
谷歌研究院公布了一种用于微调大语言模型 (LLM) 的突破性方法,该方法可将所需的训练数据量减少高达 10,000 倍,同时保持甚至提升模型质量。该方法以主动学习为核心,并将专家的标注工作重点放在最具信息量的示例上——即模型不确定性达到峰值的“边界案例”。
传统瓶颈
针对需要深度语境和文化理解的任务(例如广告内容安全或审核),对 LLM 进行微调通常需要大量高质量的带标签数据集。大多数数据都是良性的,这意味着对于策略违规检测而言,只有一小部分示例才有意义,这增加了数据管理的成本和复杂性。当策略或有问题的模式发生变化时,标准方法也难以跟上,因此需要进行昂贵的重新训练。
谷歌主动学习的突破
工作原理:
- LLM-as-Scout: LLM 用于扫描庞大的语料库(数千亿个示例)并识别最不确定的案例。
- 有针对性的专家标记:人类专家不会标记数千个随机示例,而是仅注释那些边界上、令人困惑的项目。
- 迭代管理:这个过程重复进行,每一批新的“有问题”的例子都由最新模型的混淆点来告知。
- 快速收敛:模型经过多轮微调,迭代持续进行,直到模型的输出与专家判断紧密一致,以 Cohen’s Kappa 来衡量,该指标比较注释者之间的一致性,而非偶然性。
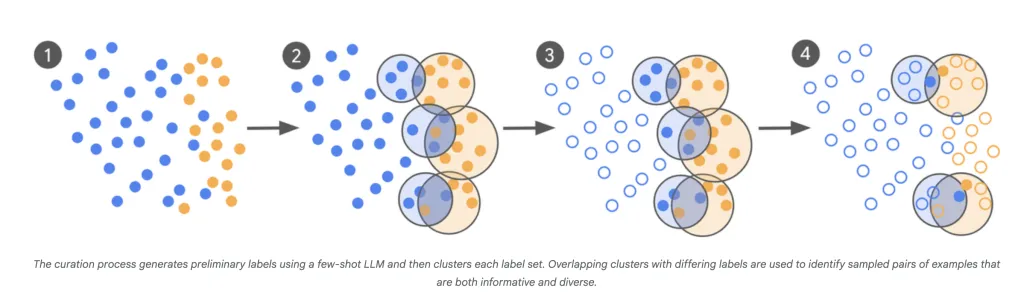

影响:
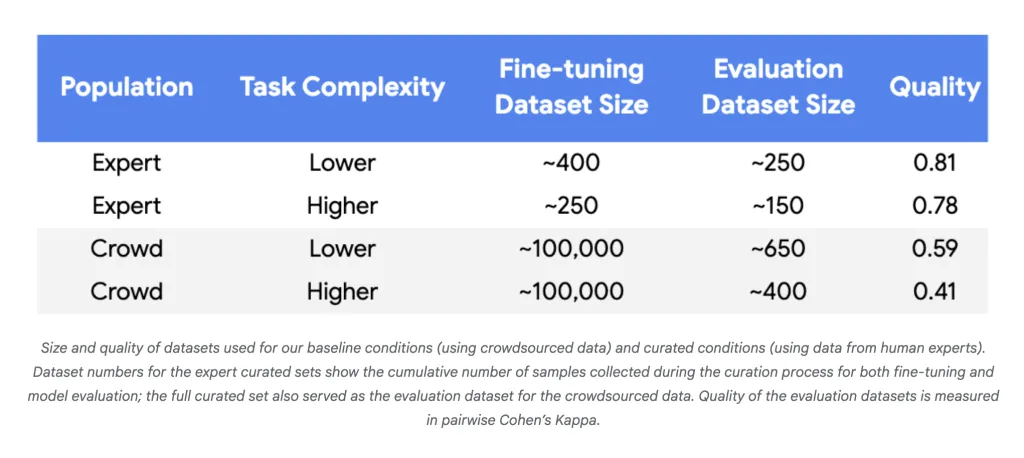
- 数据需求大幅下降:在使用 Gemini Nano-1 和 Nano-2 模型进行实验时,使用250-450 个精心挑选的示例(而不是约 100,000 个随机众包标签)即可与人类专家的匹配达到同等或更好的效果,减少了三到四个数量级。
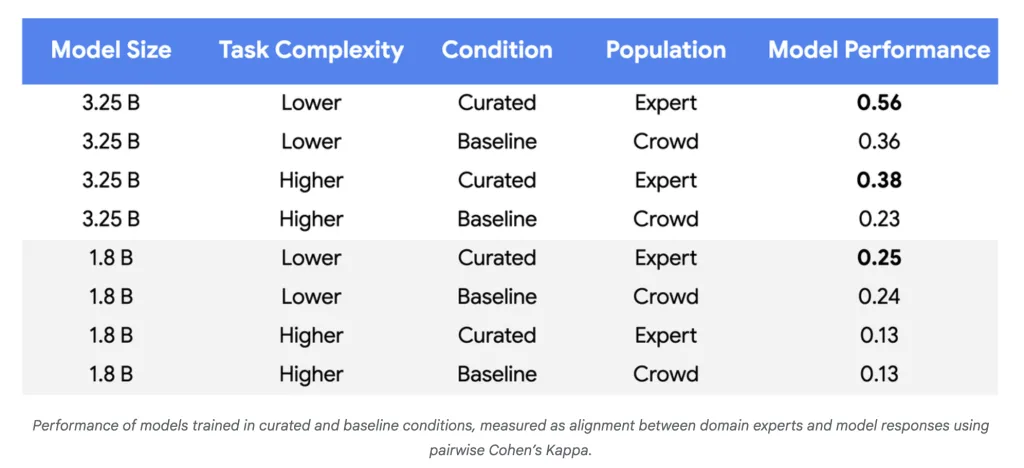
- 模型质量提高:对于更复杂的任务和更大的模型,性能改进达到基线的 55-65%,表明与政策专家的一致性更加可靠。
- 标签效率:为了使用微小数据集获得可靠的收益,始终需要较高的标签质量(Cohen’s Kappa > 0.8)。
为什么重要
这种方法颠覆了传统的范式。它不会让模型淹没在海量嘈杂、冗余的数据中,而是充分利用 LLM 识别模糊案例的能力,以及人类注释者在最有价值的领域提供的专业意见。其好处显而易见:
- 降低成本:需要标记的示例大大减少,从而大幅降低劳动力和资本支出。
- 更快的更新:通过少量示例重新训练模型的能力使得适应新的滥用模式、政策变化或领域转变变得快速且可行。
- 社会影响:增强的背景和文化理解能力提高了处理敏感内容的自动化系统的安全性和可靠性。
总之
谷歌的新方法使得 LLM 仅使用数百个(而不是数十万个)有针对性的高保真标签就可以对复杂、不断发展的任务进行微调,从而实现更精简、更灵活、更具成本效益的模型开发。
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/jishu/60520.html