
CTC应用背景
在语音识别和文字识别的领域,我们的数据集是音频文件和文本,但是,音频文件和文本很难在单位上对齐,比如有人说话快,有人说话慢,有的字符间距离不同,因此这种序列标签的对齐有时候是非常困难的,而如果不能序列对齐,是没办法训练样本的,从而就不能很好的进行语音识别和文字识别。 因此为了解决这一问题,Hannun等人在2017年distill.pub上发表文章,提出了联结时间分类(Connectionist Temporal Classification,后面用CTC简写表示)。CTC是一种避开输入与输出手动对齐的一种方式,是非常适合语音识别或者OCR这种应用。
本章主要讨论下CTC 的基本实现原理和推导公式,CTC是可以用来解决训练时,字符标签无法对齐的问题。
CTC的定义
给定输入序列X=[x1,x2,…,xt], 以及对应的标签数据Y=[y1,y2,…,yu],CTC就是要找到X和Y之间的一个映射,这种对时序数据进行分类的算法就是Temporal Classification。对比传统的分类方法,时序分类有如下难点:
1,X和 Y 的长度都是变化的;
2,X 和 Y 的长度是不相等的;
3,对于一个端到端的模型,我们并不希望手动设计X 和 Y 的之间的对齐。
CTC提供了解决方案,对于一个给定的输入序列X ,CTC给出所有可能的Y的输出分布。根据这个分布,我们可以输出最可能的结果或者给出某个输出的概率。
损失函数:给定输入序列X后,我们希望最大化Y 的后验概率P(Y|X),P(Y|X)是可导的,这样就可以执行梯度下降法,算出最大值P。
CTC算法推导
得到的X序列标签后,通过引入的空白符,并合并重复的字符,即可得到最终的标签,如下所示:
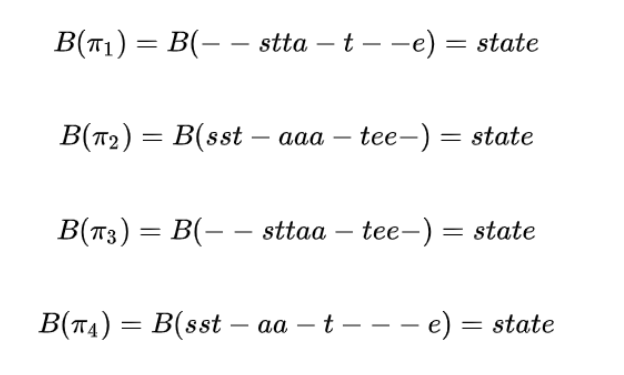

π表示不同路径,那么CTC在这个过程中需要做什么?对于给定输入x的情况下,输出为l的概率为:
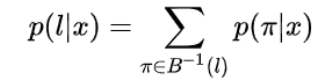
其中,对于任意一条路径π有:
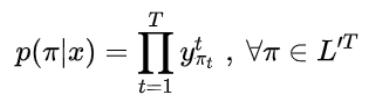
如对于T=12的路径π来说:
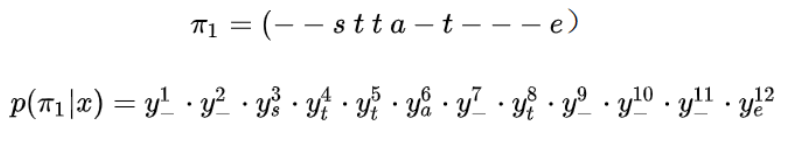
实际情况中一般手工设置 T大于等于20,有非常多条路径π,无法逐条求和直接计算p(L|x),所以需要一种快速的计算方法。
CTC训练过程
本质上是通过概率的梯度,调整LSTM的参数w,使得对于输入样本为π,使得P取得最大。定义所有经B变换后结果是l,且在 T 时刻结果为 lk(记为πt=lk),求导得:
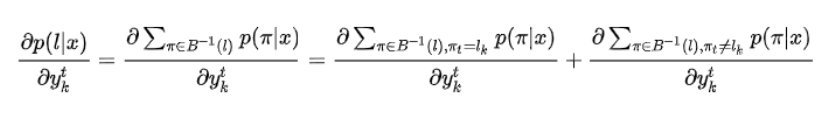
注意上式第二项与ykt无关,所以:
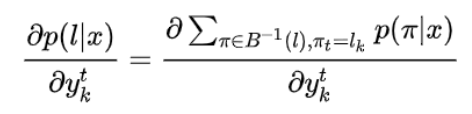
举例说明,还是看上面的例子 π1,π2(这里的下标 1,2代表不同的路径):
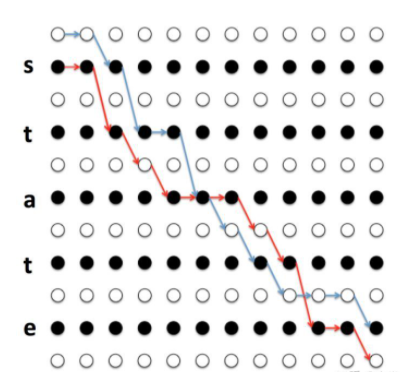
在t=6时,恰好经过π6 = a,
π1,π2可以表示为:
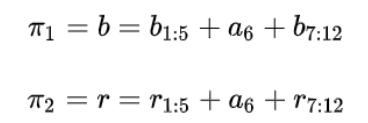
那么π3,π4可以表示为:
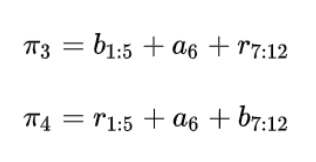
因此,转换为计算:
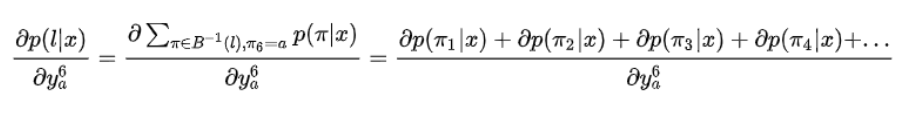
因此,可以单独计算:
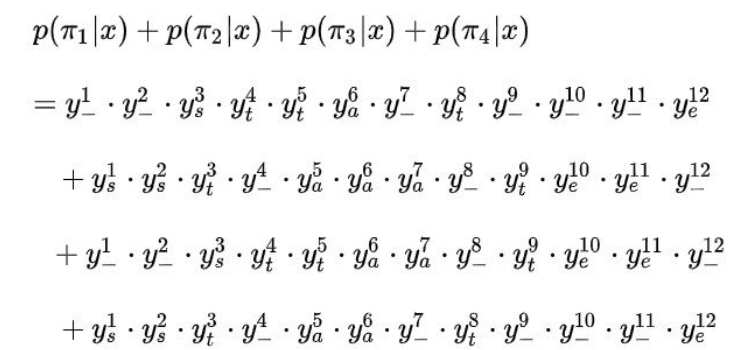
不妨令:
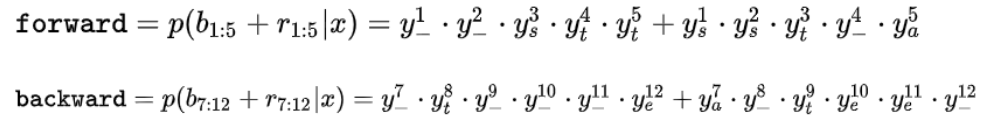
因此,以上的概率和可以表示为:
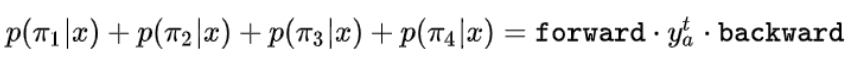
进一步推广,所有经过B变换且πt = lk的路径,可以写成如下形式:
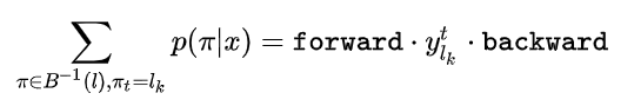
所以,定义前向递推概率(forward)和和向后递推概率(backword)和分别用如下公式表示:
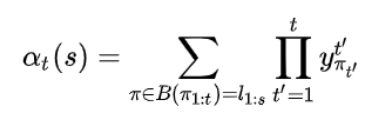
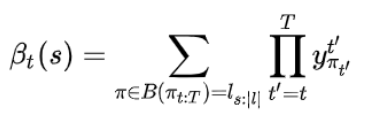
分别地推下来的话,就是:
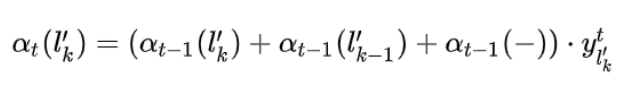
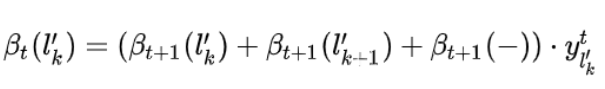
因此,可以得到,概率和
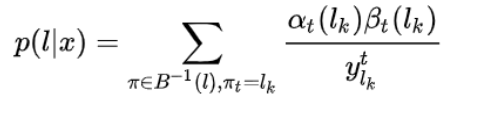
可以发现,训练CTC,因此计算该函数的梯度才是核心,如下公式所示:
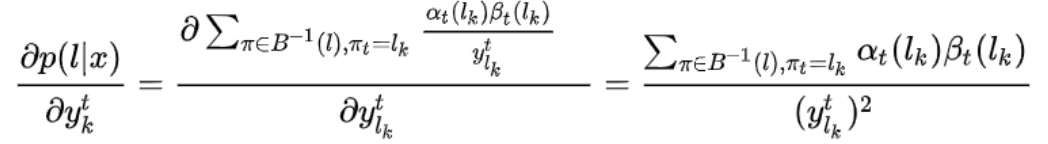
总结
CTC是一种Loss计算方法,用CTC代替Softmax Loss,训练样本无需对齐。引入blank字符,解决有些位置没有字符的问题,通过递推,快速计算梯度。
参考文献
[1] Connectionist Temporal Classification : Labelling Unsegmented Sequence Data with Recurrent Neural Networks. Graves, A., Fernandez, S., Gomez, F. and Schmidhuber, J., 2006. Proceedings of the 23rd international conference on Machine Learning, pp. 369–376. DOI: 10.1145/1143844.1143891
[2] Sequence Modeling with CTC. Hunnun, Awni, Distill, 2017
作者:徐鸣谦
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。