
0. 导言
本文将介绍我们近期收稿于IEEE TWC的工作《Task-Oriented Communication for Edge Video Analytics》。在这篇文章中,我们提出了一种面向任务(Task-oriented)的通信方式,以减小边缘视频分析中的延迟。
文章发布于:https://ieeexplore.ieee.org/abstract/document/10258036
作者主页:https://shaojiawei07.github.io/
1. 研究背景
近年来,随着AI技术和移动设备的不断发展,智能视频分析应用在各个领域蓬勃发展。这些基于深度学习(Deep learning)的应用,能够实现实时的视频流分析,对图像进行识别、跟踪和推断。但是,AI模型往往有很高的计算复杂度。想要在资源受限的网络边缘部署视频应用,我们还面临许多挑战。
边缘推断(Edge inference)是一种可行的解决方案。通过将一部分计算需求(如神经网络推断)由移动设备转移到边缘服务器上,我们可以减少设备的计算时延和资源消耗。但是,这样的系统需要将神经网络的中间结果从设备端传递给服务器端。我们希望在保证视频分析性能的同时,尽可能降低通信延迟。所以,一个重要的问题是:如何减少传输过程中的信息冗余。
面向任务通信(Task-oriented communication)能提供合适的解决方案。相较与传统的面向数据通信(Data-oriented communication),新的通信范式旨在识别并传输真正与任务相关的信息,而不追求在接收端完整地重建数据。这一种设计思想为大幅减小通信延迟带来了可能。
2. 系统架构
如图1所示,我们考虑网络边缘有多个摄像设备。他们可以连接到同一服务器做边缘推断。每个设备都会使用一个特征提取器去识别任务相关的信息,并把他们编码后传递给边缘服务器做进一步分析处理。我们的方法基于信息瓶颈(Information bottleneck)理论,它从视频帧中抽取出任务相关特征,并使用熵编码的方式对这些特征进行编码。由于视频数据存在时序冗余性,我们在编码的时候会把之前帧的特征作为边信息(side information),以进一步减少通信代价。更多的技术细节可以参考文章的第二第三节。
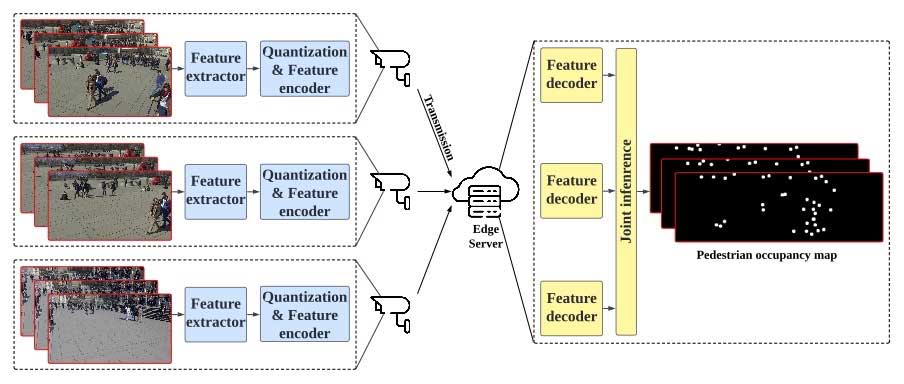

3. 实验结果
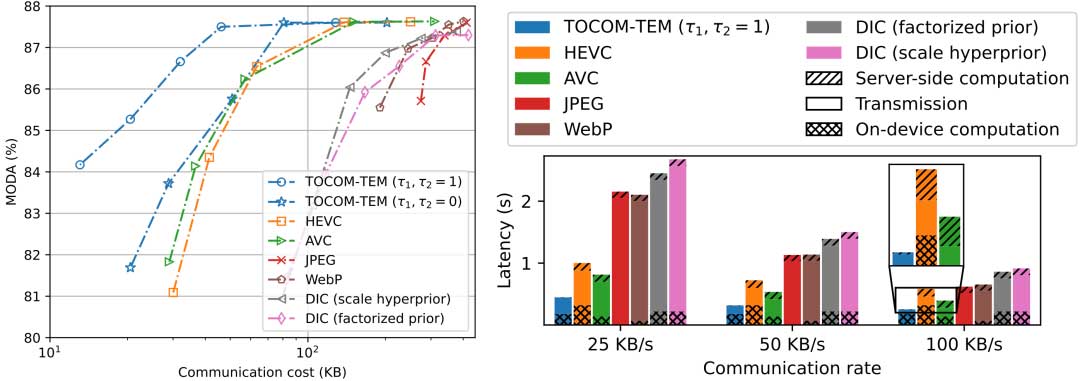
我们在行人位置检测任务中测试了各种的方法的性能。实验基于WILDTRACK数据集。如图2所示,这个数据集包含了7个不同角度摄像头对同一区域进行拍摄的视频数据。视频分析任务是检测行人在这片区域里的位置(Pedestrian occupancy map)。我们选择多目标检测准确率(MODA)作为性能指标。

在实验中,我们选择了图像压缩算法,包括JPEG、WebP、Deep image compression(DIC),和视频压缩算法,如AVC和HEVC,作为对照组进行比较。实验结果如图3所示。可以看到,我们的方法(TOCOM-TEM)实现了最好的检测性能以及通信开销间的权衡关系。此外,在不同的通信速率的情况下,我们的方法都实现了最小的视频推断延迟。
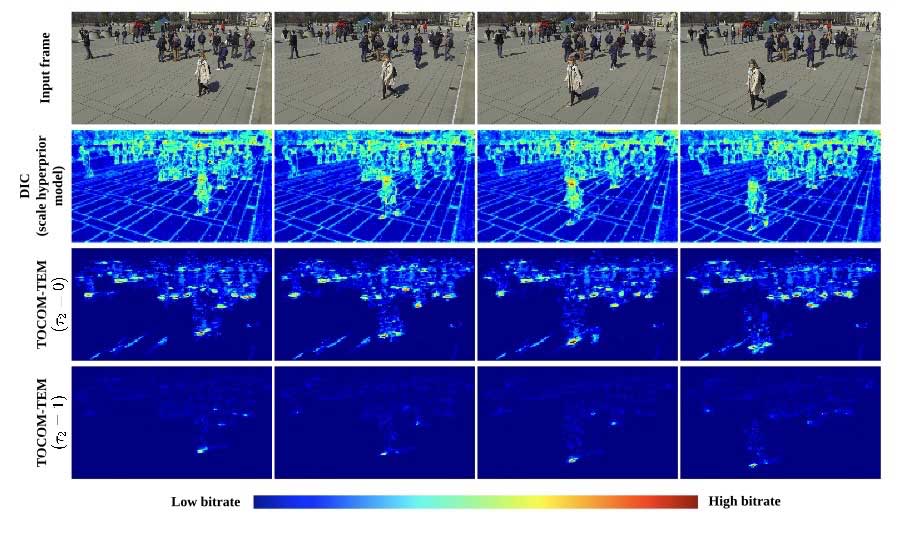
除此之外,我们在下图4中可视化了不同区域编码的比特量。可以观察到,传统的面向数据的图像压缩方式(DIC)会用大量比特去表示图片中的纹理和背景信息。但在我们的面向任务的通信方式中,比特主要被用于表示行人脚部的位置。这可以在减小通信带宽的同时,很好地完成行人位置检测任务。
4. 总结
在这个工作中,我们提出了一种面向任务的通信策略,它有效解决了边缘视频分析中的高延迟问题。我们期待在未来的研究中,这样一种策略可以赋能更多的边缘智能应用。
5. 参考文献
[1] J. Shao, X. Zhang, andJ. Zhang, “Task-oriented communication for edge video analytics,” IEEE Trans. Wireless Commun., to appear.
[2] T. Chavdarova, P. Baqué, S. Bouquet, A. Maksai, C. Jose, T. Bagautdinov, L. Lettry, P. Fua, L. Van Gool, and F. Fleuret, “Wildtrack: A multi-camera HD dataset for dense unscripted pedestrian detection,” in Proc. Conf. Comput. Vision Pattern Recognit., Salt Lake City, UT, USA, Jun. 2018, pp. 5030–5039.
[3] Y. Hou, L. Zheng, and S. Gould, “Multiview detection with feature perspective transformation,” in Eur. Conf. Comput. Vision, Aug. 2020.
作者:SHAO, Jiawei
编辑:LIN, Zehong
原文:https://mp.weixin.qq.com/s/HwPGTK3FUyXwAryi6JFqIQ
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。