
1.什么是声纹识别
声纹识别是生物识别技术的一种,也称为说话人识别,包括说话人辨认和说话人确认。人类语言的产生是人体语言中枢与发音器官之间一个复杂的生理物理过程,人在讲话时,多个发声器官在尺寸和形态方面差异很大,所以任何两个人的声纹图谱都有差异。每个人的语音声学特征既有相对稳定性,又不是一成不变的。这种变异可来自生理、病理、伪装、环境干扰等因素有关。尽管如此,在一般情况下,人们仍能区别不同的人的声音或判断是否是同一人的声音。
2. 小波变换
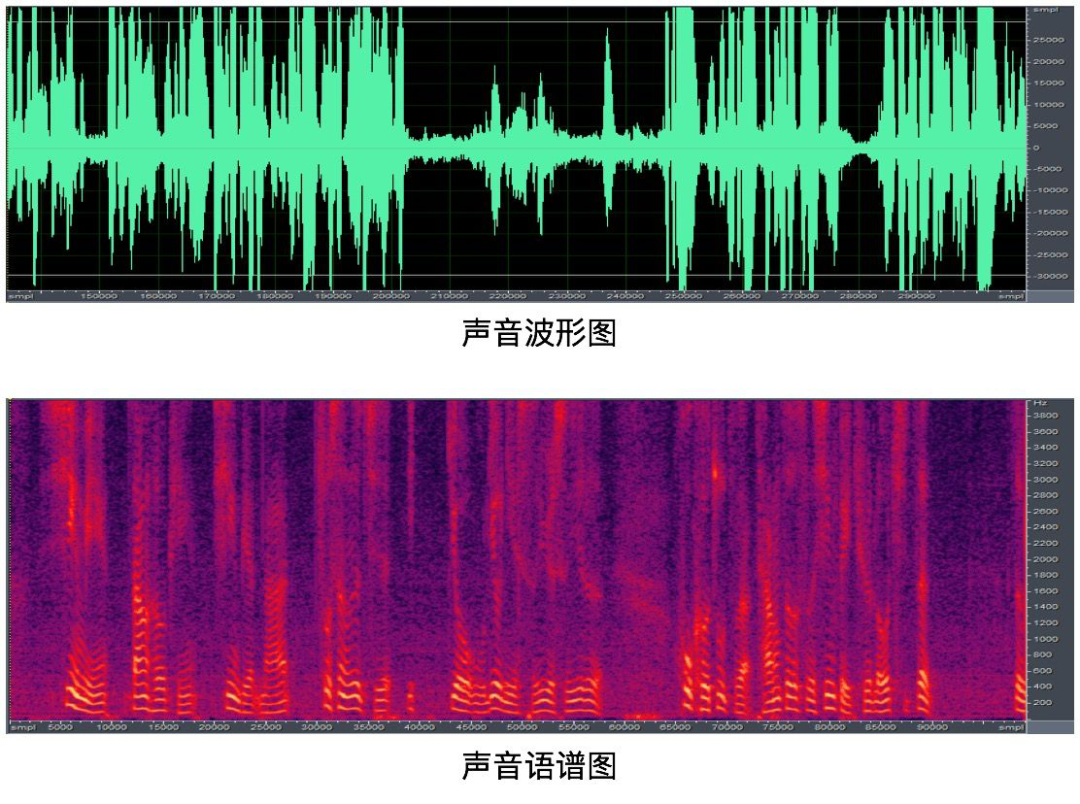
声纹不如图像那样直观展现,在实际分析中,可通过波形图和语谱图进行展现,如下所示:

MFCC和LPCC算法是常用的传统算法,在频域采用快速傅里叶变换,从而提取频域特征,但是算法不能提取时域特征。即使增加时间窗,时域特征的提取也是不准确的,同时还会造成频域特征的丢失。由于传统算法存在上述缺陷,会直接影响识别准确率。
小波变换(Wavelet Transform)是一种新的变换分析方法,它继承和发展了短时傅立叶变换局部化的思想,同时又克服了窗口大小不随频率变化的缺点,能够提供一个随频率改变的“时间-频率”窗口,有效对信号同时进行时域和频频的分析
3. 小波之分解重构
采用分解重构算法,假设输入信号为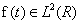 ,
,
,其中e(i)为高斯白噪声或者其他噪声。将S进行分解,如果采用3层分解,则结构图如下图所示:
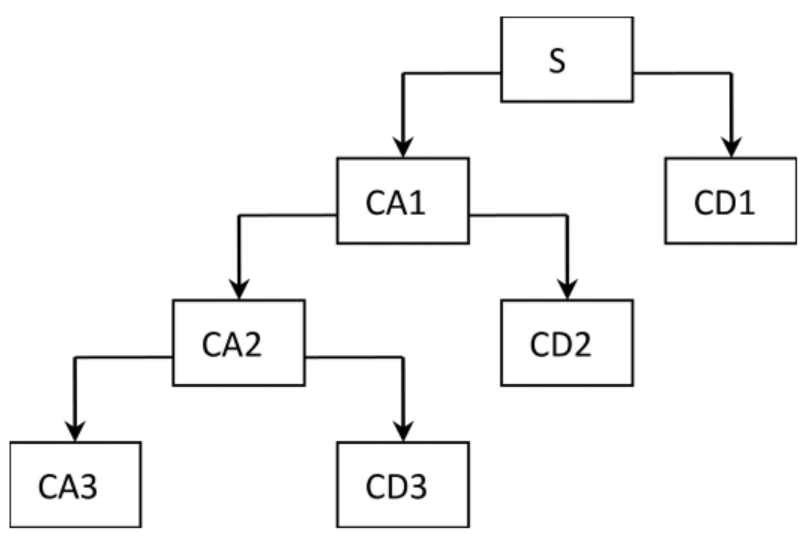
将CD1、CD2、CD3、CD4标记为d1,d2,d3,a3经规范化后,标记为Q1、Q2、Q3、Q4。构造向量[Q1,Q2,Q3,Q4],该向量为声音的特征向量并用来训练神经网络。根据小波分解重构算法,s=a3+d3+d2+d1。
4. 基于遗传的神经网络
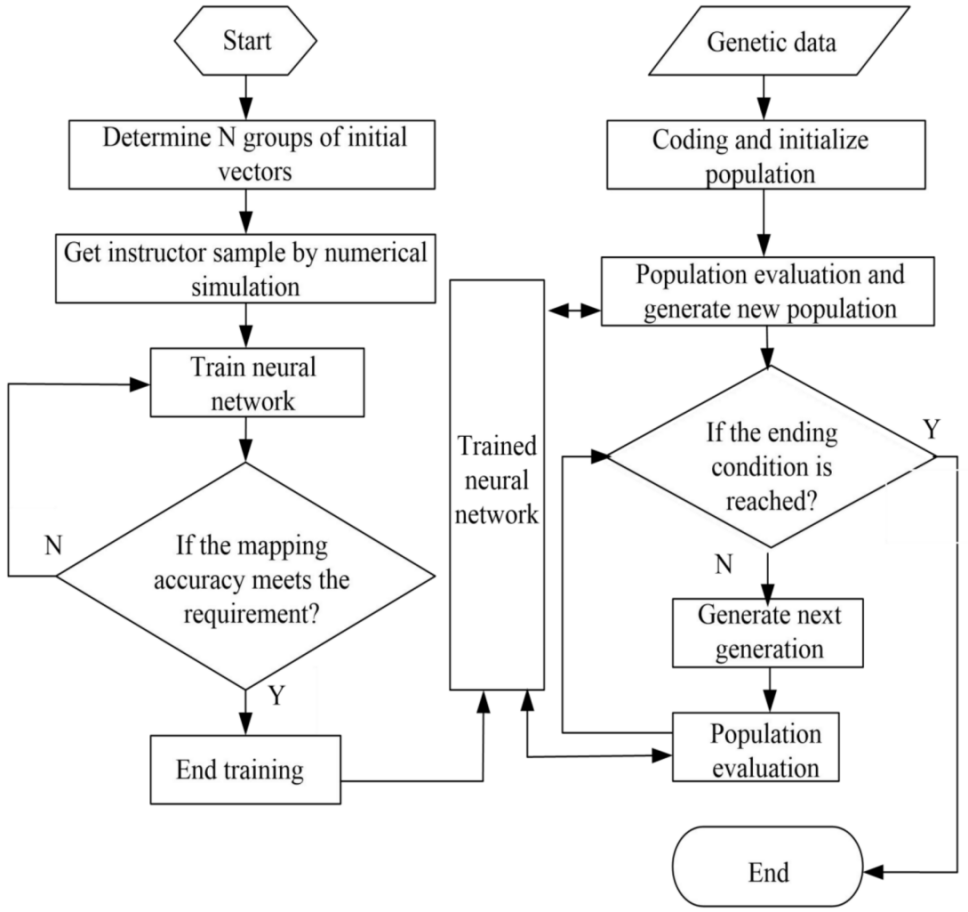
遗传算法(Genetic Algorithms,GA)模拟自然界遗传和生物进化论而成的一种并行随机搜索最优化方法。与自然界中“优胜劣汰,适者生存”的生物进化原理相似,按照选择的适应度函数通过选择、交叉和变异对个体进行筛选,使适应度值好的个体被保留,适应度差的被淘汰。新的群体既继承了上一代的信息,又优于上一代,这样反复循环,直至满足条件。将GA算法应用于BP神经网络,可以结合两者优势,效率高且有较强的全局搜索能力。其算法结构如下图:
5. 声纹识别网络结构
采用简单的三层前馈网络,输入层采用3个节点,第二层采用5个节点,输出为3个节点。网络拓扑结构如下图所示:
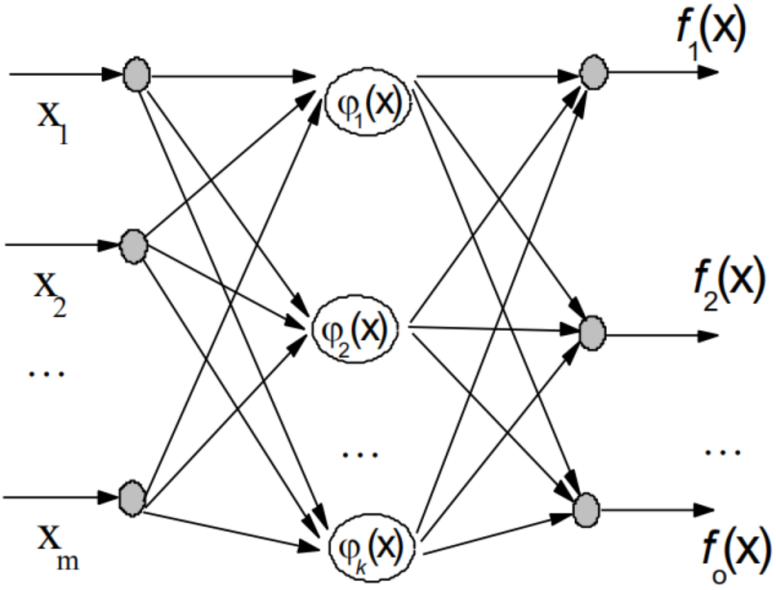
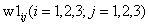 为输入层权重;为输入层输入;为中间层权重;为中间层向量;为中间层偏移量;为输出层偏移量;
为输入层权重;为输入层输入;为中间层权重;为中间层向量;为中间层偏移量;为输出层偏移量;
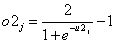
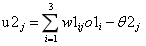 ,其中j=1,2,3
,其中j=1,2,3
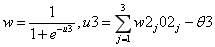 其中j=1,2,3
其中j=1,2,3
6. 遗传算法主要流程
遗传算法主函数流程为:
步骤1:随机初始化种群;
步骤2:计算种群适应度值,从中找出最优个体;
步骤3:选择操作;
步骤4:交叉操作;
步骤5:变异操作;
步骤6:判断进化是否结束,若否,则返回步骤2。
拟合函数为: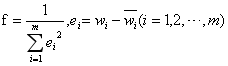
7. 实验结果
采用数据集进行测试,与MFCC、LPCC算法进行比较,结果如下:

从结果可以看出,小波变换可以有效提取时域、频域的特征,结合遗传算法可以实现快速收敛。相比于传统算法,一个结构简单的全连接网络即可取得不错的效果,识别速度快、准确率高以及低错误率。
作者:王昌
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。