
这篇文章针对稀疏输入视角的场景,在3DGS的基础上提出了实现实时和高质量渲染的方案。论文主要提出了一个邻近引导的高斯上池化模块,用于优化过程中高斯的稠密化,同时还利用预训练的单目深度估计模型引入了深度约束,从而使得优化朝着正确的方向进行。
来源:arxiv 2023.12
论文标题:FSGS: Real-Time Few-shot View Synthesis using Gaussian Splatting
作者:Zehao Zhu,Zhiwen Fan等
论文链接:https://arxiv.org/pdf/2312.00451.pdf
内容整理:高弈杰
介绍
新视角合成是计算机视觉和图形学领域中一项长期存在并且富有挑战的任务。过去两年,NeRF及其衍生工作的提出将该任务提升到了新的高度。然而,基于NeRF的方法的训练和渲染需要大量的成本才能达到理想的效果,比如稠密的输入视角和耗时的训练与渲染。尽管后续的一些稀疏视角NeRF的工作以及InstantNGP的提出在一定程度上解决了部分缺陷,但NeRF方法始终没有做到实时和高质量的高分辨率渲染。
去年下半年,3DGS的提出被视为更为高效的3D场景表征方法。它使用一系列的3D 高斯来对场景进行表征,并通过基于溅射的光栅化来完成对2D图像得到渲染。由于3DGS是通过sfm对输入视角重建生成的稀疏点云初始化的,因此也十分依赖稠密的输入视角。一旦输入视角稀疏,就会因为初始化不足而导致过于平滑的结果以及在训练集上过拟合。
本论文则是为解决稀疏视角引发3DGS初始化不足的问题,提出了一个邻近引导的高斯上池化模块,通过衡量高斯与其邻居的邻近程度,在高斯之间生成新的高斯,从而有效地使高斯稠密化,更好地覆盖场景。此外还存在一个挑战,那就是如何保证高斯在初始化不足的情况下仍能朝着正确的方向稠密化,这就需要引入额外的约束来实现。论文则是引入了深度先验,使用一个预训练的单目深度估计模型来预测某视角的深度图,另外3DGS用一个与渲染颜色的α-blending方法接近的光栅化操作来渲染出该视角的深度图,计算这两个深度图之间的损失。通过引入深度约束,可以更好引导前面的高斯上池化收敛至一个合理的解决方案,并确保场景的几何平滑性。
本论文提出的FSGS模型在多个数据集上完成了训练和渲染,在稀疏视角的设定下取得了sota的渲染质量,并且实现了实时渲染。本论文的主要贡献如下:
- 提出了一个基于点的稀疏视角新视角合成方案,主要为邻近引导的高斯上池化模块来密集化高斯分布以实现全面的场景覆盖。
- 引入了单目深度先验,通过虚拟采样的训练视图进行增强,以指导高斯优化朝向最优解。
- 实现了实时渲染速度(200+ FPS),同时也提升了视觉质量,为在现实世界场景中的实际应用铺平了道路。
相关工作
3D高斯
3DGS是通过一系列的3D高斯来对场景进行显式的表征,每个高斯定义了空间中的一个点在3D空间中的高斯分布,即


为了渲染出2D图像,3DGS会将覆盖相应像素点的高斯进行排序并按照如下公式进行混合计算:
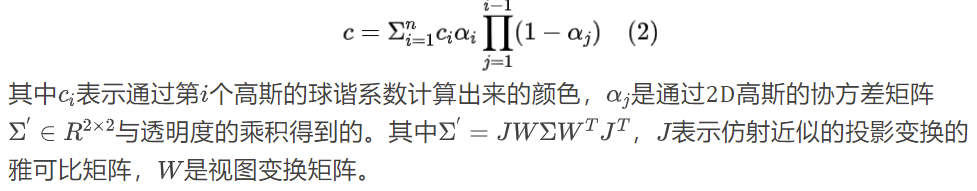
3D-GS中还引入了一种启发式的高斯密集化方案,其中根据超过阈值的视图空间位置梯度的平均大小来密集化高斯。尽管这种方法在用全面的SfM(结构从运动)点初始化时很有效,但对于仅从稀疏视图输入图像得到的极其稀疏的点云,它不足以完全覆盖整个场景。此外,一些高斯倾向于向极大体积生长,导致结果过度拟合训练视图,并且对新的视点泛化能力差.
方法
概述总览
论文提出的FSGS整体的框架如下图所示:

FSGS的输入是在一个静态场景中拍摄的稀疏视角的图像。相机的位置和稀疏点云是通过sfm计算得出的。用于进一步训练的初始3D高斯是从SfM点初始化的,包含颜色、位置和形状的属性。极其稀疏的SfM点和不充分的观测数据带来的挑战,通过采用邻近引导的高斯上池化来解决,通过测量现有高斯之间的邻近性并在最具代表性的位置策略性地放置新的高斯来填充空白空间,以增加处理细节的能力。为了保证密集化的高斯可以被优化以适应正确的场景几何,利用来自2D单眼深度估计器的先验知识,通过伪视图生成来增强,这避免了模型过度拟合稀疏输入视角。
邻近引导的高斯上池化
邻近分数和邻近图的构建
在高斯优化过程中,论文构建了一个称为邻近图的有向图,通过计算欧几里得距离将每个现有的高斯点与其最近的 K 个邻居相连。我们将起点的高斯称为“源”高斯,而终点的高斯,即源的 K 个邻居之一,称为“目的”高斯。分配给每个高斯的邻近分数是其与K个最近邻居的平均距离。在优化过程中的增密或剪枝过程后,邻近图会被更新。在实践中将K设为3。
高斯上池化
受到计算机图形学中广泛使用的网格细分算法的顶点添加策略的启发,论文提出了基于邻近图和每个高斯的邻近分数来进行高斯展开的方法。具体而言,如果一个高斯的邻近分数超过了阈值tprox,我们的方法将在连接“源”和“目的”高斯的每条边的中心处生成一个新的高斯。新创建的高斯的规模和透明度属性被设置为与“目的”高斯相匹配。同时,其他属性,如旋转和SH系数,初始化为零。高斯展开策略鼓励新密集化的高斯围绕代表性位置分布,并在优化过程中逐步填补观察空缺。
高斯优化过程中的几何引导
通过高斯上池化以实现密集覆盖后,应用了包含多视图线索的光度损失来优化高斯。然而,稀疏视图的视角数不足问题限制了学习连贯几何形状的能力,导致在训练视图上过拟合和对新视图泛化能力差的高风险。这就需要加入额外的正则化和先验来指导高斯的优化。具体而言,论文寻求借助由训练有素的单目深度估计器产生的深度先验来指导高斯的几何形状走向一个合理的解决方案。
从单目深度中注入几何一致性
论文通过使用预训练的Dense Prediction Transformer (DPT),该模型使用了140万个图像-深度对进行训练,在训练视图中生成单目Dest深度图,作为一个便捷且有效的选择。为了缓解真实场景尺度与估计深度之间的尺度歧义,论文引入了一个放宽的相对损失——皮尔逊相关性,对估计和渲染的深度图进行比较。它测量2D深度图之间的分布差异,并遵循以下函数:

可微深度光栅化
为了使深度先验能够通过反向传播指导高斯训练,我们实现了一个可微深度光栅化器,允许接收渲染深度Dras与估计深度Dest之间的误差信号。具体来说,论文在3D-GS中使用alpha混合渲染进行深度光栅化,其中,有序高斯对一个像素的贡献通过z缓冲累积,以产生深度值:
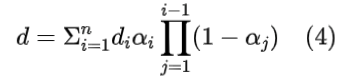
这里的di代表第i个高斯的z缓冲,而α与前面渲染颜色的方程中的含义相同。这种完全可微的实现使得深度相关性损失成为可能,进一步提高了渲染深度与估计深度之间的相似度。
合成伪视图
为了解决对稀疏训练视图过拟合的固有问题,论文采用未观测(伪)视图增强来整合更多从2D先验模型中派生的场景内的先验知识。合成的视图是从欧几里得空间中两个最接近的训练视图中采样得到的,计算平均相机方向并在它们之间插值一个虚拟的相机位置。随机噪声被应用到3自由度(3DoF)相机位置,然后渲染图像。
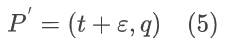
其中t ϵ P 表示相机位置,而q是一个四元数,代表从两个相机中平均得到的旋转。这种在线合成伪视图的方法使得动态几何更新成为可能,因为3D高斯将会逐步更新,降低了过拟合的风险。
损失函数

实验
实验设置
论文的实验分别用了三个数据集:LLFF,Mip-NeRF360和blender。对于LLFF数据集,选择三个视角进行训练。对于Mip-NeRF360数据集,选择24个视角进行训练。对于blender数据集,选择8个视角进行训练。
论文在这三个数据集上比较了FSGS与几种稀疏视角新视角合成(NVS)方法,包括DietNeRF、RegNeRF、FreeNeRF和SparseNeRF。此外还包括了与高性能的基于MLP的NeRF——Mip-NeRF的比较,它主要是为密集视角训练设计的,以及基于点的3D-GS,遵循其原始的密集视角训练配方。论文报告了所有方法的平均PSNR、SSIM、LPIPS分数和FPS。
实施细节
论文使用PyTorch框架实现了FSGS,初始相机姿态和点云是基于指定数量的训练视图,通过SfM计算得到的。在优化过程中,每100次迭代对高斯进行一次密集化,并在500次迭代后执行密集化。所有数据集的总迭代次数为10000次,大约需要在Blender和LLFF数据集上训练9.5分钟,以及在Mip-NeRF360数据集上训练约24分钟。论文将邻近阈值tprox设置为10,并且在2000次迭代后采样伪视图,σ设置为0.1。我们利用预训练的Dense Prediction Transformer (DPT)模型进行零拍摄单目深度估计。所有结果都是使用NVIDIA A6000 GPU获得的。
实验结果
LLFF数据集

从图中的红色框内场景的视觉效果上看,FSGS的效果要明显优于其他几种方法。
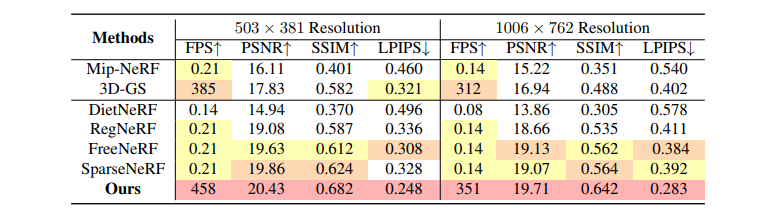
从实验指标上分析,FSGS无论是在渲染图像的质量上,还是在渲染速度上,均要优于其他几种方法,在四个指标上都是最优的。
Mip-NeRF360数据集

从图中的红色框内场景的视觉效果上看,FSGS的效果要明显优于其他几种方法。
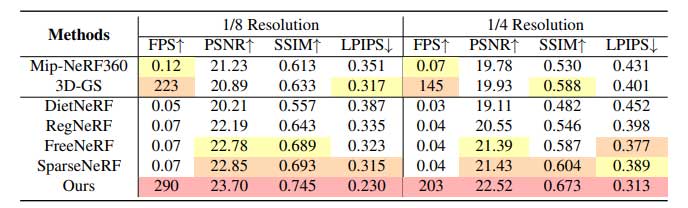
从实验指标上分析,FSGS无论是在渲染图像的质量上,还是在渲染速度上,均要优于其他几种方法,在四个指标上都是最优的。
Blender数据集
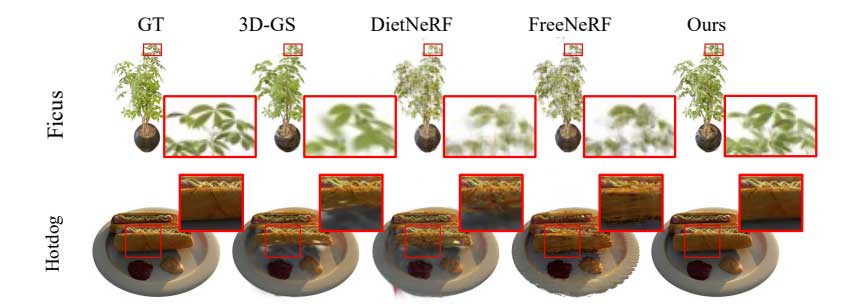
从图中的红色框内场景的视觉效果上看,FSGS的效果要明显优于其他几种方法。
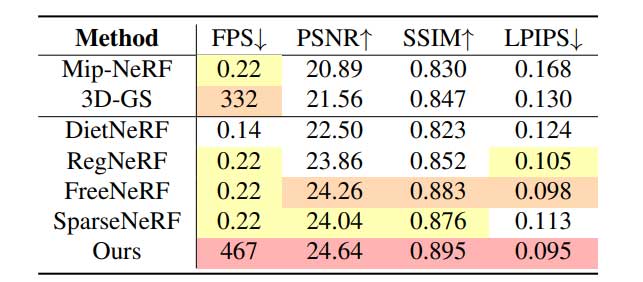
从实验指标上分析,FSGS无论是在渲染图像的质量上,还是在渲染速度上,均要优于其他几种方法,在四个指标上都是最优的。
消融实验
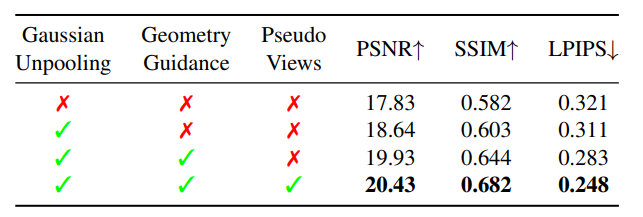
可以看到,高斯上池化,几何引导和为视角采样三个模块对最终结果都有着重要作用,去除其中部分模块都会让实验结果变差。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。