
随着语音继续成为人机交互的新前沿,许多企业可能会寻求提升技术水平,为消费者提供更可靠、更准确地识别用户所说内容的语音识别系统。想一想:更高的语音识别质量可以使人们与他们的应用程序和设备交谈,就像他们与他们的朋友、他们的医生或其他与之互动的人交谈一样。
这开辟了很多应用场景,从驾驶员的免提应用程序到跨智能设备的语音助手。此外,除了向机器提供指令外,准确的语音识别还可以在视频会议中提供实时字幕、从实时和录制的对话中获得洞察力等等。自谷歌云推出 Speech-to-Text (STT) API 以来的五年中,越来越多的客户对该技术的热情不断提高,该 API 现在每月处理超过 10 亿分钟的语音。这相当于听 Wagner’s 的 15 小时 Der Ring des Nibelungen 超过 110 万次,假设每分钟说大约 140 个单词,那么每个月就足以转录近 460 万次哈姆雷特(莎士比亚最长的戏剧)。
这就是为什么今天,谷歌云宣布推出适用于 STT API 的最新模型。作为语音技术的一项重大改进,这些模型可以帮助提高 STT 支持的 23 种语言和 61 种语言环境的准确性,帮助您通过语音更有效地与客户建立大规模联系。
新模型可提高准确性和理解力
这种新的语音识别神经序列到序列模型的努力是近八年旅程中的最新一步,需要大量的研究、实施和优化,以在不同的用例、噪声环境中提供最佳质量特征、声学条件和词汇。新模型的基础架构基于尖端的 ML 技术,能够更有效地利用语音训练数据来查看优化的结果。
那么这个模型与目前生产的模型有什么不同呢?
在过去的几年中,自动语音识别 (ASR) 技术一直基于单独的声学、发音和语言模型。从历史上看,这三个单独的组件中的每一个都是单独训练的,然后组装起来进行语音识别。
此次宣布的构象模型基于单个神经网络。与训练需要随后组合在一起的三个单独模型相反,这种方法提供了更有效地使用模型参数。具体来说,新架构增加了带有卷积层的转换器模型(因此得名 con-former),使我们能够捕获语音信号中的局部和全局信息。
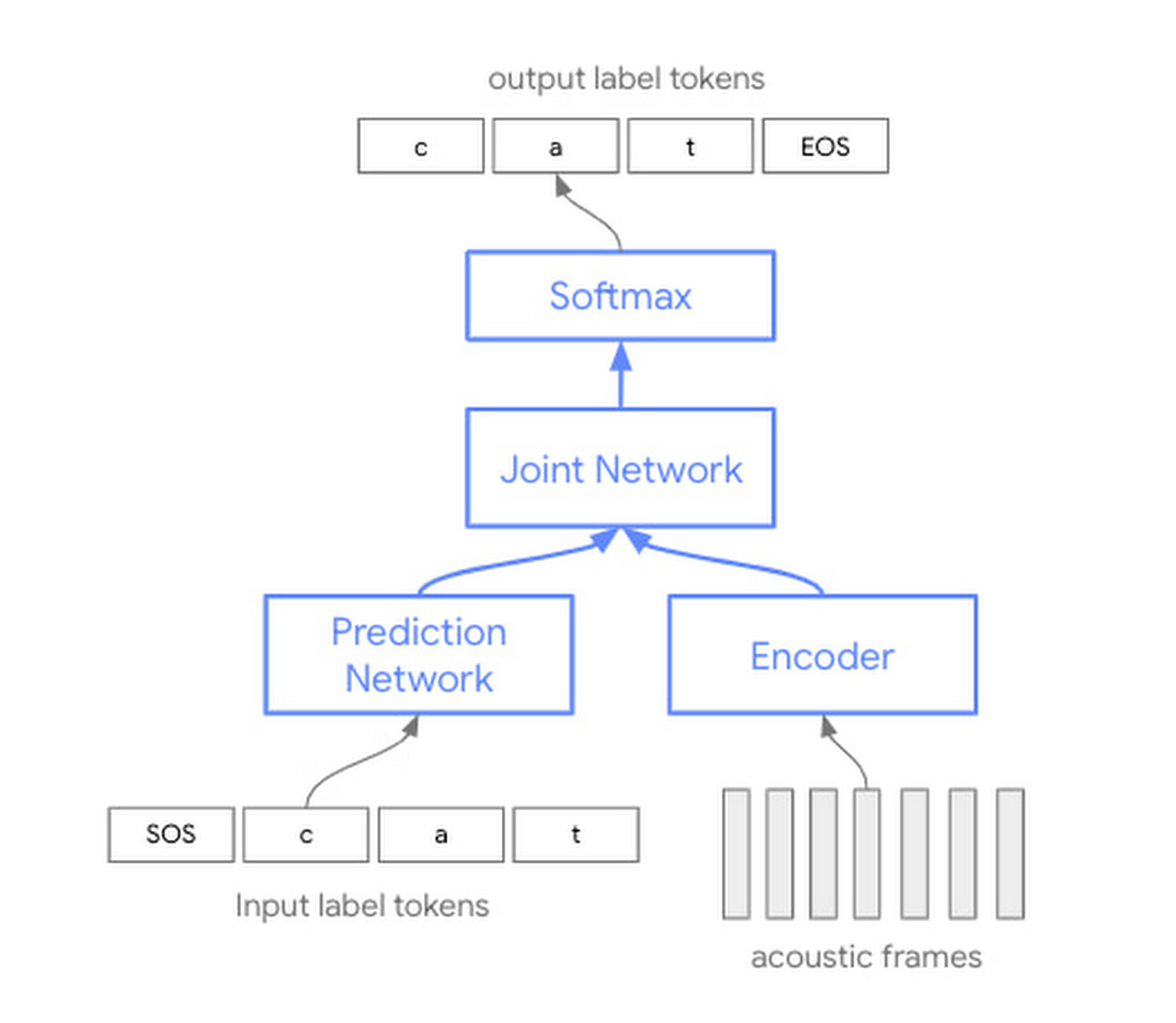
企业和开发人员都将在使用 STT API 时看到开箱即用的质量改进,虽然始终可以调整模型以获得更好的性能,但无需任何初始调整即可感受到这种新架构的好处。通过该模型对不同类型的语音、噪声环境和声学条件的扩展支持,开发人员可以在更多上下文中产生更准确的输出,更快速、轻松、有效地将语音技术嵌入应用程序中。
如果您正在构建用户与其智能设备和应用程序交谈的语音控制界面,这些改进可以让您的用户更自然地用更长的句子与这些界面交谈。无需担心他们的语音是否会被准确捕捉,您的用户可以与他们交互的机器和应用程序建立更好的关系,以及与您的企业作为体验背后的品牌建立更好的关系。
新模型的早期采用者已经看到了好处。“Spotify 与 Google 密切合作,为我们的移动应用程序和 Car Thing 的客户带来我们全新的语音界面‘Hey Spotify’。更多用户享受到了 Spotify 在 NLU 和人工智能方面的出色服务,”Spotify 技术硬件产品负责人 Daniel Bromand 说。
如前所述,为了在保持现有模型的同时支持这些模型,STT API 还在新标识符下引入了这些模型——“latest”。当指定“latest long”或“latest short”时,可以访问到最新的conformer模型。“Latest long”是专门为长篇自发语音设计的,类似于现有的“视频”模型。另一方面,“Latest short”在命令或短语等简短的话语上提供了很好的质量和延迟。
谷歌云将致力于不断更新这些模型,以便为用户带来 Google 的最新语音识别研究。这些模型的功能可能与“default”或“command_and_search”等现有模型的功能略有不同,但它们都具有与其他 GA STT API 服务相同的稳定性和支持保证。有关确切的功能可用性,请查看文档。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
