
作者:梁栋、复礼、家泽
来源:阿里云云原生
海尔智家 AIoT 平台作为智能家居生态的中枢,承载着冰箱、洗衣机、空调等超大规模在线设备的长连接管理。近年来,海尔智家的家庭智能化业务高速发展,网器规模快速增长,每日处理设备上报数据与用户指令数十亿条,高峰期日吞吐量更是突破百亿级,对 AIoT 平台的技术能力进化速度提出了极高的要求。


作为大规模设备接入的核心入口,Kafka 集群是设备网关与后端业务的核心通道,直接决定了海量用户的家电控制体验,一旦出现网络抖动、计算瓶颈、消息积压或丢失,都可能导致大规模设备掉线,对平台产生巨大冲击。
因此,消息通道必须具备极高的稳定性、实时性与弹性,为此海尔智家平台在承接大量业务需求的同时,持续围绕网关、Kafka 中间件等关键基础设施进行性能优化、稳定性优化和容错性优化。
在海尔智家团队精益求精的技术追求之下,自建的 Kafka 集群规模已增长至达到数十节点规模,为整个 AIoT 业务在高速增长中始终保持健康稳定运行提供了坚实的保障。
战略前瞻:聚焦业务创新,携手专业伙伴
随着业务规模进入深水区,海尔智家大量智能硬件的迭代和网器化业务不断涌现,研发团队亟需将更多人员和精力投入到业务功能和创新产品的研发之中。同时,海尔智家平台制定了自研与外采的边界标准与规范以便在发展自身业务与创新投入同时,仍可以保障业务高稳定、高可靠运行。
海尔智家平台据此边界标准与规范并考虑到下一阶段业务的高速发展对基础设施的研发与运维需求将持续提升,同时为了让研发团队能够集中精力支撑好业务需求和创新发展,团队开始考虑陆续将各类中间件基础设施更多的迁移至云产品,在此背景下开启了与阿里云多个技术团队的技术论证,其中 Kafka 作为核心中间件也是最为挑战的一环,成为了海尔智家平台和阿里云技术团队最为重要的迁移攻坚项目。
由于智家的基础架构团队和稳定性团队在自建 Kafka 集群上积累了丰富的技术理解和运维经验,并且在不同业务场景下对 Kafka 的使用 Pattern 也各不相同,非常依赖智家自身对业务场景的特点洞察和经验,这些宝贵积累为与阿里云的合作奠定了坚实的基础:
1. 运维体系经验丰富:团队在 Topic 扩缩容、主从切换、版本升级等关键操作上积累了深厚的实战经验,对集群行为的理解深入透彻。
2. 稳定性保障体系完善:围绕节点故障恢复、分区均衡、资源管理等方面,团队已建立起一套成熟的保障机制和处置流程。
3. 弹性需求洞察清晰:面对新品发布带来的流量突增等场景,团队对业务流量特征有着精准的理解和预判。
这些经验与洞察,为后续与阿里云的深度共创合作提供了极具价值的输入和帮助。
深度共创:双方联合分析,制定稳定性优先的迁移方案
在阿里云与海尔的共创合作中,阿里云技术团队结合智家梳理与提供的各 Kafka 集群业务场景、性能差异、集群调参、业务上下游关系等众多信息,结合阿里云 Kafka Serverless 产品自身特点进行技术方案共建,针对上云后集群进行参数调优和策略调整以及模拟压测,直至能够在相同消息尺寸与并发之下,在性能吞吐、延迟等方面能够对齐自建 Kafka。
最终,双方共同制定了以“稳定性优先”作为核心原则的切换方案。
在合作初期,双方在深入梳理中,明确了若干需要精心适配的技术要点:
1. 迁移精度要求高:智家积累的复杂 Topic 结构和大量历史数据,需要精准保证消费位点的衔接,这对迁移工具的能力提出了更高要求。
2. 流量特征独特:海尔业务具有显著的潮汐效应和突发指令高峰,需要根据这种独特的流量模型进行专项资源配置优化,以充分发挥云端弹性优势。
3. 风险识别体系升级:从自建环境迁移到云原生平台,双方需要共同构建一套能够精准匹配智家业务逻辑的深层风险识别能力,实现监控体系的全面升级。
海尔智家团队基于对自身业务逻辑和流量特征的理解,向阿里云提出了针对性的适配建议,双方共同探讨海尔使用场景特点,共同设定技术共建方案:
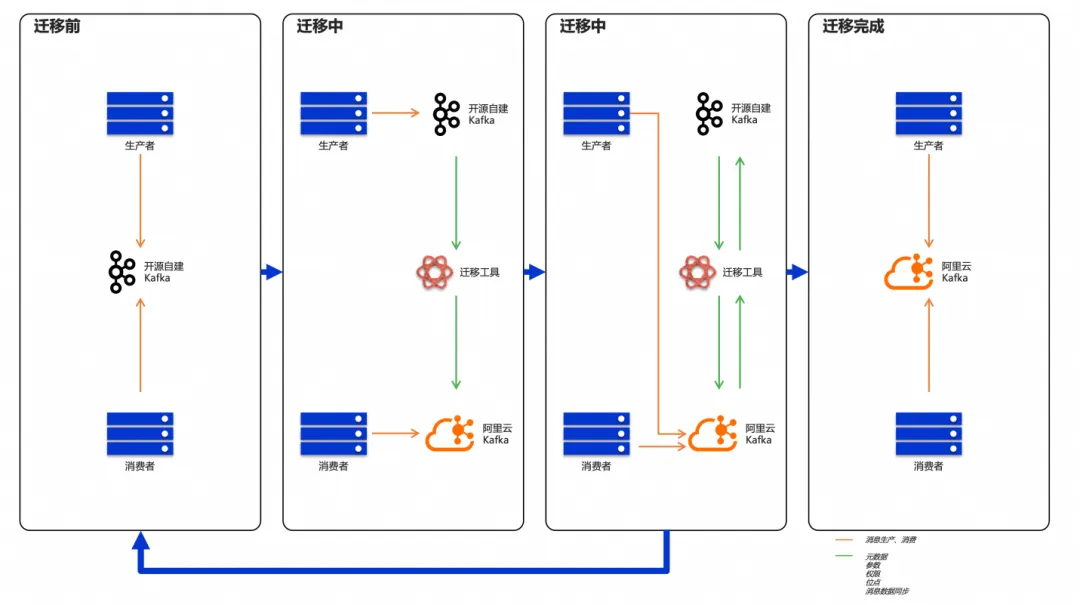
1. 定制迁移策略:提出“数据双写 + 精细化分批灰度”的专属方案,确保核心指令类业务平滑过渡。
2. 流量特征调优:要求根据海尔实际的 IO 模型和Batch 大小特点,对集群参数进行深度优化配置,而非使用默认值。
3. 风险识别共建:主张结合海尔的业务场景,共同构建一套能提前识别小 Batch 通信、IO 不均等隐蔽问题的风险监测体系。
在阿里云精心调整过的 Kafka Serverless 集群之下,双方以风险最小化为原则,逐步进行双跑写入、消费验证、割接验证,直至上下游 Flink 等任务的背压达到理想状态才启动正式迁移,确保每一步都经过充分验证。
联合攻关:打磨专属方案、配置优化与风险共治
基于海尔智家的业务场景与稳定性团队的经验和输入,双方技术团队聚焦于迁移落地的深度适配,共同完成了以下关键工作:
1、迁移方案的精细化落地
阿里云团队配合海尔的业务节奏,重新设计了迁移工具的执行逻辑,支持按 Topic 重要性灵活配置。双方确立了“三步走”灰度策略:
- 第 1 周:迁移非核心日志类 Topic,验证数据一致性;
- 第 2 周:迁移核心指令类 Topic,执行“双写校验”,确保新旧集群数据实时比对无误;
- 第 3 周:全量切换并观察 7 天,确认系统稳定后,正式下线原集群。
2、基于流量特点的专项配置优化
针对海尔智家特有的高并发、突发指令多、短消息低延迟敏感的流量特征,双方进行了深度的联合调优:
1. 参数定制化:根据海尔实际的消息包大小和生产者发送频率,精细调整了 Kafka的 batch.size、linger.ms 等关键参数,显著提升了吞吐效率。
2. 资源弹性匹配:依据海尔业务的潮汐规律,通过定时能力提前设置弹性伸缩阈值,确保在早晚高峰来临前资源已就绪,避免冷启动延迟。
3、集群风险识别体系的共建
双方打破了传统的“云厂商提供标准产品、客户使用”模式,建立了风险识别共建机制:
1. 深层隐患挖掘:海尔提供典型故障案例,阿里云利用云端智能分析能力,共同梳理出针对“小 Batch 通信导致的性能损耗”、“分区 Leader 分布不均”等隐蔽风险的识别规则,从云产品监控页层面进行功能打磨,向海尔提供更多有用信息。
2. 可观测融合:将上述共建的风险指标无缝对接至海尔现有的可观测平台,实现了从底层资源到上层业务逻辑的全链路透明化,帮助团队在问题发生前提前干预。
这一过程并非产品功能的颠覆性改造,而是成熟产品在特定超大规模场景下的最佳实践适配、配置调优与运营体系共建。
成效落地:方案成熟驱动业务飞跃
经过半年的稳定运行,海尔智家在云上 Kafka Serverless 的运行稳定性得到充分验证,智家研发团队陆续将原先的运维精力释放并转交给阿里云研发团队进行稳定性兜底:

1、运维效率:从“天级”到“分钟级”
- 扩缩容:由人工运维的分批次分集群操作,转变为由 Kafka Serverless 自动化运维。
- 故障恢复:由人工介入的运维模式,转变为由 Kafka Serverless 的秒级 failover 切换,无需运维主动介入。
- 版本升级:面对大流量集群难升级版本的问题,转变为 Kafka Serverless 平台自动轮转升级,业务层做到了无感知。
2、业务指标:稳如磐石
- 可用性:全年服务可用性达 99.99%,上云后未出现集群故障。
- 可靠性:累计处理消息超数千亿条,Kafka Serverelss 预留带宽自动扩容,消息积压自动扩容响应 < 10 分钟,无需人工介入运维扩容。
- 用户体验:设备指令下发成功率稳定在 99.995%,未出现消息延迟、丢失等问题
3、团队转型
基础架构团队和稳定性团队将 Kafka 维护交付给阿里云后,有更多的精力对 AIoT 日益高速增长的设备规模进行应用架构优化,更加专注于打造面向全球用户、多集群容灾、高可用架构的业务系统。
在本次技术共建过程中,阿里云 Kafka Serverless 结合智家对业务的理解和多年集群建设的经验积累,也打磨了自身产品的诸多企业级能力,能够更好的服务于大规模 Kafka 的企业用户:
1. 迁移能力支持双写,保障整体方案的可靠性。
2. 风险告警更精准,在避免干扰的同时,提前感知风险,规避风险。
结语:双向奔赴,成就双赢
此次迁移不仅是一次技术架构的升级,更是一次阿里云与客户在落地层面双赢的典范:
1. 对海尔智家而言:将智家多年来的 Kafka 稳定性工作交棒交给阿里云,技术团队可以聚焦到应用架构,为下一阶段网器化更大规模的高速增长做好技术打磨。
2. 对阿里云而言:海尔智家提供的超大规模真实场景、独特的流量特征数据以及在风险识别上的宝贵输入,极大地丰富了阿里云 Kafka Serverless 的行业落地方法论与配置最佳实践库。这证明了该产品具备支撑顶级物联网场景的能力,为后续服务更多大型客户提供了可复制的“实战指南”。
正如海尔智家 IoT 基础平台负责人王珂伟所言:“迁移的成功关键在于双方能否结合业务实际,在配置优化和风险共治上达成共识。现在,系统不仅能平稳承载上百亿条消息,更能通过共建的监控体系提前规避风险。这种基于深度适配与联合运营的共赢模式,让我们非常放心的将越来越多的基础设施交付给阿里云。”
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。