
语音识别系统应该足够强大,能够适合所有人群——包括具有不同说话风格、口音和其他特征的人群。为了衡量自动语音识别(ASR)工具在不同人口群体中的表现,人工智能从业者需要多样化的语音数据。为了与开放科学方法保持一致,Meta发布了一个以公平为导向的评估数据集,其中包含来自不同群体的同意付费参与者的音频命令。除了数据集之外,Meta还开发了一种隐私保护方法,通过使用无监督聚类方法来提高自动语音识别系统的鲁棒性和公平性。


这项技术使研究人员能够提高ASR性能,而无需依赖与人口统计特征相关的数据或代表某人语音的数据(称为说话人嵌入)。Meta提出的算法不是根据说话者的人口统计信息(例如年龄组或性别)划分数据集,而是在话语级别对语音进行聚类。单个集群将包含来自不同发言者群体的相似话语。然后,Meta可以使用各种集群来训练模型,并使用公平数据集来衡量模型如何影响不同人口群体的结果。聚类是使用无监督学习来执行的,利用算法来分析和分组未标记的数据集,而无需人工干预。
在测试过程中,Meta观察到以这种方式训练的模型提高了所有测量的人口群体的语音识别准确性,特别是不同口音的准确性,这些口音在社会语言学中被认为是一个国家、地区、地区所特有的语言的发音方式。虽然Meta提出的算法是使用英语数据构建的,但仍希望这些方法也可以扩展到其他语言。
Meta继续引入此类研究并产生新的创新,以支持强大、公平和包容的人工智能系统。未来,建模技术和数据集都可以帮助改进自动语音识别系统的用例,包括人工智能助手、翻译工具等等,为全球数十亿人提供各种语言的支持。
数据聚类如何保护隐私
由于不需要人类注释者来标记集群,因此这个过程意味着无法深入了解每个集群的内容以及为什么某些话语被分组在一起。
然后,在去识别化的、公开的Facebook英文视频上训练模型。它是在两个数据集上进行评估的。第一个是从ASR数据供应商收集的去识别化数据集,其中包括867位说话者的48,000条话语。发言者可以选择跨人口统计类别进行自我识别,例如年龄、性别、种族、英语口音以及第一语言或家庭语言。第二个数据集是Casual Conversations v1,这是Meta于2021年构建并公开的转录语音数据集。该数据包括美国参与者自行提供的年龄和性别,以及注释的明显肤色类别。(在我们完成研究后,Meta 发布了Casual Conversations v2,这是一个扩展数据集,其中包括七个国家的人们的其他自我识别和注释类别的视频记录。)
首先,Meta将训练数据分割成10秒的块。然后,提取每个片段的话语级嵌入。之后,Meta使用这些嵌入训练用于降维的主成分分析模型,并使用众所周知的K均值算法对数据进行聚类。
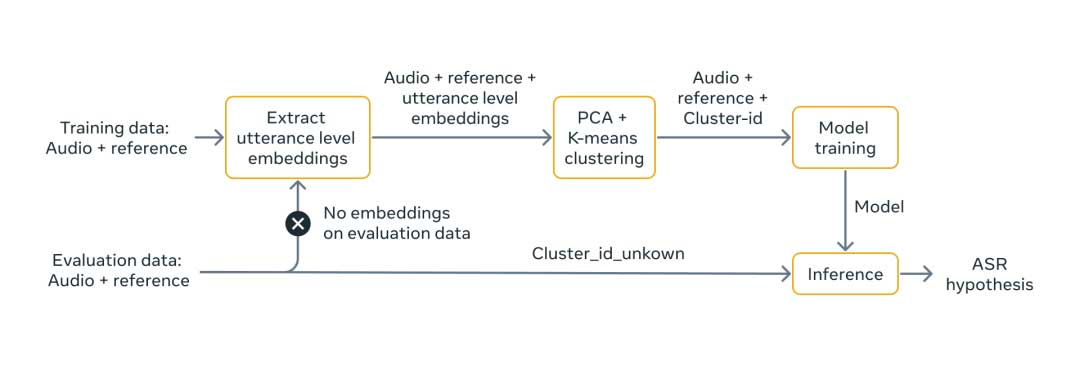
由于大多数参数由所有集群隐式共享,因此语音识别模型学习在不同集群之间进行泛化。我们通过分配将当前数据采样到“未知”簇的概率来使用“屏蔽”策略。这确保了在训练期间,模型将尝试为未知域推断正确的聚类,从而使其更加稳健——即使正确的聚类ID丢失也是如此。在推理时,为了避免对传入数据运行说话者识别模型(从隐私和延迟的角度来看这都会出现问题),Meta为测试数据提供了一个“未知”的集群ID。由于Meta提出的算法不依赖于人口统计信息,因此在生产应用程序中使用它要容易得多。
所提出算法的结果如何叠加
实验结果表明,Meta的方法提高了评估数据集中所有人口群体的模型性能,尽管迄今为止最大的收益是在口音的包容性方面。我们研究论文的结果表明,我们不必牺牲整体性能来提高模型的公平性。
基于集群的模型提高了所有年龄段的表现,其中66至85岁年龄段的人获益最大,这通常是ASR训练数据中代表性不足的群体。由于该群体在训练数据中代表性不足,因此没有明确的方法通过正常的数据收集和训练来改进该群体的模型。总体而言,根据不同群体(例如年龄、性别、种族以及母语与非母语)的单词错误率,Meta的结果显示,经过听写、消息传递和语音命令训练的ASR模型相对提高了10%使用Meta提出的方法进行训练。
Meta还发现,地理和自我认同的种族标签不能很好地表明口音或说话者的变异性。因此,Meta建议无监督聚类比使用元数据来训练的公平性和鲁棒性更好。
Meta的开源数据集
当前的语音识别公共数据集往往并不专门关注提高公平性。Meta的数据集包含595名美国人录制的大约27,055条话语,这些人付费录制并提交自己发出命令的音频。他们自我识别了自己的人口统计信息,例如年龄、性别、种族、地理位置以及是否认为自己以英语为母语。
该数据集中包含的口头命令分为七个领域,主要服务于语音助手用例——音乐、捕获、实用程序、通知控制、消息传递、呼叫和听写——可以支持在这些领域构建或拥有模型的研究人员。为了响应与每个领域相关的提示,数据集参与者提供了自己的音频命令。一些提示的例子是询问他们如何搜索歌曲或与朋友制定计划,包括决定在哪里见面。我们的数据集包括参与者话语的音频和转录。
通过发布此数据集,Meta希望进一步激励人工智能社区继续提高语音识别模型的公平性,这将帮助每个人在使用ASR应用程序时获得更好的体验。
建立更具包容性的模型
Meta相信,引入隐私保护方法来提高ASR模型的清晰度和鲁棒性,将激发人工智能系统在不同的说话条件下为不同的说话者提供良好的服务。这可以包括人工智能助手的语音命令或医疗转录以提供更好的医疗保健。
衡量公平性通常需要对人口统计数据进行分析,以了解人工智能模型是否对所有群体都公平。使用收集到的数据,参与者在不同维度上进行自我认同,是Meta解决衡量公平性和保护隐私之间紧张关系的一种方式。
该算法是Meta长期关注负责任的人工智能的一部分,也是Meta解决公平问题的整体方法的一部分。这个新的公平数据集包含付费参与者的明确许可,而Meta的新方法是构建致力于保护隐私的人工智能系统的众多努力之一。
与此同时,Meta将继续投资构建更加公平和包容的模型,同时保持整体准确性的高标准。
信息源于:Meta
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。