
在当今快速发展的技术环境中,虚拟通信已成为新常态。虚拟现实 (VR) 和增强现实 (AR) 的出现彻底改变了用户见面和聚会的方式。随着视频会议 (VC) 软件的广泛采用,远程通信变得比以往任何时候都更容易、更容易访问。
作者:RAMAN WALIA / SHREYAS BASARGE
演讲题目:REAL-TIME CALLING WITHIN METAVERSE
原文:https://atscaleconference.com/real-time-calling-within-metaverse/
AR 和 VR 环境提供更加身临其境的体验,在虚拟世界中提供物理存在感。这会带来更具吸引力和更有意义的体验,从而实现更好的协作和构思。此外,AR/VR 环境提供了对设置的更高级别的控制,允许用户自定义他们的环境以满足他们的需要。
在 VR 中,与朋友一起看电影、玩游戏、讨论设计规范、在白板上协作,同时相距数百英里,这些都是真实存在的。彼此相处从未如此简单。
但是,我们如何以这种方式出现在场呢?
人类代表
在虚拟世界中存在的最重要方面是人类表现。在传统的通话场景中,这是通过二维 (2D) 视频完成的。但是 2D 视频并不直接适用于元宇宙:首先,因为在被头显遮挡的情况下,并不总是能够捕捉到用户面部的视频,其次,因为我们需要更深入地了解用户的动作在三个维度上,这样他们就可以与虚拟环境互动。
我们一直在研究一系列人类表现形式,从卡通化身到逼真化身。我们可以大致将其分为三种形式:
- 风格化头像
- 逼真的头像
- 体积化视频
对于这些表示中的每一个,我们都希望用户的设备能够捕获特定的表情数据。这可以通过头显上的内向摄像头、眼动追踪、基于麦克风音频的口型同步等来完成。
风格化头像

这些是相对低保真的卡通化身。当实时通信 (RTC) 会话开始时,所有参与者共享他们的头像资产。骨骼运动实时流式传输,化身在接收方重新创建。
逼真的头像
这些非常高保真度的头像与现实几乎没有区别。系统为通话中的每个参与者创建一个专门的编解码器。在 RTC 会话开始之前共享资源、纹理和编解码器。神经网络 (VAD) 用于将面部表情数据实时压缩为中性嵌入,并通过网络发送。使用最先进的 ML 技术,我们能够拥有 30 FPS 的逼真化身,消耗低至 30 KB。
体积视频
这些是保真度最高的化身,通过它们可以准确地反映出一个人的形象。人的三维捕获作为 RGB 和深度的组合通过网络发送。虽然标准的 2D 编解码器可用于 RGB 分量,但需要开发特殊的编解码器来压缩深度。RGB 和深度分量还需要在接收器端进行完美同步和拼接,以呈现能够准确代表虚拟环境中人物的场景。同时实现所有这些组件对于创建真正身临其境且逼真的虚拟体验至关重要。这种方法占用大量带宽,需要大量后处理才能消除压缩伪像。
根据设备限制、网络质量和用户活动,我们可以选择使用哪种形式的人类表示。在非 RTC 活动消耗系统资源和/或有大量参与者的类似游戏的设置中,我们可能会选择程式化的化身。它们在计算上是最便宜的,并且在休闲活动会话中不会感到不合适。然而,在工作环境中,参与者在白板上进行协作,我们可能希望使用逼真的头像。
世界状态
我们已经讨论了我们如何在虚拟空间中代表人类。现在我们需要为用户提供与周围环境和远程参与者进行交互的工具和功能。这就是实时世界状态发挥作用的地方。

协作虚拟环境需要一个强大的系统来管理参与者之间共享的对象。一个网络化的共享对象堆栈可以用以下层的形式进行推理:
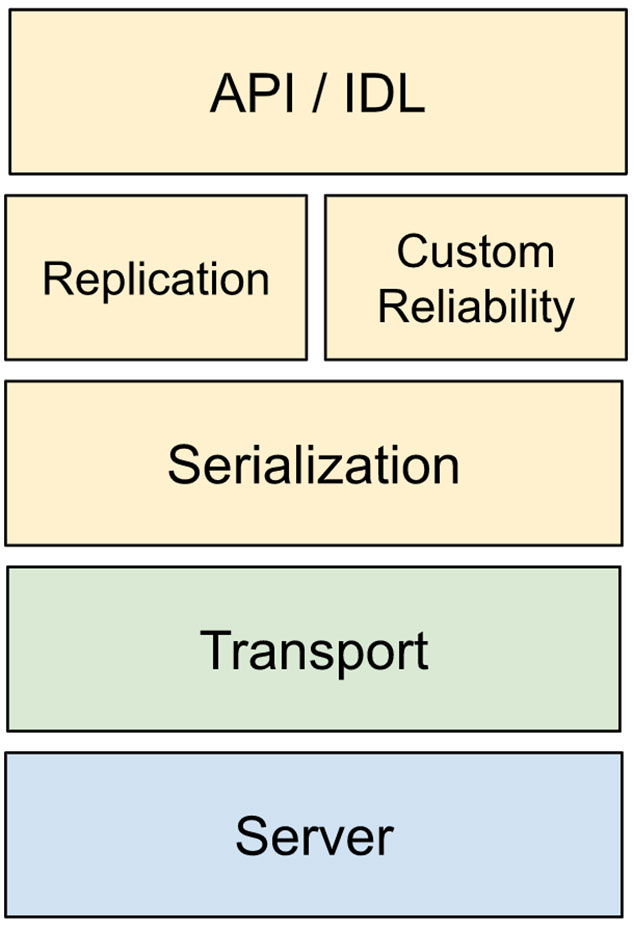
- API / IDL:开发人员定义/修改/读取其对象状态的符合人体工程学的方式。
- 复制:使用低级传输 API 在参与者之间复制对象的逻辑。
- 自定义可靠性:实现特定于状态的自定义可靠性和排序的逻辑,以避免任何浪费的重试。
- 序列化:以最紧凑的方式将对象高效序列化为有线格式的机制。
- 传输:低级传输 API,用于发送和接收具有可配置特性(例如可靠性、延迟、拥塞控制等)的数据包。
- 服务器:选择性转发或扇出数据包所需的服务器端基础设施。
为了向开发人员提供最符合人体工程学的体验,系统应该抽象出该架构的所有内部复杂性。我们通常希望他们使用为他们的对象定义模式的心智模型。对象是字段的集合。可以在整个会话期间创建、修改和销毁对象。底层框架负责通过网络实时传输这些突变。
随着会话中共享对象数量的增加,我们需要想出创新的方法来限制同步此数据所消耗的网络带宽量。可能的方法包括计算增量、有效利用视野以及使用较低的 FPS 进行插值和外推。
多个参与者可以同时修改对象。为了解决冲突的更新,我们需要建立一个所有权框架。参与者完全拥有的对象只能由该参与者改变(例如,化身持有的蝙蝠只能由该对象改变)。其他对象的所有权可能会在整个会话期间转移。某些世界对象可能根本没有所有者,而是归服务器所有。
选择的网络拓扑会影响围绕隐私、性能和开发人员体验的权衡:
无状态服务器
通过这种选择,服务器不维护任何状态,只负责转发数据包。其中一个客户被选为主要客户并仲裁冲突。服务器可以根据网络特性改变主客户端。主要客户端引起的网络问题会影响所有其他客户端。该模型允许对用户活动进行端到端加密。
状态服务器
在这里,服务器维护状态并且是所有共享世界对象的真实来源。虽然此模型不能支持端到端加密,但更容易识别和调试。它还表现得更好,并且可以容忍参与者流失。
展望未来
展望未来,我们需要沿着两个轴心进行创新:
- 现实主义
- 规模
现实主义
上面,我们讨论了关于人类代表的各种权衡。随着设备变得越来越小(例如,AR 眼镜或 VR 头戴设备)并且预计会持续更长时间并且具有更严格的热要求,在它们的限制下工作将对推动现实人类表现的极限提出挑战。
尽管如此,可以通过结合优化机器学习 (ML) 模型来实现改进,这些模型为设备上的头像生成提供支持,并将部分渲染卸载到云端。后者对可接受的延迟设置了更严格的界限(大约 50 毫秒),因为呈现的内容需要对用户的实时移动(例如头部旋转)做出快速反应。这可以通过分层方法部分缓解,其中服务器仅部分渲染场景,设备对用户的实时移动进行最终重新定位和校正。
规模
在Metaverse中,RTC体验的北极星是为类似音乐会的大型活动提供支持,在这些活动中,成千上万的人可以同时在场并进行实时互动。然而,这在产品和技术方面都带来了挑战。
在产品方面,我们需要弄清楚如何将不对称性融入这些互动中。让数以千计的人同时与对方交谈肯定是行不通的!一个更容易接受的设置可能是让某些关键参与者扮演广播员的角色,就像音乐会上的歌手,而其他参与者(人群)的影响范围较小。
在技术方面,处理成千上万的参与者需要重新考虑用于媒体转发的传统服务器架构。我们需要一个分布式设置和更多的计算能力,以便我们可以自定义每个用户接收的媒体,以考虑到所需的细节级别(例如,来自较远参与者的低沉环境噪音与附近人的清晰音频) . 我们还需要降低延迟,使服务器端媒体处理能够实时响应用户的移动。
总的来说,元宇宙创造存在感的可能性是无限的。RTC 是将用户体验编织在一起的结构。有许多广泛而深入的技术挑战需要解决,现在是从事 RTC 工作的工程师的最佳时机。
本文为原创稿件,版权归作者所有,如需转载,请注明出处:https://www.nxrte.com/jishu/yinshipin/27272.html