的重要问题。
展望
在传统的视频会议中,每个参与者都在不同的房间里,当我们看到每个人都位于这些不同的环境中时,在某种程度上,我们的心理模型适应了这种结果。然而在 meta 环境中,我们的目标是提供在同一个共享空间的魔力,对各种音频失真的容忍度非常低。由于参与者从他们自己的房间里加入通话,每个人都有自己独特的声学特征,需要补偿上述讨论的所有问题,如回声、噪声、延迟等,因此具有新的重要性。我们需要一种智能的、混合的基于邻近性的方法,在可扩展性和质量之间取得良好的平衡。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。