
随着人工智能技术不断发展和应用,大语言模型在各个领域展现出了惊人的潜力和应用价值。其中,结合大语言模型与大型赛事的碰撞产生了独特的魅力,引发了人们对AI智能解说的探讨与关注,大语言模型的应用为赛事解说注入了全新的活力和新鲜感,同时也为观众带来了更加生动和沉浸式的观赛体验。本文将深入探讨AI智能解说的技术、应用和展望。
作者:江利勤 毕蕾
审核:单华琦 邢刚 徐嵩 何志 赵磊
来源:咪咕灯塔
原文:https://mp.weixin.qq.com/s/YuErr1wp6L-H7uIElIre9Q
背景篇
在当今科技迅猛发展的时代,人工智能技术的应用与创新已经渗透到各个领域,并为人类的生活与工作带来了深远的影响。其中,大语言模型作为人工智能技术领域的一大突破,正在展现出惊人的潜力和应用价值。大语言模型不仅在自然语言处理、机器翻译等领域取得了重大进展,而且在体育赛事解说等领域也开始发挥越来越重要的作用。
基本概念大语言模型大语言模型(Large Language Models, LLM)是指拥有庞大语料库训练而成的,融合了各种语言知识和语言规律的人工智能模型。它们在大量的文本数据上进行训练,可以执行广泛的任务,包括文本总结、翻译、情感分析等。大语言模型具备对自然语言进行理解、生成和处理的能力,并能够在各种任务中表现出相当高的水平。行业大模型行业大模型是针对特定行业或领域优化过的大语言模型。这类模型在通用预训练基础上,进一步在行业相关的语料上进行微调,以增强模型对行业特定词汇、术语、场景的理解和处理能力。模型微调模型微调是指在已经训练好的模型基础上,针对特定任务或数据集进行调整,以获得更好的性能。通常情况下,模型微调是在预训练模型的基础上完成的,它可以提高模型在新任务或新数据集上的表现。发展综述
大语言模型的发展经历了几个关键阶段,从最初的基于规则的方法到统计模型,再到深度学习时代的兴起。近年来,随着计算能力的显著提升和大规模语料库的可用性,基于Transformer架构的大语言模型成为了自然语言处理NLP领域的主流技术。以下是大语言模型发展的几个重要节点:
早期阶段:最初的语言模型基于统计方法,如n-gram模型,但受限于数据稀疏性和无法处理长距离依赖。
深度学习时代:随着深度学习的兴起,循环神经网络RNN和长短时记忆网络LSTM开始用于语言建模,能够处理序列数据,但仍然面临梯度消失/爆炸问题。
Transformer架构:2017年,谷歌提出了Transformer架构,利用自注意力[1]机制解决了RNN的局限性,大大加速了训练过程,开启了大规模语言模型的新纪元。
大规模预训练模型:GPT(Generative Pre-trained Transformer)系列、BERT[2](Bidirectional Encoder Representations from Transformers)、T5[3](Text-to-Text Transfer Transformer)等模型相继出现,通过在大规模语料上进行无监督预训练,然后在特定任务上微调,显著提高了NLP任务的性能。
参数规模的扩张:模型参数量从百万、千万迅速增长至数十亿甚至千亿级别,如GPT-3[4]、PaLM、M6等,参数量的增加使得模型能够捕捉到更复杂的语言结构和模式。
接下来,本文将深入探讨大语言模型在体育赛事直播场景的结合AI智能解说的相关技术。
技术篇
大模型越来越普及,近几年国内外各大机构单位纷纷投入大模型的建设,大模型的应用领域也在不断拓展,涵盖了多个行业,比如医疗、法律咨询等,显示出大模型在人工智能领域的重要地位和广泛应用前景。和通用大模型不同,垂类模型训练包含数据准备、模型微调训练、模型部署推理等环节,数据采集与标注为模型提供学习燃料,通过模型微调让大模型对齐人类意图,更能准备完成特定任务,模型量化压缩方便模型在更低的显存资源门槛上部署,模型推理加速是在部署模型后能够提高模型吞吐量和并发量。
数据准备
高质量数据对训练大模型至关重要,数据质量决定模型能力的上限,结合业务场景特点的具体任务数据需要特别构建。智能文字解说能力的输入和输出是文本,需要将提取和转换多源信息统一标准化对齐成文本。
1. 数据采集与预处理
为训练文体大语言模型,构建体育赛事智能文字解说能力,首先需要完成多模态数据处理链工具的研发。从历史足球比赛视频中提取和转换多源信息,包括语音、字幕和关键事件,将真人解说语音、字幕等信息转化为文本,并对核心事件进行标记,为后续模型训练提供高质量数据。
ASR语音转文本
咪咕具备各大体育赛事数据,足球作为大众化的体育项目之一, 增加比赛智能文字解说能力为用户提供新型观赛体验。基于历届足球比赛视频数据,首先提取比赛音频数据,然后使用咪咕“灵犀云”平台先进的自动语音识别(Automatic Speech Recognition, ASR)[5]技术,将历史足球比赛视频中的真人解说语音转换为文本格式。此过程需考虑体育赛事特有的专业术语和语境,以提高转录的准确性。
先从本地获取音频,然后传到“灵犀云”[6]云端,最后识别出文本,就是一个声学信号转换成文本信息的过程,整个识别的过程如图1所示。
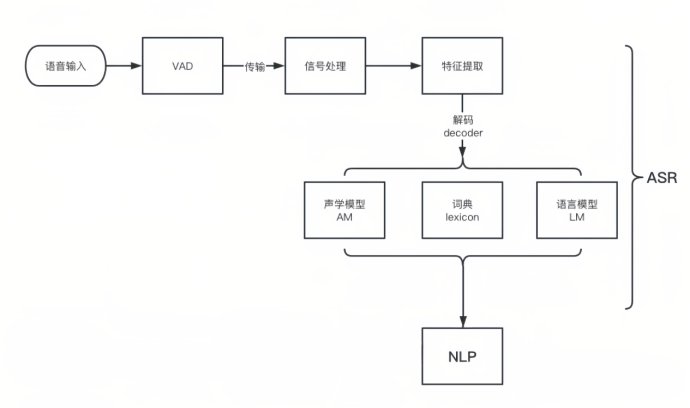

VAD技术:在开始语音识别之前,有时需要把首尾端的静音切除,降低对后续步骤造成干扰,这个切除静音的操作一般称为VAD[7]。这个步骤一般是在本地完成的,这部分需要用到信号处理的一些技术。
特征提取:特征提取是语音识别关键的一步,解压完音频文件后,先进行特征提取,提取出来的特征作为参数,为模型计算做准备。语音信息的数字化,然后再通过后面的模型对这些数字化信息进行计算。
声学模型:声学模型将声学和发音学的知识进行整合,以特征提取模块提取的特征为输入,计算音频对应音素之间的概率。把从声音中提取出来的特征,通过声学模型,计算出相应的音素。
OCR智能识别字幕
对于有解说字幕的比赛视频,可利用光学字符识别(Optical Character Recognition, OCR)[8]技术,识别并转换视频中出现的真人解说字幕为文本数据。OCR技术的核心在于图像处理和机器学习算法的结合。其基本工作流程包括图像预处理、特征提取、字符识别和后处理等阶段。
图像预处理:这是OCR流程的第一步,主要目的是提升图像质量,使后续的字符识别更加准确。预处理步骤可能包括灰度化、二值化、降噪、倾斜校正。
特征提取:从预处理后的图像中提取字符的形状、纹理等特征,这些特征将作为机器学习模型的输入。
字符识别:基于训练好的模型,识别提取到的特征,将其转化为对应的字符。现代OCR系统往往采用卷积神经网络(CNN)、循环神经网络(RNN)和注意力机制等技术来提高识别率。
后处理:对识别结果进行校验和修正,比如通过语言模型修正拼写错误或语法错误,确保最终输出文本的正确性。
核心事件标记
上述三种来源的文本数据整合,并进行清洗,去除重复、无关或低质量的内容,确保数据集的一致性和完整性。基于ASR和OCR的文本数据,从足球比赛中标记处40种核心事件数据,如射门、进球、助攻、越位、黄牌、红牌等,生成带有标签的数据集。
2. 数据增强与标注
在体育赛事智能文字解说能力研发中,高质量的数据是关键。数据增强与标注是提升数据质量和多样性的重要手段。
数据增强
数据增强是一种通过修改现有数据集中的样本来增加训练数据量的技术,它可以有效提高模型的泛化能力,降低对原始数据集的依赖程度。在足球解说数据采集中,不仅需要处理大量的文本数据,还要确保数据的专业性和时效性,以期训练出能够精准捕捉比赛动态、理解体育规则并进行生动解说的模型能力。可以帮助模型学习到更多的场景和语言模式,通过增加数据的多样性和数量,以提高模型的泛化能力和鲁棒性。
提示工程
提示工程(Prompt Engineering)是一种利用精心设计的输入指令引导大型语言模型生成特定类型输出的方法。在体育赛事解说数据增强中,这一技术被用于指导模型生成符合体育语境的解说词。在足球解说数据采集场景中,提示可以包括比赛上下文信息、球员动态、战术分析等关键要素,以激发模型生成相关解说内容。
小样本学习(Few-Shot Learning)
小样本学习是指在有限的数据样本下训练模型,使其能够泛化到新的、未见过的数据上。在足球解说领域,通过提供少量的高质量解说样本,可以利用大模型的泛化能力,学习并生成新的解说内容作为训练数据。在体育解说数据增强中,这种方法有助于模型理解和生成针对特定情境的解说词。
自动化采集数据
利用ChatGPT等大模型,结合提示工程和少样本学习能力,自动化地生成大量的解说数据。这些数据覆盖各种比赛情境,为后续的人工标注提供基础。
提示工程:设计提示模板,根据比赛场景、球员表现等关键信息构建提示,设计具有引导性的提示语,指导模型生成符合要求的足球解说数据。
小样本学习:提供少量样本给模型,使其快速学习特定任务。提供几个已标注的核心事件描述,让模型学习如何生成风格一致的解说文本。向模型输入模板和具体比赛事件,如射门、进球等,获取模型生成的解说文本。
迭代优化采集:通过调整提示的结构和内容,优化模型输出的准确性和多样性。利用模型生成大量足球解说数据,通过对比原数据,确保生成的数据具有多样性和准确性。
人工标注
虽然大语言模型能生成多样化的解说文本,但为了确保数据的准确性和专业性,仍需人工介入进行精细的标注工作。
质量控制:筛选出符合体育规则和语境要求的生成文本,确保解说内容准确反映比赛实际情况。
事件校正:核实并修正模型生成的事件描述,如进球时间、球员名字、统计数据等。
风格调整:确保文本的表达风格和语气与实际解说相符,检查解说语句是否通顺、符合语言习惯,评估解说中情感表达的恰当性和感染力。
体育专家确认
在体育领域,专业知识对于确保数据质量至关重要。体育专家的参与可以确保数据的真实性和专业性。人工标注完成后,数据将提交给体育专家进行最终确认。体育专家将根据以下方面进行评估:
专业性:确保解说内容符合足球运动的专业知识和术语规范。
完整性:检查解说是否覆盖了比赛的关键时刻和重要事件。
创新性:评估解说中是否有新颖的观点和独特的表达方式。
反馈循环:根据专家的反馈,调整模型的生成策略,持续优化数据质量。
模型微调
通用大模型在自然语言处理的通用任务上表现出色,但在特定领域如体育赛事解说上,可能需要额外的领域知识才能达到最佳效果。微调,即在大模型的基础上使用特定领域的数据进行再训练,是提高模型在特定任务上表现的关键步骤。使用预先构建好的问答对数据,在移动研究院“九天13.9B”基座大模型上进行全参数微调和Lora高效参数微调两种方法。
全参数微调
全参数微调是指对大型语言模型的全部参数进行更新,以适应新的数据分布。这种方法涉及到模型的所有权重,包括编码器和解码器的参数。这种方法的优点在于能够充分利用预训练模型的知识,提高模型在特定任务上的表现。然而,全参数微调存在一些缺点,如训练成本高、可能导致灾难性遗忘(Catastrophic Forgetting),即在新任务上的表现提升可能会损害模型在原始任务上的能力。
优点:能够充分利用预训练模型的知识,提高模型在特定任务上的性能。适用于各种任务,具有较好的通用性。
缺点:计算成本高,需要大量的计算资源和时间。容易过拟合,特别是在数据集较小的情况下。
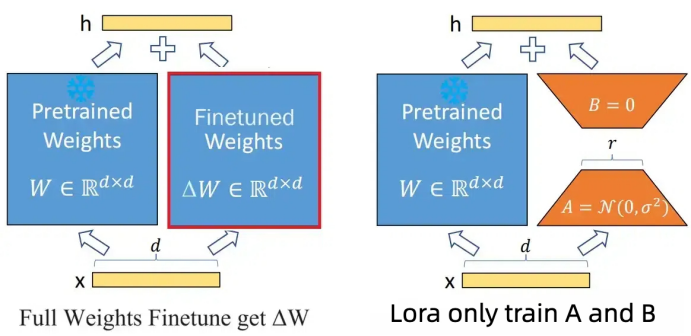
LoRA高效参数微调
LoRA是一种低秩适应(Low-Rank Adaptation)方法,它不是直接修改模型的全部参数,而是仅添加额外的小型可训练矩阵到原有的权重矩阵上。这样做的好处是大幅减少了需要训练的参数数量,同时保持了模型的灵活性和适应性。在实际操作中,微调过程中的原始权重矩阵保持不变,而是通过两个附加矩阵A和B进行微调,这些矩阵作为微调权重矩阵的分解。如图2所示:
对于预训练权重矩阵
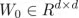
LoRA限制了其更新方式,即将全参微调的增量参数矩阵 △W 表示为两个参数量更小的矩阵和的低秩近似:
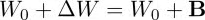
其中,和为LoRA低秩适应的权重矩阵,秩远小于
给定输入,添加LoRA后的输出:
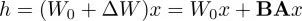
这里将 △h=BAx,便于后续求导计算。
在训练时,原始参数 Wo 被冻结,意味着 Wo 虽然会参与前向传播和反向传播,但是不会计算其对应梯度,更不会更新其参数。
在推理时,直接按上面的式子将 BA 合并到 Wo 中,因此相比原始LLM不存在推理延时。
低秩分解:首先,对预训练模型的权重矩阵进行低秩分解,将其表示为两个低秩矩阵的乘积。这样可以将原始的高维参数空间映射到一个低维空间,从而减少需要微调的参数数量。
参数更新:在微调过程中,只更新低秩分解后的低维参数,而不是原始的高维参数。这样可以大大降低计算成本。
优点:计算成本低,能够在有限的计算资源下实现高效的微调。能够保持模型的性能,甚至在某些情况下提高模型的泛化能力。适用于大规模预训练模型的快速部署和微调。
缺点:需要对模型权重进行低秩分解,可能引入一定的误差。在某些任务上,性能可能略逊于全参数微调方法。
模型量化
量化压缩作为一种有效的模型压缩技术,能够在保持模型性能的同时显著降低模型的存储和计算需求。模型量化是指将模型的权重和/或激活值从高精度转换为较低精度,以减少存储空间需求,加速计算,降低功耗。对于经过微调的大模型而言,量化尤为重要,因为它可以帮助在边缘设备上实现高性能推理,同时保持较高的预测准确性。尝试使用了AWQ和GPTQ是两种具有代表性的量化压缩方法,它们分别采用了不同的策略来实现这一目标。
AWQ量化
AWQ(Accuracy-aware Weight Quantization)[9]是一种自适应量化方法,它利用了动态范围量化的思想。该方法根据权重分布的特性,动态调整量化区间,使得量化后的权重能够更好地逼近原始浮点数权重。AWQ 在量化过程中引入了微调步骤,以恢复因量化带来的性能损失。
精度损失函数:通过定义一个精度损失函数,量化过程可以根据该函数的值动态调整量化参数,从而在压缩模型时最小化性能损失。
自适应量化粒度:AWQ根据权重的分布特性自适应地选择量化粒度,对于分布较为集中的权重采用较粗的量化粒度,而对于分布较为分散的权重采用较细的量化粒度。
量化范围优化:通过分析模型在不同量化范围内的性能表现,AWQ能够确定最佳的量化范围,从而进一步减少量化带来的性能损失。
优点:自适应量化,根据权重的重要性分配不同的量化级别,有效降低精度损失;压缩率高,相比传统量化方法,AWQ具有更高的压缩率。
缺点:计算复杂度较高,需要对每个权重进行量化级别分配,增加了计算复杂度;训练过程复杂,需要在训练过程中引入额外的量化操作,导致训练过程较为复杂。
GPTQ量化
GPTQ[10]是一种静态的后训练量化技术,它专注于将FP16精度的模型量化为4bit,以实现显著的显存节省和推理速度提升。GPTQ使用非对称量化,并逐层进行量化,每层独立处理完毕后再继续到下一层。在这个逐层量化过程中,首先将层的权重转换为逆-Hessian矩阵,然后根据权重的重要性进行量化和量化误差的重新分配。
优点:能够将模型量化到较低的比特位宽度,如4位,从而显著减少模型大小和提高推理速度;采用静态量化方法,量化后的模型无需进一步训练即可使用。
缺点:量化过程需要较大的GPU显存,对于大规模模型可能需要高达16GB的显存;量化过程可能较慢,特别是对于大型模型。
模型推理
体育比赛直播的智能解说对模型推理速度有较高要求,通过采用多种优化方案让模型实时响应时延性控制在1秒左右。
KV Cache加速
KV Cache是针对自注意力机制的一种优化策略,它在生成序列文本的过程中缓存了之前计算得到的键(Key)和值(Value)向量,避免了每次生成新词时都需要重新计算所有先前词的注意力权重。
在推理进程中与训练不同,推理进行时上下文输入Encoder后计算出来的K和V是固定不变的,对于这里的 和 可以进行缓存后续复用;在Decoder中推理过程中,同样可以缓存计算出来的K和V减少重复计算。
如图3所示,左边ATTN是Encoder,在T1时刻计算出来对应的K和V并进行缓存,后续推理都不用再计算了;右边ATTN是Decoder,T2时刻通过输入的一个词计算出来QT2、KT2、VT2,但计算Decoder
过程中需要之前时刻T1的所用和向量。所以这里Decoder每次计算出来一组新的和向量都跟之前向量一起进行缓存,后续也可以重复复用。
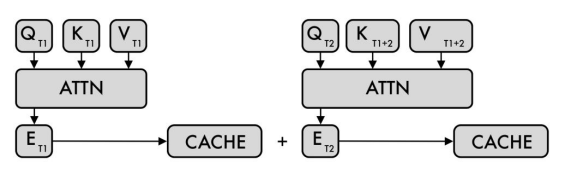
优势:减少重复计算,在生成序列的每个步骤中,只需计算当前词的查询(Query)向量与缓存的键(Key)向量之间的注意力权重,大大降低了计算量。加速推理,由于减少了计算量,KV Cache 显著加快了模型的推理速度,尤其是在处理长序列文本时效果更为明显。
Flash Attention加速策略
Flash Attention[11]是一种改进的自注意力机制,通过优化注意力矩阵的计算过程,实现了更快的并行计算。它利用了矩阵运算的特性,将注意力计算分解成多个更小的矩阵乘法操作,便于GPU并行执行。
在标准注意力实现中,注意力的性能主要受限于内存带宽,是内存受限的。频繁地从HBM中读写矩阵是影响性能的主要瓶颈。稀疏近似和低秩近似等近似注意力方法虽然减少了计算量FLOPs,但对于内存受限的操作,运行时间的瓶颈是从HBM中读写数据的耗时,减少计算量并不能有效地减少运行时间(wall-clock time)。针对内存受限的标准注意力,Flash Attention是IO感知的,目标是避免频繁地从HBM中读写数据。
如图4中所示,从A110-40G的GPU显存分级来看,SRAM的读写速度比HBM高一个数量级,但内存大小要小很多。通过kernel融合的方式,将多个操作融合为一个操作,利用高速的SRAM进行计算,可以减少读写HBM的次数,从而有效减少内存受限操作的运行时间。但SRAM的内存大小有限,不可能一次性计算完整的注意力,因此进行分块计算,使得分块计算需要的内存不超过SRAM的大小。
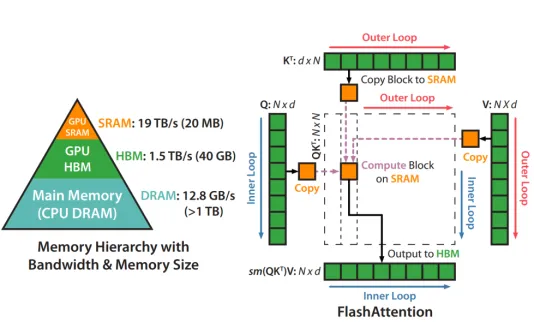
优势:高效并行计算,Flash Attention 允许在GPU上进行高效的并行计算,显著减少了自注意力计算所需的时间;内存优化,通过优化数据布局和计算流程,Flash Attention 减少了内存访问次数和带宽需求,进一步提升了计算效率。
应用篇
体育行业竞品有文字解说功能,但大部分为解说员人工输入,还有一些基于模板规则,解说形式比较单一,内容比较简单机械。传统体育解说人员解说词往往受限于个人风格,且难免会存在知识瓶颈和人工解说体力限制,直播行业兴起,体育直播二台大量主播赛事专业水平参差不齐。

而AI智能解说完美解决了如上问题。AI智能解说能按照赛况进程分为赛前分析、赛中解说、赛后小结环节,赛前分析主要对主客队的历史表现、基础信息做前瞻分析;赛中解说是对射门、进球、拦截、越位等42种重要事件类型做内容解说;赛后小结是对上下半场结束做进攻、防守、纪律等表现做小结分析,以此来丰富解说内容维度,提供沉浸式解说体验。
AI智能解说能力在2024年已上线“咪咕视频”欧洲杯和巴黎奥运会的足球比赛,支持40多种重要核心事件解说和TTS语音播报功能,以足球为试点后续扩展模型能力支持篮球、乒乓球、羽毛球等各大主流赛事,进一步提高行业影响力。
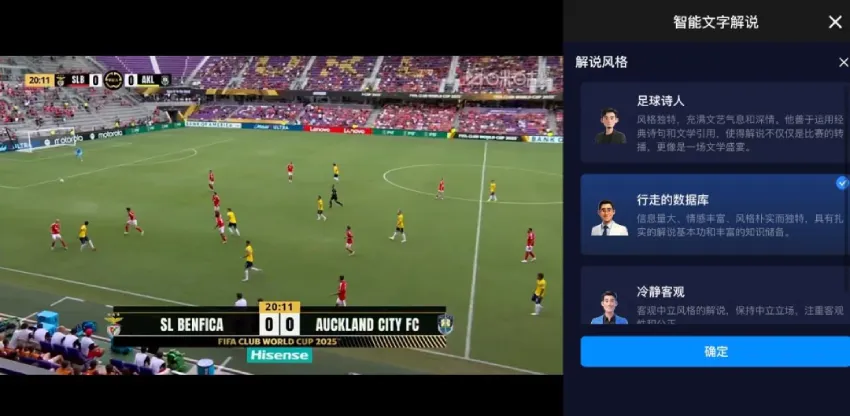
2025年世俱杯期间,AI智能解说全新升级,通过文体大模型自动生成多种风格文本供球迷选择:以诗化语言点燃赛场激情的“足球诗人”、用精准数据拆解战术博弈的“行走的数据库”,还有专注技术细节分析的“冷静客观”,三种风格可自由切换,不仅实时解读场上数据,更融入球队历史、球星故事等丰富周边信息,每场比赛都能拥有独一无二的听觉体验。
展 望 篇
多模态数据深度融合:从 “文本理解” 到 “全景感知”
目前大语言模型的输入和输出是文字,只有文本数据对比赛理解能力有限,后期可以使用多模态大模型同时处理视频图像、音频和文本数据,从而提供更全面的信息理解和更丰富的解说内容。
多模态大模型通过引入视觉信息,可以实现对比赛场景的实时分析,包括运动员的动作、球的位置、比赛节奏等。这不仅能够提高解说的准确性和实时性,还能够为观众提供更加生动和直观的观赛体验。
数智人解说:从 “形象选择” 到 “个性化定制与情感共鸣”
数智人形象是指通过人工智能技术生成的虚拟人物形象,具有多种音色和多种形象选择。数智人形象不仅可以模拟真实主持人的语音和语调,还可以根据不同的比赛场景和观众需求,选择合适的形象和音色。
多种音色和形象选择可以满足不同观众的个性化需求。例如,年轻观众可能更喜欢活泼、幽默的解说风格,而年长观众可能更偏好传统、稳重的风格。通过选择合适的音色和形象,数智人解说员可以更好地与观众建立情感连接,提高观赛体验。
实时战术预测与沉浸式分析:从 “事件播报” 到 “策略解读”
当前 AI 解说已能完成 “赛后小结”,未来将升级为 “实时战术预测 + 沉浸式分析”,让用户从 “看比赛” 升级为 “懂比赛”,满足深度球迷对战术细节的需求。
基于大数据的实时战术预测:AI 将整合球队过往 5 年的交锋数据、本赛季战术变化趋势、球员伤病与状态数据,在比赛过程中实时生成 “概率性战术预测”。沉浸式战术可视化解说:结合 AR技术,AI 解说将同步生成 “战术图示文字描述”(适配非 AR 观看场景)与 “动态战术板”(适配 AR 观看场景)。
跨赛事的战术对比分析:AI 将打破单一赛事的局限,实现 “不同赛事、不同球队” 的战术关联解读。
未来,AI 智能解说将不再是 “替代人工解说” 的工具,而是 “延伸人工解说能力、拓展观赛边界” 的伙伴 —— 它既能用大数据满足深度球迷的专业需求,也能用个性化互动吸引年轻观众,更能用无障碍服务让每一位体育爱好者感受到赛事的魅力,最终推动体育赛事传播进入 “技术赋能、体验普惠” 的新时代。
【参考资料】
[1] Vaswani A. Attention is all you need[J]. Advances in Neural Information Processing Systems, 2017.
[2] Koroteev M V. BERT: a review of applications in natural language processing and understanding[J]. arXiv preprint arXiv:2103.11943, 2021.
[3] Guo M, Ainslie J, Uthus D, et al. LongT5: Efficient text-to-text transformer for long sequences[J]. arXiv preprint arXiv:2112.07916, 2021.
[4] Floridi L, Chiriatti M. GPT-3: Its nature, scope, limits, and consequences[J]. Minds and Machines, 2020, 30: 681-694.
[5] Recognition—ASR A S. Automatic Speech Recognition—ASR[J]. 2013.
[6] 高峰. 中国移动发布 “灵犀云” 智能语音平台[J]. 计算机与网络, 2016, 42(2): 14-15.
[7] Sangwan A, Chiranth M C, Jamadagni H S, et al. VAD techniques for real-time speech transmission on the Internet[C]//5th IEEE International Conference on High Speed Networks and Multimedia Communication (Cat. No. 02EX612). IEEE, 2002: 46-50.
[8] Mithe R, Indalkar S, Divekar N. Optical character recognition[J]. International journal of recent technology and engineering (IJRTE), 2013, 2(1): 72-75.
[9] Lin J, Tang J, Tang H, et al. AWQ: Activation-aware Weight Quantization for On-Device LLM Compression and Acceleration[J]. Proceedings of Machine Learning and Systems, 2024, 6: 87-100.
[10] Frantar E, Ashkboos S, Hoefler T, et al. Gptq: Accurate post-training quantization for generative pre-trained transformers[J]. arXiv preprint arXiv:2210.17323, 2022.
[11] Dao T, Fu D, Ermon S, et al. Flashattention: Fast and memory-efficient exact attention with io-awareness[J]. Advances in Neural Information Processing Systems, 2022, 35: 16344-16359.
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。